


데이터 전처리 개념과 유형
- 데이터 전처리(data preprocessing) : 머신러닝 모델에 훈련 데이터를 입력하기 전에 데이터를 가공
- 머신러닝 기초 수식 : y=f(X)
- 데이터 X는 훈련 데이터(train data)와 테스트 데이터(test data)가 모두 같은 구조를 갖는 피쳐(feature)이고, X값을 넣으면 y값이 나옴
- 연속형 데이터 : 최댓값과 최솟값 차이가 피쳐보다 더 많이 나는 경우, 학습에 영향을 최소화 하기 위해 데이터의 스케일(scale)을 맞춰줌
- 기수형 데이터와 서수형 데이터 : 일반적으로 숫자로 표현되지 않기 때문에 컴퓨터가 이해할 수 있는 숫자 형태의 정보로 변형
- 결측치(missing data) : 실제로 존재하지만 데이터베이스 등에 기록되지 않는 데이터
- 해당 데이터를 빼고 모델을 돌릴 수 없기 때문에 결측치 처리 전략을 세워 데이터를 채워 넣음
- 이상치(outlier) : 극단적으로 크거나 작은 값
- 단순히 데이터 분포의 차이와는 다르며, 데이터 오기입이나 특이 현상 때문에 나타남
데이터 전처리 전략
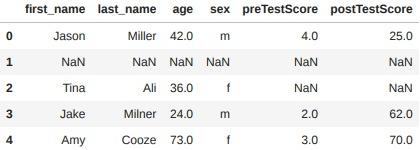
isnull() : NaN 값이 존재할 경우 True, 그렇지 않을 경우 False 출력
df.isnull().sum() / len(df) # 결측치 비율
출력 결과 :
first_name 0.2
last_name 0.2
age 0.2
sex 0.2
preTestScore 0.4
postTestScore 0.4
dtype: float64
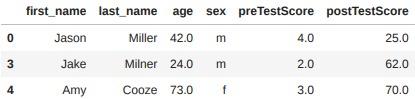
결측치 처리하기 : 드롭
- dropna() : 드롭(drop), 결측치, NaN이 나온 열이나 행을 삭제
- 매개변수 inplace=True를 사용하거나 다른 변수에 재할당하는 것이 좋음
df_no_missing = df.dropna()
df_no_missing
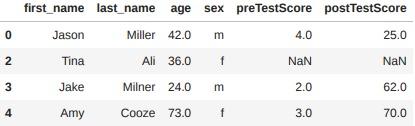
- 매개변수 how로 조건에 따라 결측치가 있는 행 또는 열 제거
- ‘all’ 행에 있는 모든 값이 NaN일 때 해당 행을 삭제
- ‘any’ 하나의 NaN만 있어도 삭제
- 매개변수 thresh로 결측치 아닌 데이터의 개수 조건에 따라 결측치가 있는 행 또는 열 제거
df_cleaned = df.dropna(how='all')
df_cleaned
df.dropna(axis=0, thresh=1)
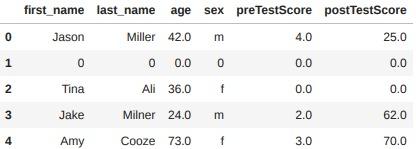
결측치 처리하기 : 채우기
- fillna() : 채우기(fill), 비어있는 값을 채움
- 일반적으로 드롭한 후에 남은 값들을 채우기 처리
- 평균, 최빈값 등 데이터의 분포를 고려해서 채움
df.fillna(0)
# 열 단위 평균값을 계산해 해당 열에만 결측값에 채우는 방식
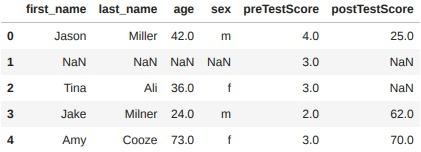
df["preTestScore"].fillna(df["preTestScore"].mean(), inplace=True)
df
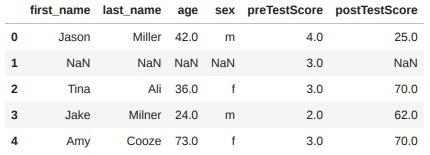
# 성별에 따라 빈칸을 채우는 방식
df["postTestScore"].fillna(
df.groupby("sex")["postTestScore"].transform("mean"),
inplace=True)
df
범주형 데이터 처리 : 원핫인코딩
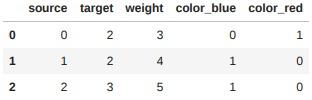
- get_dummies() : 원핫인코딩(one-hot encoding), 범주형 데이터의 개수만큼 가변수(dummy variable)를 생성하여 존재 유무를 1 또는 0으로 표현

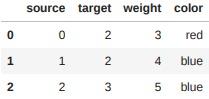
edges.dtypes
출력 결과 :
source int64
target int64
weight int64
color object
dtype: object
pd.get_dummies(edges)
# 열 이름으로 되어있는 접두어가 없는 가변수 생성
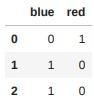
pd.get_dummies(edges["color"])
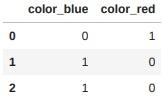
# 열 이름으로 되어있는 접두어가 있는 가변수 생성
pd.get_dummies(edges[["color"]])
# pd.get_dummies(edges).iloc[:, 3:]
# pd.get_dummies(edges[["color"]])
# pd.get_dummies(edges["color"], prefix="color")
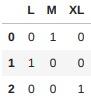
- 필요에 따라 정수형을 객체로 변경해서 처리
weight_dict = {3: "M", 4: "L", 5: "XL"}
edges["weight_sign"] = edges["weight"].map(weight_dict)
weight_sign = pd.get_dummies(edges["weight_sign"])
weight_sign
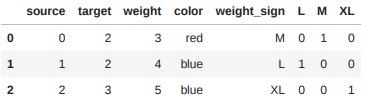
pd.concat([edges, weight_sign], axis=1)
범주형 데이터로 변환 : 바인딩
- cut() : 바인딩(binding), 연속형 데이터를 범주형 데이터로 변환

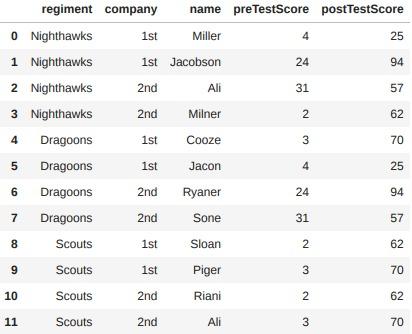
# postTestScore에 대한 학점을 측정하는 코드를 작성
bins = [0, 25, 50, 75, 100] # bins 정의(0-25, 25-50, 60-75, 75-100)
group_names = ['Low', 'Okay', 'Good', 'Great']
# cut : 나눌 시리즈 객체와 구간, 구간의 이름을 넣어주면 해당 값을 바인딩하여 표시해줌
categories = pd.cut(df['postTestScore'], bins, labels=group_names)
categories
출력 결과 :
0 Low
1 Great
2 Good
3 Good
4 Good
5 Low
6 Great
7 Good
8 Good
9 Good
10 Good
11 Good
Name: postTestScore, dtype: category
Categories (4, object): ['Low' < 'Okay' < 'Good' < 'Great']
피쳐 스케일링
- 스케일링(scaling) : 데이터 간 범위를 맞춤
- 최솟값-최댓값 정규화(min-max normalization) : 최솟값과 최댓값을 기준으로 0에서 1, 또는 0에서 지정 값까지로 값의 크기를 변화시킴

- x는 처리하고자하는 열, x_i는 열 하나의 값
- max(x)는 해당 열의 최댓값, min(x)는 해당 열의 최솟값
- new_{max}와 new_{min}은 새롭게 지정되는 값의 최댓값 또는 최솟값
- z-스코어 정규화(z-score normalization) : 기존 값을 표준 정규분포값으로 변환하여 처리

- μ는 x열의 평균값이고 σ는 표준편차

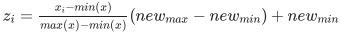
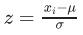
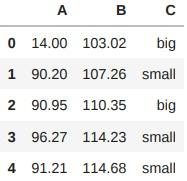
# 스케일링은 브로드캐스팅 개념으로 스칼라 값(평균값, 최댓값, 최솟값)과 벡터(열) 값 간 연산
df["A"] - df["A"].min()
출력 결과 :
0 0.00
1 76.20
2 76.95
3 82.27
4 77.21
Name: A, dtype: float64
# 최솟값-최댓값 정규화 방법에서 최댓값과 최솟값을 따로 구하지 않고 코드로 수식을 나타낼 수 있음
(df["A"] - df["A"].min()) / (df["A"].max() - df["A"].min())
출력 결과 :
0 0.000000
1 0.926219
2 0.935335
3 1.000000
4 0.938495
Name: A, dtype: float64
# z-스코어 정규화 수식 역시 코드로 나타낼 수 있음
(df["B"] - df["B"].mean()) / (df["B"].std())
출력 결과 :
0 -1.405250
1 -0.540230
2 0.090174
3 0.881749
4 0.973556
Name: B, dtype: float64
머신러닝 프로세스와 데이터 전처리
- 데이터를 확보한 후 데이터를 정제 및 전처리
- 학습용과 테스트 데이터를 나눠 학습용 데이터로 학습을 실시
- 학습 결과를 평가 지표와 비교하여 하이퍼 매개변수 변환
- 최종적인 모델 생성하여 테스트 데이터셋으로 성능을 측정
- 모델을 시스템에 배치하여 모델을 작동시킴
참고문헌
최성철, 『데이터 과학을 위한 파이썬 머신러닝』, 초판, 한빛아카데미, 2022