


판다스
- 판다스(pandas) : 파이썬의 데이터 분석 라이브러리로 데이터 테이블을 다룸
- 인덱싱, 연산, 전처리 등의 다양한 함수를 제공하기 때문에, 넘파이를 효율적으로 활용할 수 있음
- 데이터프레임(DataFrame) : 데이터 테이블 전체를 가리키는 객체로 열과 행 각각 사용해 하나의 데이터 접근
- 시리즈(Series) : 피쳐 벡터와 같은 개념으로 데이터, 인덱스, 데이터 타입으로 구성되는 객체
시리즈 객체와 인덱스
- 시리즈 객체는 넘파이 배열의 하위 클래스
- 넘파이가 지원하는 데이터 타입 모두 지원
- 인덱스와 반드시 정렬되어 있을 필요 없음
- 인덱스 값은 중복 허용
- 인덱스 값을 기준으로 객체 생성되며, 기존 데이터에 인덱스 값이 추가되면 NaN 값 발생
import pandas as pd
import numpy as np
from pandas import Series
list_data = [1, 2, 3, 4, 5]
list_name = ["a", "b", "c", "d", "e"]
example = Series(data=list_data, index=list_name, dtype=np.int64)
example.name = "series name" # 시리즈 객체(열) 이름 설정
example.index.name = "index" # 인덱스 이름 설정
example, example.index, example.values, type(example.values)
출력 결과 :
(index
a 1
b 2
c 3
d 4
e 5
Name: series name, dtype: int64,
Index(['a', 'b', 'c', 'd', 'e'], dtype='object', name='index'),
array([1, 2, 3, 4, 5], dtype=int64),
numpy.ndarray)
파일을 데이터프레임으로 읽기
- read_csv, read_excel : csv, excel 파일 읽어오기
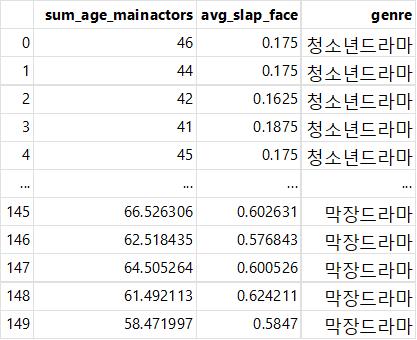
pd.read_csv("../Data/ch04/drama_genre.csv", encoding="ansi")
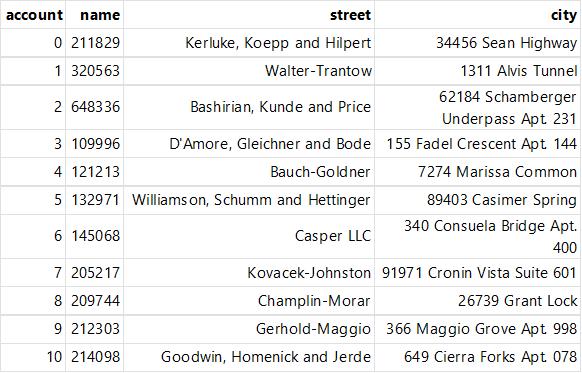
pd.read_excel("../Data/ch04/excel-comp-data.xlsx")
- 데이터프레임 직접 생성 : 시리즈를 먼저 만들어준 뒤 pd.DataFrame()을 통해 생성
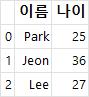
raw_data = {'이름': ['Park', 'Jeon', 'Lee'],
'나이': [25, 36, 27]}
df = pd.DataFrame(raw_data, columns=['이름', '나이']) # 이름, 나이 열을 가져온 데이터프레임 생성
df # 데이터가 존재하지 않는 열인 경우 NaN 값으로 추가
데이터 추출
- head(), tail() : 처음 n개 행이나 마지막 n개 행 추출, 기본값 5
df = pd.read_excel("../Data/ch04/excel-comp-data.xlsx")
df.head(3)

df.tail(4)

# df 열을 선택해 출력 (시리즈 [] / 데이터프레임 [[,]])
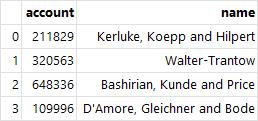
df[["account", "name"]].head(4) # 선택할 열이 여러 개일 경우 데이터프레임으로 묶는다.
df[:2] # 인덱스 번호로 행 추출

df["name"][:2] # 이름 열의 2번째 행까지 추출
출력 결과 :
0 Kerluke, Koepp and Hilpert
1 Walter-Trantow
Name: name, dtype: object
- loc[] : 인덱스 이름과 열 이름을 데이터 추출
df.index = df["account"] # index값을 account열로 설정
del df["account"] # 인덱스를 제외한 account열 삭제
df
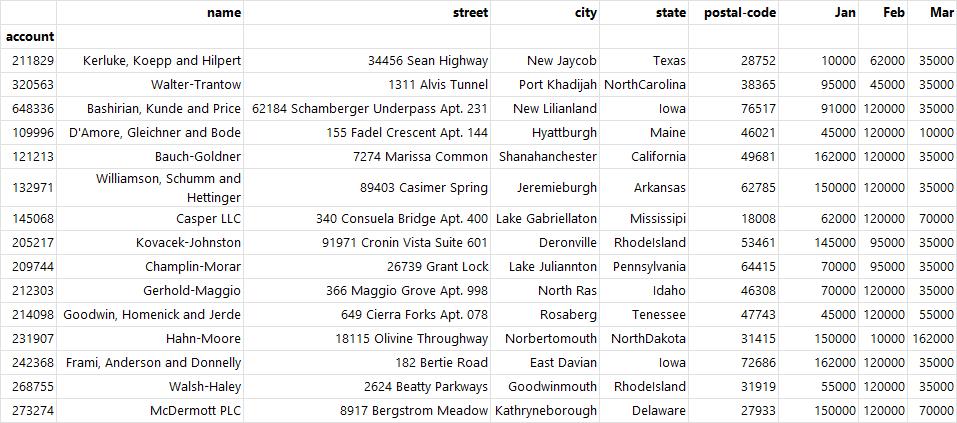
df.loc[[231907, 268755], ["name"]] # 인덱스 이름 231907, 268755의 이름 열 출력
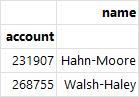
df.loc[214098:, ["name"]] # 인덱스 이름 648336부터 끝까지의 이름 열 출력
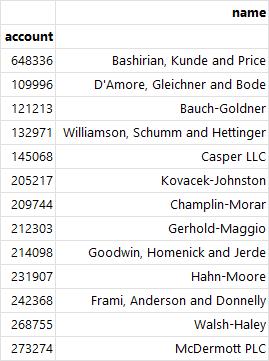
- iloc[] : 인덱스 번호로만 데이터 추출
df.iloc[:10, :3] # 처음부터 10개 행과 3개 열 추출
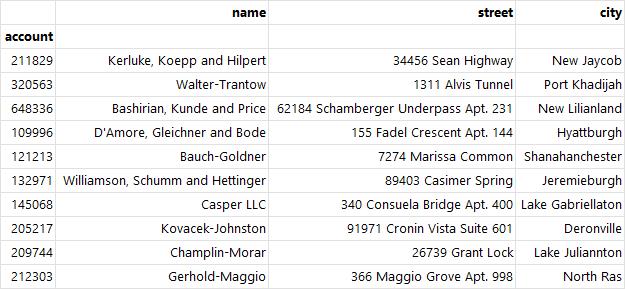
df = df.reset_index() # 인덱스 리셋
df # 기존의 df으로 출력됨
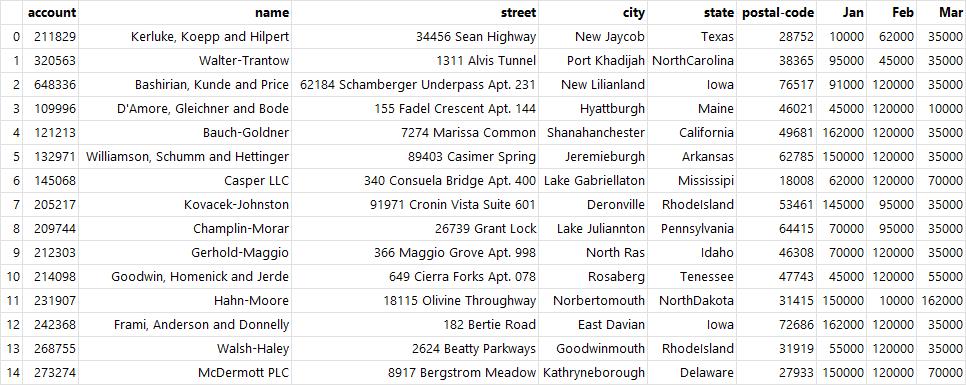
- drop() : 특정 열이나 행을 삭제한 객체 반환
df.drop(0) # index가 0인 행 삭제
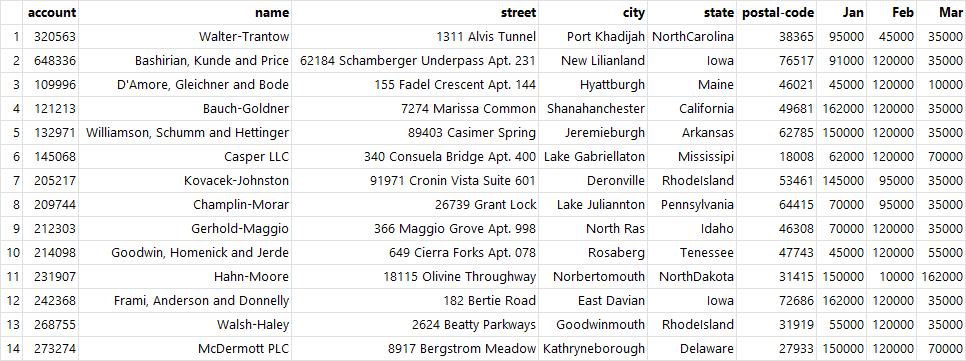
df.drop("name", axis=1) # name 열 삭제
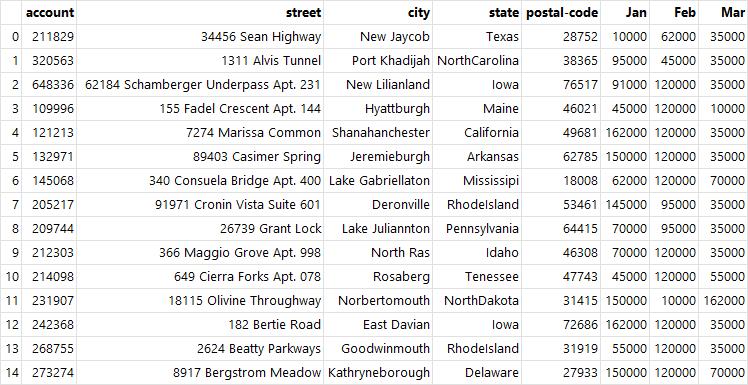
df.drop(1, inplace=True) # 삭제한 상태로 df에 반환
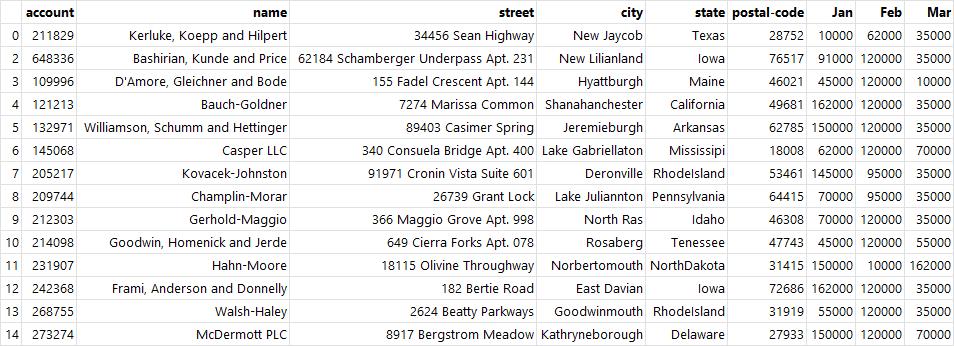
그룹별 집계
- 그룹별 집계(groupby) : 데이터로부터 동일한 객체를 가진 데이터만 따로 뽑아 기술통계 데이터를 추출
- 그룹별 집계는 분할->적용->결합 과정을 거치는 함수
- 분할(split) : 같은 종류 데이터끼리 나누는 기능(groupby('Team'))
- 적용(apply) : 데이터 블록마다 sum, count, mean 등 연산 적용(sum(), mean())
- 결합(combine) : 연산 함수가 적용된 각 블록들을 합침(groupby('Team')['Points'].sum())
단일 인덱스
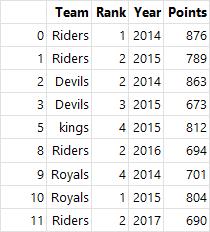
# DataFrame 생성
ipl_data = {
'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals',
'Riders'],
'Rank': [1, 2, 2, 3, 3, 4, 1, 1, 2, 4, 1, 2],
'Year': [2014, 2015, 2014, 2015, 2014, 2015, 2016, 2017, 2016, 2014, 2015, 2017],
'Points': [876, 789, 863, 673, 741, 812, 756, 788, 694, 701, 804, 690]}
df = pd.DataFrame(ipl_data)
df
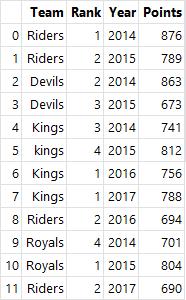
# df.groupby(묶음 기준 열)[묶는 열].적용받는 연산
df.groupby("Team")["Points"].sum()
출력 결과 :
Team
Devils 1536
Kings 2285
Riders 3049
Royals 1505
kings 812
Name: Points, dtype: int64
멀티 인덱스
- 멀티 인덱스 : 한 개 이상의 열
- 한 개 이상의 열을 기준으로 그룹별 집계를 실행
- 계층적 인덱스(hierarchical index) 형태로, 리스트를 사용하여 여러 개의 열 이름을 기준으로 넣으면 여러 열이 키 값이 되어 결과 출력
multi_groupby = df.groupby(["Team", "Year"])["Points"].sum()
multi_groupby
출력 결과 :
Team Year
Devils 2014 863
2015 673
Kings 2014 741
2016 756
2017 788
Riders 2014 876
2015 789
2016 694
2017 690
Royals 2014 701
2015 804
kings 2015 812
Name: Points, dtype: int64
# 멀티 인덱스의 인덱스 열은 두 개
multi_groupby.index
출력 결과 :
MultiIndex([('Devils', 2014),
('Devils', 2015),
( 'Kings', 2014),
( 'Kings', 2016),
( 'Kings', 2017),
('Riders', 2014),
('Riders', 2015),
('Riders', 2016),
('Riders', 2017),
('Royals', 2014),
('Royals', 2015),
( 'kings', 2015)],
names=['Team', 'Year'])
# 인덱스 Devil에서 Kings까지 출력
multi_groupby["Devils":"Kings"]
출력 결과 :
Team Year
Devils 2014 863
2015 673
Kings 2014 741
2016 756
2017 788
Name: Points, dtype: int64
- unstack() : 기존 인덱스를 기준으로 묶인 데이터에서 두 번째 인덱스를 열로 변화
multi_groupby.unstack()
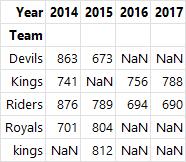
- swaplevel() : 인덱스 간 레벨을 변경(Team <-> Year)
- sort_index() : 첫 번째 인덱스를 기준으로 데이터 재정렬
multi_groupby.swaplevel().sort_index()
출력 결과 :
Year Team
2014 Devils 863
Kings 741
Riders 876
Royals 701
2015 Devils 673
Riders 789
Royals 804
kings 812
2016 Kings 756
Riders 694
2017 Kings 788
Riders 690
Name: Points, dtype: int64
그룹화된 상태
- 그룹화된(grouped) 상태 : 분할->적용->결합 중 분할까지만 이루어진 상태
- 그룹화된 상태에서 적용 단계 함수 : 집계(aggregation), 변환(transformation), 필터(filter)
- get_group() : 해당 키 값을 기준으로 분할된 데이터프레임 객체를 확인하는 함수
# 키 값을 기준으로 분할된 데이터프레임 객체 확인
grouped = df.groupby("Team")
grouped.get_group("Riders")
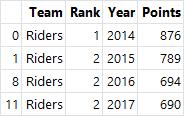
grouped.get_group("Kings")
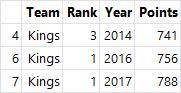
grouped.get_group("Devils")
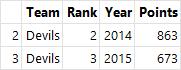
grouped.get_group("Royals")
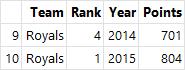
grouped.get_group("kings")
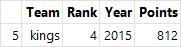
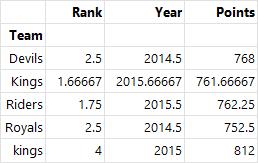
- agg() : 집계, 요약된 통계 정보를 추출
grouped.agg(min) # 최솟값으로 집계
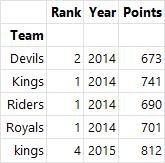
grouped.agg(np.mean) # 평균으로 집계
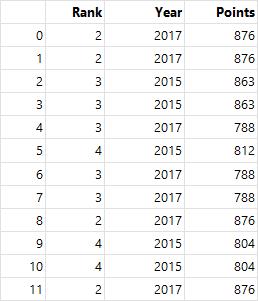
- transform() : 변환, 개별 데이터 변환 지원하며, 그룹화된 상태 값으로 적용
grouped.transform(max) # 각 데이터를 최댓값으로 변환
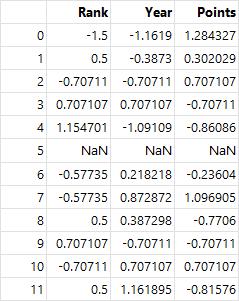
# std() : 표준편차
score = lambda x: (x - x.mean()) / x.std()
grouped.transform(score)
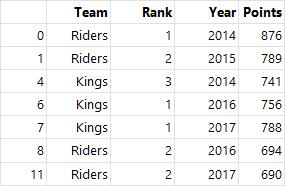
- filter() : 필터, 특정 조건으로 데이터를 검색
df.groupby('Team').filter(lambda x: len(x) >= 3) # 같은 Team 값을 가진 행이 3개 이상
# 최대값이 800 이하인 Kings를 제외한 내용 출력
df.groupby('Team').filter(lambda x: x["Points"].max() > 800)
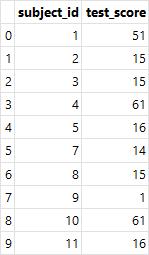
병합
- merge() : 두 개의 데이터를 특정 기준으로 병합
raw_data = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_score': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
df_left = pd.DataFrame(raw_data, columns=['subject_id', 'test_score'])
df_left
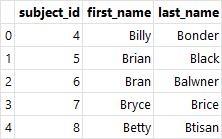
raw_data = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
df_right = pd.DataFrame(
raw_data, columns=['subject_id', 'first_name', 'last_name'])
df_right
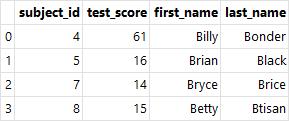
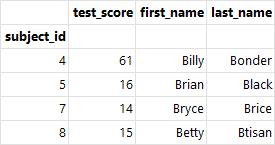
- 내부 조인(inner join) : 키 값을 기준으로 두 테이블에 모두 존재하는 키 값의 행끼리 병합(how="inner")
pd.merge(left=df_left, right=df_right,
how="inner", on='subject_id')
# 왼쪽 테이블과 오른쪽 테이블의 키 값이 다른 경우 left_on과 right_on 매개변수를 사용
pd.merge(left=df_left, right=df_right,
left_on='subject_id', right_on='subject_id')
- 왼쪽 조인(left join) : 왼쪽 테이블 값 기준으로 같은 키 값을 갖고 있는 행끼리 병합
- 오른쪽 조인(right join) : 오른쪽 테이블 값 기준으로 같은 키 값을 갖고 있는 행끼리 병합
# 왼쪽 조인(how="left")
pd.merge(df_left, df_right,
how='left', on='subject_id')
# 오른쪽 조인(how="right")
pd.merge(df_left, df_right,
how='right', on='subject_id')
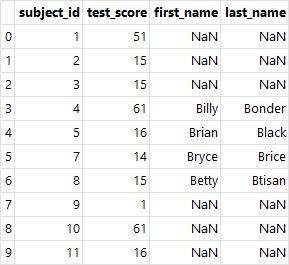
- 완전 조인(outer join) : 두 테이블의 모든 행 병합(how="outer")
# 완전 조인(how="outer")
pd.merge(df_left, df_right,
on='subject_id', how='outer')
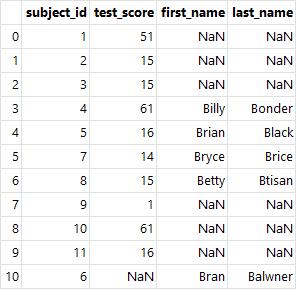
# 인덱스 값을 키 값으로 병합
df_left.index = df_left.subject_id
del df_left["subject_id"] # 왼쪽 테이블 인덱스 지정
df_right.index = df_right.subject_id
del df_right["subject_id"] # 오른쪽 테이블 인덱스 지정
pd.merge(df_left, df_right, on='subject_id', how='inner') # 인덱스 값에 대한 내부 조인
연결
- 연결(concatenate) : 두 테이블을 그대로 붙임
- 데이터의 스키마가 동일할 때 그대로 연결하며, 주로 세로로 데이터를 연결
- concat() : 두 개의 서로 다른 테이블을 하나로 합치며, 두 개 이상 데이터프레임을 합칠 때 좋음
import os
filenames = [os.path.join("../Data/ch04", filename)
for filename in os.listdir("../Data/ch04") if "sales" in filename]
# 3개의 엑셀을 df_list로 만듦
df_list = [pd.read_excel(filename, engine="openpyxl")
for filename in filenames]
for df in df_list:
print(type(df), len(df))
출력 결과 :
<class 'pandas.core.frame.DataFrame'> 108
<class 'pandas.core.frame.DataFrame'> 134
<class 'pandas.core.frame.DataFrame'> 142
# concat을 통한 리스트 연결
df = pd.concat(df_list, axis=0)
df.reset_index(drop=True) # 중복된 인덱스 제거
참고문헌
최성철, 『데이터 과학을 위한 파이썬 머신러닝』, 초판, 한빛아카데미, 2022