


맷플롯립
- 데이터 시각화(Data Visualization) : 데이터 분석 결과를 시각적으로 전달
- matplotlib : matlab 기능을 파이썬에서 사용하도록 만든 시각화 모듈
파이플롯
- pyplot : matplotlib을 이용할 때 가장 기본이 되는 객체
- 바탕으로 그림(figure) 객체를 올리고 그 위로 그래프에 해당하는 축(axes)을 올림
- 축을 여러 장 올리면 여러 개의 그래프를 만들 수 있음
import matplotlib.pyplot as plt # matplotlib 모듈 호출
X = range(100)
Y = range(100)
plt.plot(X, Y)
import numpy as np # numpy 모듈 호출
X_1 = range(100)
Y_1 = [np.cos(value) for value in X_1]
X_2 = range(100)
Y_2 = [np.sin(value) for value in X_1]
# pyplot 객체 내부에 cos과 sin 그래프를 그림
plt.plot(X_1, Y_1)
plt.plot(X_2, Y_2)
plt.show() # 그래프 출력
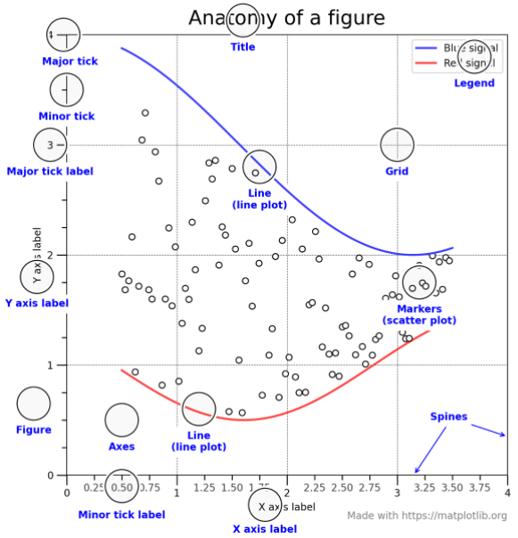
그림과 축
- figure(그림, fig) : 그래프를 작성하는 밑바탕
- axes(축, ax) : 그래프를 그리는 공간
fig, ax = plt.subplots() # figure와 axes 객체 할당
X_1 = range(100)
Y_1 = [np.cos(value)
for value in X_1]
ax.plot(X_1, Y_1) # plot 함수를 사용하여 그래프 생성
ax.set(title='cos graph', # 그래프 제목, X축 라벨, Y축 라벨 설정
xlabel='X',
ylabel='Y')
plt.show()
fig = plt.figure() # figure 반환
fig.set_size_inches(10, 10) # figure의 크기 지정
# 두 개의 그래프 생성
ax_1 = fig.add_subplot(1, 2, 1)
ax_2 = fig.add_subplot(1, 2, 2)
# 두 개의 그래프 설정
ax_1.plot(X_1, Y_1, c="b")
ax_2.plot(X_2, Y_2, c="g")
plt.show()
서브플롯
- 축을 여러 개 만들 때 서브플롯으로 공간 확보
- plt.subplots() : plot 객체에서 서브플롯 공간 생성
fig, ax = plt.subplots(nrows=1, ncols=2) # nrows : 행, ncols : 열
print(ax)
print(type(ax)) # ax의 축 객체가 넘파이 배열 타입으로 되어있음
- 서브플롯 그래프 생성 방법
- figure 객체 생성 후 축에 대한 행, 열 접근을 통한 그래프 생성
- plt.subplot(행, 열, 순서)를 통한 그래프 생성
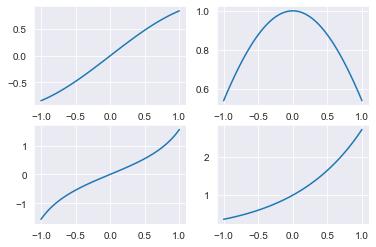
# np.linspace(시작점, 끝점, 구간 내 숫자 개수)
x = np.linspace(-1, 1, 100) # x 값과 y_n 값 생성
y_1 = np.sin(x)
y_2 = np.cos(x)
y_3 = np.tan(x)
y_4 = np.exp(x)
# 2행 2열 figure 객체를 생성
fig, ax = plt.subplots(2, 2)
# ax[헹, 열]에 그래프 생성
ax[0, 0].plot(x, y_1)
ax[0, 1].plot(x, y_2)
ax[1, 0].plot(x, y_3)
ax[1, 1].plot(x, y_4)
plt.show()
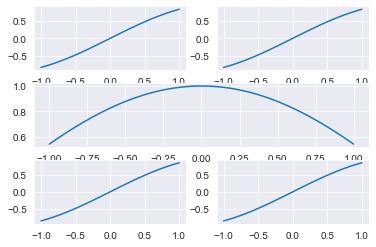
# 행_열로 이루어진 공간에 순서 번째에 대한 그래프 생성
ax1 = plt.subplot(321)
plt.plot(x, y_1)
ax2 = plt.subplot(322)
plt.plot(x, y_1)
ax3 = plt.subplot(312)
plt.plot(x, y_2)
ax4 = plt.subplot(325)
plt.plot(x, y_1)
ax5 = plt.subplot(326)
plt.plot(x, y_1)
plt.show()
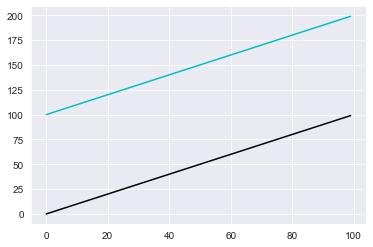
matplotlib 색상
- color 또는 c 매개변수로 색상 변경 : #RGB 값을 입력하거나 약어를 통해 색상 표현


X_1 = range(100)
Y_1 = [value for value in X]
X_2 = range(100)
Y_2 = [value + 100 for value in X]
# 색상 설정
plt.plot(X_1, Y_1, color="#000000") # 검정색
plt.plot(X_2, Y_2, c="c") # 청록색
plt.show()
matplotlib 선의 형태
- linestyle 또는 ls로 선의 형태 정의
- solid : 실선 형태
- dashed : 절취선 형태
- dotted : 점선 형태
- dash-dot : 절취선+점선 형태
plt.plot(X_1, Y_1, c="b",
linestyle="dashed") # 절취선
plt.plot(X_2, Y_2, c="r",
ls="dotted") # 점선
plt.show()
matplotlib figure 구조
plt.plot(X_1, Y_1,
color="b",
linestyle="dashed",
label='line_1')
plt.plot(X_2, Y_2,
color="r",
linestyle="dotted",
label='line_2')
plt.legend( # 범례 설정
shadow=True, # 그림자 효과
fancybox=False,
loc="upper right") # 범례 위치, best로 지정 시 적절한 위치에 놓임
plt.title('$y = ax+b$') # 그래프 제목
plt.xlabel('$x_line$') # x축 라벨 이름
plt.ylabel('y_line') # y축 라벨 이름
Text(0, 0.5, 'y_line')
맷플롯립 그래프 종류
- 산점도(scatter plot) : 데이터 분포를 2차원 평면에 표현
data_1 = np.random.rand(512, 2)
data_2 = np.random.rand(512, 2)
# scatter(표시할 데이터, c="포인트 색상", marker="포인트 모양", size=포인트 크기, alpha=포인트 불투명도)
plt.scatter(data_1[:, 0],
data_1[:, 1],
c="b", marker="x")
plt.scatter(data_2[:, 0],
data_2[:, 1],
c="r", marker="o")
plt.show()
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N) # 색깔도 랜덤 설정
area = np.pi * ( # 원 크기 랜덤 설정
15 * np.random.rand(N)) ** 2
plt.scatter(x, y,
s=area, c=colors,
alpha=0.5)
plt.show()
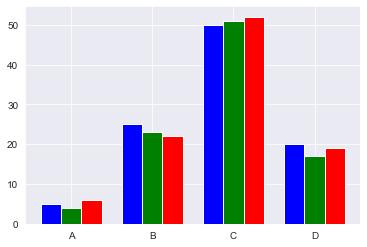
- 막대 그래프(bar graph) : 데이터의 개수나 크기를 비교
data = [[5., 25., 50., 20.],
[4., 23., 51., 17],
[6., 22., 52., 19]]
# X 좌표 시작점
X = np.arange(0, 8, 2) # array([0, 2, 4, 6])
# 3개의 막대 그래프 생성
plt.bar(X + 0.00, data[0], color='b', width=0.50)
plt.bar(X + 0.50, data[1], color='g', width=0.50)
plt.bar(X + 1.0, data[2], color='r', width=0.50)
# X축에 표시될 이름과 위치 설정
plt.xticks(X + 0.50, ("A", "B", "C", "D"))
# 막대 그래프 출력
plt.show()
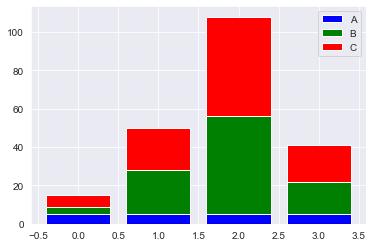
- 누적 막대 그래프(stacked bar graph) : 데이터를 밑에서부터 쌓아올려 데이터를 표현
data = np.array([[5., 25., 50., 20.],
[4., 23., 51., 17],
[6., 22., 52., 19]])
color_list = ['b', 'g', 'r']
data_label = ["A", "B", "C"]
X = np.arange(data.shape[1])
data = np.array([[5., 5., 5., 5.],
[4., 23., 51., 17],
[6., 22., 52., 19]])
# for문을 통해 누적 막대 그래프 생성
for i in range(3):
plt.bar(X, data[i],
bottom=np.sum(data[:i], axis=0),
color=color_list[i],
label=data_label[i])
plt.legend()
plt.show()
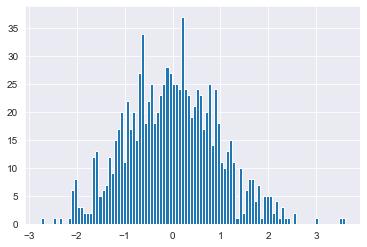
- 히스토그램(histogram) : 데이터의 분포를 표현
N = 1000
X = np.random.normal(size=N)
# hist(표시할 데이터, bins=막대 개수)
plt.hist(X, bins=100)
plt.show()
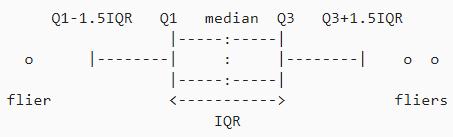
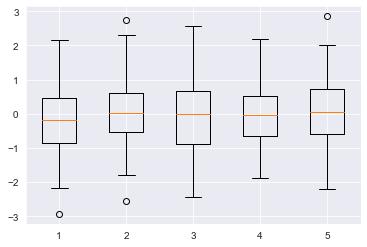
- 상자그림(boxplot) : 사분위수를 시각화하여 데이터의 분포와 밀집 정도를 표현

- 데이터를 작은 데이터부터 큰 데이터까지 정렬
- Q1(25%)부터 Q3(75%)까지 박스 형태로 위치시킴
- IQR(InterQuatile Range) : Q1 - Q3
- Q1 - 1.5×IQR 을 하단 값으로, Q3 + 1.5×IQR 을 상단 값으로 설정
- 이상치(outlier) : 상단 값과 하단 값을 넘어가는 값들
data = np.random.randn(100, 5)
plt.boxplot(data)
plt.show()
시본
- seaborn : 맷플롯립을 바탕으로 다양한 함수 사용을 돕는 wrapper 모듈
- 맷플롯립과 동일한 결과물이 나오며, 작성 과정이 간단함
- 그림 객체나 축 객체 같은 개념이 없음
- xticks 설정하지 않아도 각 축에 라벨 자동으로 생성
- 데이터프레임과 x, y에 해당하는 열 이름만 지정해 생성
import seaborn as sns # seaborn 모듈 호출
# fmri 데이터셋 : 환자별(subject) 시가점마다의 fmri signal 값을 담고 있는 데이터
fmri = sns.load_dataset("fmri")
fmri.head()
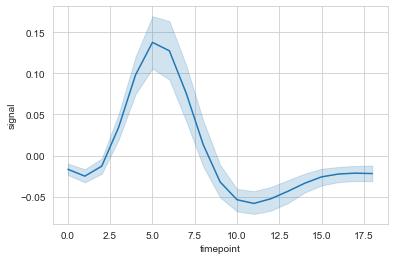
fmri 데이터는 연속형 값 외에도 다양한 범주형 값 가지기 때문에 matplotlib으로 표현하기는 상당히 복잡하고, seaborn은 hue 매개변수만 추가하면 그래프를 그릴 수 있음
sns.set_style("whitegrid") # 기본 스타일 적용
sns.lineplot(x="timepoint", y="signal", data=fmri) # 선 그래프 작성
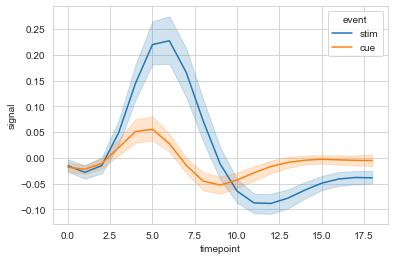
fmri.sample(n=10, random_state=1)
sns.lineplot(x="timepoint", y="signal", hue="event", data=fmri)
시본 그래프 종류
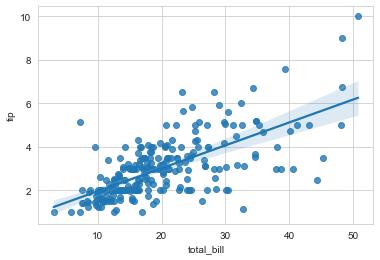
- 회귀 그래프(regression plot) : 회귀식을 적용해 선형회귀 추세선을 그래프에 함께 작성
- 선형회귀 추세선 : 데이터를 기반으로 데이터의 x값 대비 y값 변화를 예측하는 직선
# tips 데이터셋 : 레스토랑에 방문한 손님이 팁을 얼마나 주는지에 대한 정보를 담고 있는 데이터
tips = sns.load_dataset("tips")
# regplot : 회귀 그래프 함수
sns.regplot(x="total_bill", y="tip", data=tips, x_ci=95) # x_ci는 신뢰구간의 비율
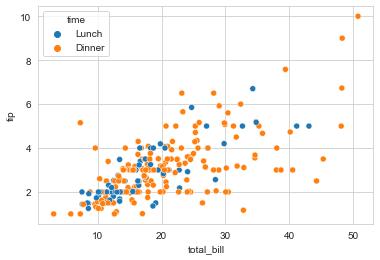
- 산점도(scatter plot) : x, y를 기준으로 데이터 분포 표현
# scatterplot : 산점도 함수
tips = sns.load_dataset("tips")
sns.scatterplot(x="total_bill", y="tip", hue="time", data=tips)
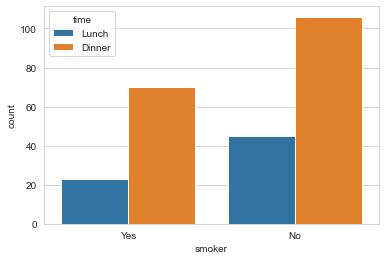
- 비교 그래프(counter plot) : 범주형 데이터의 항목별 개수
# countplot : 비교 그래프 함수
tips = sns.load_dataset("tips")
sns.countplot(x="smoker", hue="time", data=tips)
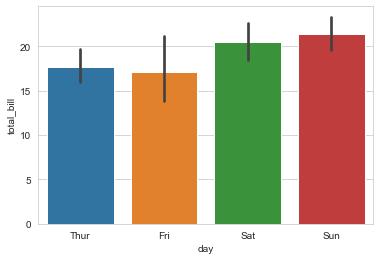
- 막대 그래프 : y 값이 연속형 값일 경우 해당 값들의 평균을 나타냄
- 데이터의 신뢰구간을 검은색 막대로 표현
# barplot : 막대 그래프 함수
sns.barplot(x="day", y="total_bill", data=tips)
사전 정의된 그래프
맷플롯립 관점에서 여러 그래프들을 합쳐 정보를 추출한 그래프로 범주형 데이터에 유용함
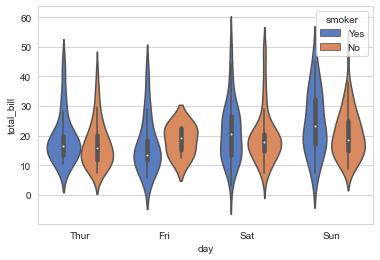
바이올린 플롯(Violin Plot) : 분포를 나타내는 그래프로, 상자그림과 분포도를 한 번에 나타낼 수 있음
- x축에는 범주형 데이터, y축에는 연속형 데이터
# violinplot : 바이올린 플롯 함수
sns.violinplot(x="day", y="total_bill", hue="smoker",
data=tips, palette="muted")
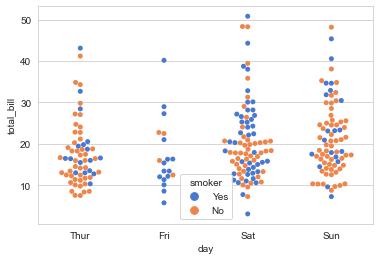
- 스웜 플롯(swarm plot) : 분포를 나타내는 그래프로, 산점도로 데이터 분포를 나타냄
- 매개변수 hue로 두 개 이상의 범주형 데이터를 점이 겹치지 않게 정리해, 영역별 데이터 양을 직관적으로 보여줌
# swarmplot : 스웜 플롯 함수
sns.swarmplot(x="day", y="total_bill", hue="smoker",
data=tips, palette="muted")
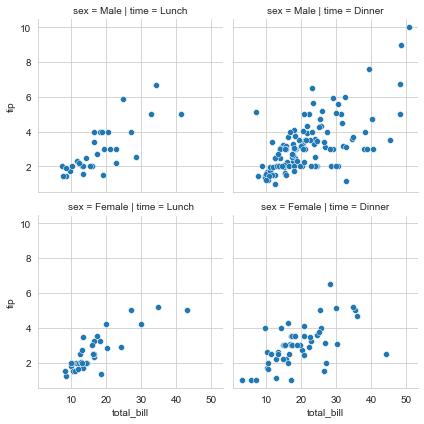
- 패싯그리드(FacetGrid) : 다양한 범주형 데이터를 나타내는 그래프로, 그래프의 틀만 제공하여 적당한 그래프를 그려주는 클래스
- 그리드가 생성된 후 맵(map)을 사용하여 그래프 만듦
- 각 FacetGrid에 있는 개별 그래프 영역에 그래프를 집어넣는 구조
- 전체 데이터를 범주형 데이터의 다양한 관점에서 나눠서 볼 수 있음
# FacetGrid : 패싯그리드 함수
g = sns.FacetGrid(tips,
col="time",
row="sex")
g.map(sns.scatterplot,
"total_bill", "tip")
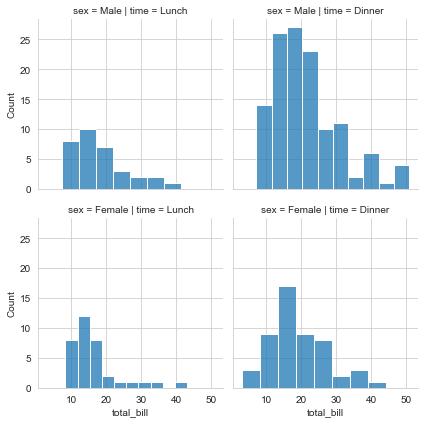
g = sns.FacetGrid(tips, col="time",
row="sex")
g.map_dataframe(sns.histplot,
x="total_bill")
플롯리
- plotly : 비즈니스 인텔리전스(Business Intelligence) 대시보드로 개발된 도구
- 비즈니스 인텔리전스(BI 도구) : 사내 여러 데이터들을 정리하여 의사 결정을 도움
- 애플리케이션으로, 사용자에게 그래프를 제공
- 맷플롯립이나 시본은 데이터 분석가들이 데이터의 형태나 분포를 살피기 위해 코드로 사용하는 도구
- 인터랙션 그래프 : 그래프 생성 이후 사용자가 마우스 커서를 올리면 데이터를 볼 수 있으며, 인터페이스를 통해 조절 가능
import plotly.express as px
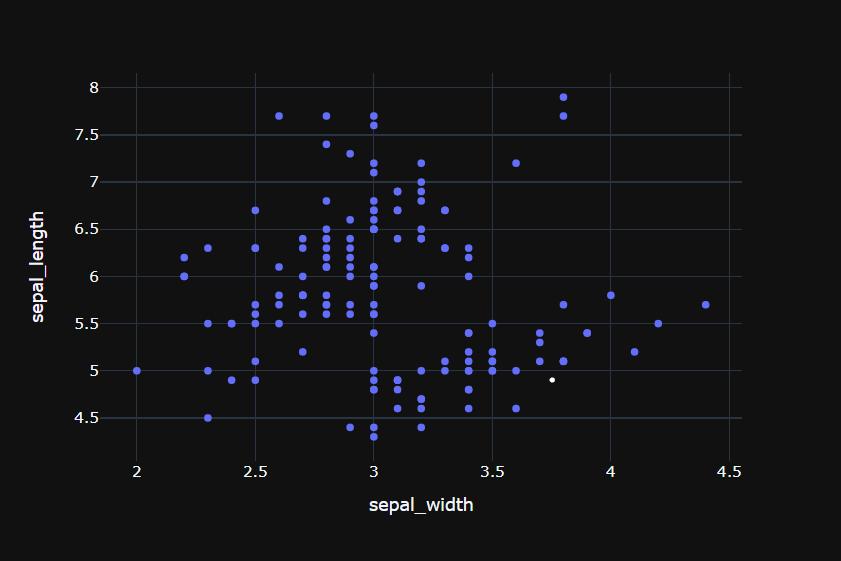
df = px.data.iris() # iris : 판다스 데이터프레임 데이터셋
fig = px.scatter(df, x="sepal_width", y="sepal_length")
fig.show()
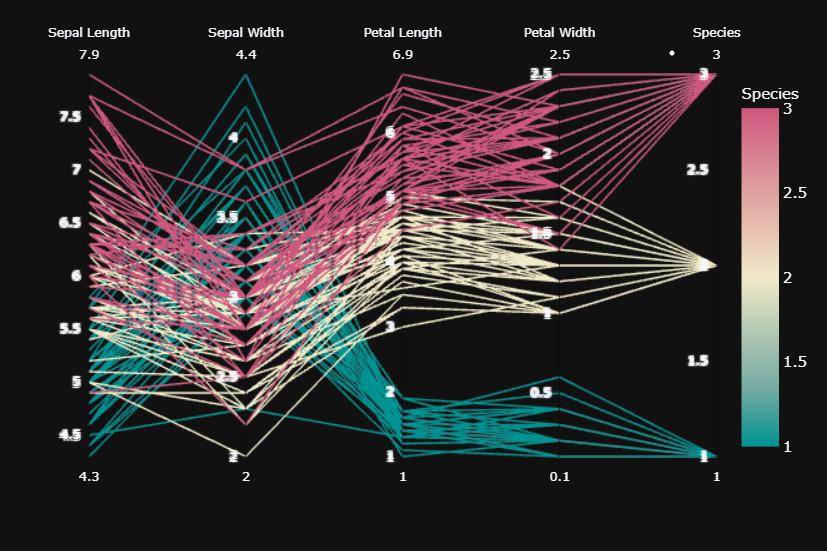
- 좌표 그래프(coordinates plot) : 데이터 간 관계를 표현
fig = px.parallel_coordinates(
df, color="species_id",
labels={"species_id": "Species",
"sepal_width": "Sepal Width",
"sepal_length": "Sepal Length",
"petal_width": "Petal Width",
"petal_length": "Petal Length", },
color_continuous_scale=px.colors.diverging.Tealrose,
color_continuous_midpoint=2)
fig.show()
참고문헌
최성철, 『데이터 과학을 위한 파이썬 머신러닝』, 초판, 한빛아카데미, 2022