


Intro
조건.
크롤링 조건
- 단국대 공지사항
- 천안
- 공통
분석
분석 할 html 코드 2개
<li>
<div class="top_area">
<div class="write_num">
NO. 3584
</div>
<div class="num_area">
<span class="table_date">
<strong>최종수정</strong>
2020.03.04
</span>
<span class="table_hit"><strong>조회수</strong>
242
</span>
</div>
</div>
<div class="subject">
<a href="http://www.dankook.ac.kr/web/kor/-390?p_p_id=Bbs_WAR_bbsportlet&p_p_lifecycle=0&p_p_state=normal&p_p_mode=view&p_p_col_id=column-2&p_p_col_pos=1&p_p_col_count=2&_Bbs_WAR_bbsportlet_curPage=1&_Bbs_WAR_bbsportlet_action=view_message&_Bbs_WAR_bbsportlet_messageId=714800"> <div class="subject_txt">
[퇴계기념중앙도서관] 도서관 임시 휴관 기간 연장 안내(~3.22)</div>
<div class="ico_area">
<!-- <img src="/bbs-portlet/images/contents/Bbs/board/icon_mobile.gif" alt="mobile" class="ico_mobile"-->
</div>
</a>
</div>
<div class="btm_area">
<span class="table_poster ">
<strong>작성자</strong> 학술정보지원팀
</span>
<span class="table_category">
<strong>분류</strong>
일반 > 죽전
</span>
</div>
</li>크롤링을 할 데이터 중 두번째 게시글이다.
<a href="http://www.dankook.ac.kr/web/kor/-390?p_p_id=Bbs_WAR_bbsportlet&p_p_lifecycle=0&p_p_state=normal&p_p_mode=view&p_p_col_id=column-2&p_p_col_pos=1&p_p_col_count=2&_Bbs_WAR_bbsportlet_curPage=1&_Bbs_WAR_bbsportlet_action=view_message&_Bbs_WAR_bbsportlet_messageId=714800"> <div class="subject_txt">
[퇴계기념중앙도서관] 도서관 임시 휴관 기간 연장 안내(~3.22)</div>
<div class="ico_area">
<!-- <img src="/bbs-portlet/images/contents/Bbs/board/icon_mobile.gif" alt="mobile" class="ico_mobile"-->
</div>
</a>게시글의 제목과 url은 <a>태그만 크롤링해도 된다.
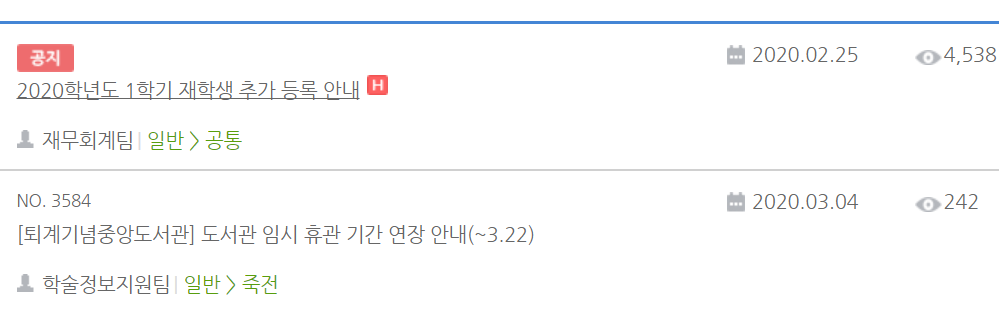
하지만 단국대도 공지라면서 예전에 올린 글을 맨 위에 고정시켜 놓은 글이 있다.
아쉽게도 <a> 태그에서는 어떤 것이 최신 게시글인지, 고정시켜 놓은 글인지 모른다.
그러면 첫 번째 코드블럭과 밑에 코드블럭을 메모장에 복사해보자.
밑에 코드블럭은 맨 위에 고정시켜 놓은 공지글이다.
<li>
<div class="top_area">
<div class="write_num">
<img src="/bbs-portlet/images/contents/Bbs/board/lbl_bbs_notice.png" alt="상단공지" class="ico_notice">
</div>
<div class="num_area">
<span class="table_date"><strong>최종수정</strong>
2020.02.25
</span>
<span class="table_hit"><strong>조회수</strong>
4,538
</span>
</div>
</div>
<div class="subject">
<a href="http://www.dankook.ac.kr/web/kor/-390?p_p_id=Bbs_WAR_bbsportlet&p_p_lifecycle=0&p_p_state=normal&p_p_mode=view&p_p_col_id=column-2&p_p_col_pos=1&p_p_col_count=2&_Bbs_WAR_bbsportlet_curPage=1&_Bbs_WAR_bbsportlet_action=view_message&_Bbs_WAR_bbsportlet_messageId=714314">
<div class="subject_txt">2020학년도 1학기 재학생 추가 등록 안내</div>
<div class="ico_area">
<!-- <img src="/bbs-portlet/images/contents/Bbs/board/icon_mobile.gif" alt="mobile" class="ico_mobile"-->
<img src="/bbs-portlet/images/contents/Bbs/board/icon_hit.gif" alt="인기글" class="ico_hit">
</div>
</a>
</div>
<div class="btm_area">
<span class="table_poster "> <strong>작성자</strong> 재무회계팀 </span>
<span class="table_category"> <strong>분류</strong>
일반 > 공통
</span>
</div>
</li>상단 공지 필터링
메모장에 붙여넣고 뭐가 다른지 한번 분석해보자.
보면.
<div class="write_num">
NO. 3584
</div> <div class="write_num">
<img src="/bbs-portlet/images/contents/Bbs/board/lbl_bbs_notice.png" alt="상단공지" class="ico_notice">
</div>이 부분이 다르다.
맨 위에 고정 시켜 놓은 글은 상단 공지라고 적혀져있고, NO.가 없다.
이 부분을 이용해서 정크 데이터를 지우자.
분류 필터링
그리고 데이터를 긁어서 메모장에 붙여넣은 김에 데이터 한가지를 더 찾아보자.
죽전 / 천안 / 공통이 위치할 부분이다.
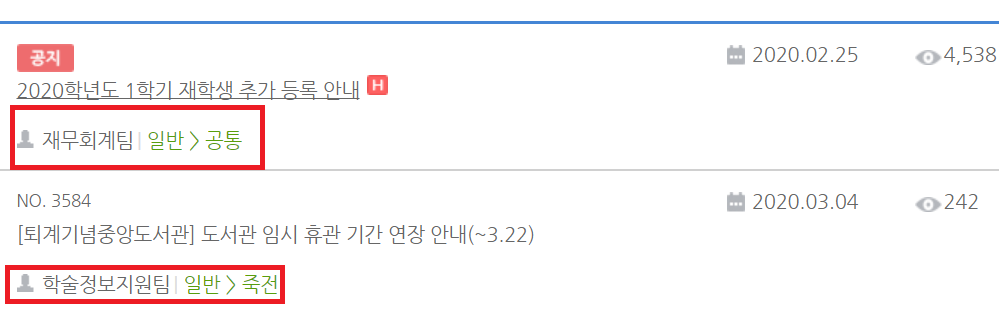
이쪽을 마우스 우클릭해서 검사를 누르고 위 코드 블럭에서 어디쯤에 있을지 찾아보자.
난 위 코드 블럭을 옮겨놓은 메모장에서 컨트롤 + f로 검색해보겠다.
<div class="btm_area">
<span class="table_poster ">
<strong>작성자</strong> 학술정보지원팀
</span>
<span class="table_category">
<strong>분류</strong>
일반 > 죽전
</span>
</div> <div class="btm_area">
<span class="table_poster "> <strong>작성자</strong> 재무회계팀 </span>
<span class="table_category"> <strong>분류</strong>
일반 > 공통
</span>
</div>데이터가 조금 에매하다.
쓸모없는 껍데기를 제거했다.
<span class="table_category">
<strong>분류</strong>
일반 > 죽전
</span> <span class="table_category">
<strong>분류</strong>
일반 > 공통
</span>최선을 다해 제거했지만 이 상태에서 .text태그를 사용하면 '분류 일반 > 공통' 이렇게 나온다.
필요없는 데이터가 많이 들어가있다.
그리고 '일반'부분도 다른 글에서는 '채용'으로 바뀐다.
뭐 일단.
코드를 짜보자.
분석을 토대로 코딩
# 제목, url 데이터
all_posts_subject = soup.select('ul > li > div.subject > a')
# 천안 / 죽전 / 공통 데이터
all_posts_btm_area = soup.select('ul > li > div.btm_area > span.table_category')
# 상단 공지 데이터
num = soup.find_all(alt='상단공지') # 상단 공지 크롤링 / num에 리스트로 들어가니까 카운트 가능상단 공지 필터링 코딩
상단 공지는 저 상태로 len() 사용해서 del로 지우면 된다.
분류 필터링 코딩
for i in range(len(all_posts_btm_area)):
all_posts_btm_area[i] = all_posts_btm_area[i].text[8:10] # 천안 / 죽전 / 공통 단어만 뽑아내기다른 방법이 떠오르지 않는다.
그냥 이렇게 해보자.
.text태그를 사용하면 텍스트만 뽑힌다.
그러면 뽑은 데이터를 슬라이싱할 수 있다.
다행히도 텍스트만 뽑은 데이터의 길이가 전부 일정하다.
분류는 신경 안써도 된다.
일반부분은 특강 / 행사 / 채용 / 구매/입찰로 나뉜다.
구매/입찰쪽을 클릭해봤는데.
게시글이 하나도 없다.
즉, 구매/입찰이 작성되지 않는 이상 저 부분은 두 글자일 것이다.
더 나은 방법을 찾아야 한다.
이런식으로 어물쩡 넘어가는 건 코드를 불안정하게 만드는 요소이다.
파이썬은 슬라이싱이 뒤로도 가능하다.
[0:-2] 이런식으로 말이다.
게시글이 앞으로도 없길 바라며 데이터를 슬라이싱하자.
죽전 / 천안 / 공통은 모두 똑같은 두 글자라서 신경안써도 된다.
그럼 정제한 단어(천안 / 죽전 / 공통)을 기반으로 제목 / url 데이터를 가지고 있는 부분을 수정해보자.
데이터는 이런식으로 있을거다.
[~url1~제목1~,~url2~제목2~,~url3~제목3~,~url4~제목4~, ... ]
['천안','죽전','공통', ... ]
게시글의 수는 14개로 두 리스트의 크기는 똑같다.
그럼 같은 인덱스에 위치한 데이터는 같은 게시물을 가리킨다고 생각할 수 있다.
for i, all_post_subject in enumerate(all_posts_subject): # 뽑아낸 단어 인덱스를 기반으로
if all_posts_btm_area[i] != "죽전": # 게시글 필터링
CheonanCommonPosts.append(all_posts_subject[i]) # 원하는 데이터는 공통, 천안
CheonanCommonArea.append(all_posts_btm_area[i])필요한 데이터는 천안 / 공통이다.
이 두 가지를 뽑아내는 것은 if와 elif 두개가 필요하다.
그러니 그냥 죽전만 가지고 if 한 개로 끝내자.
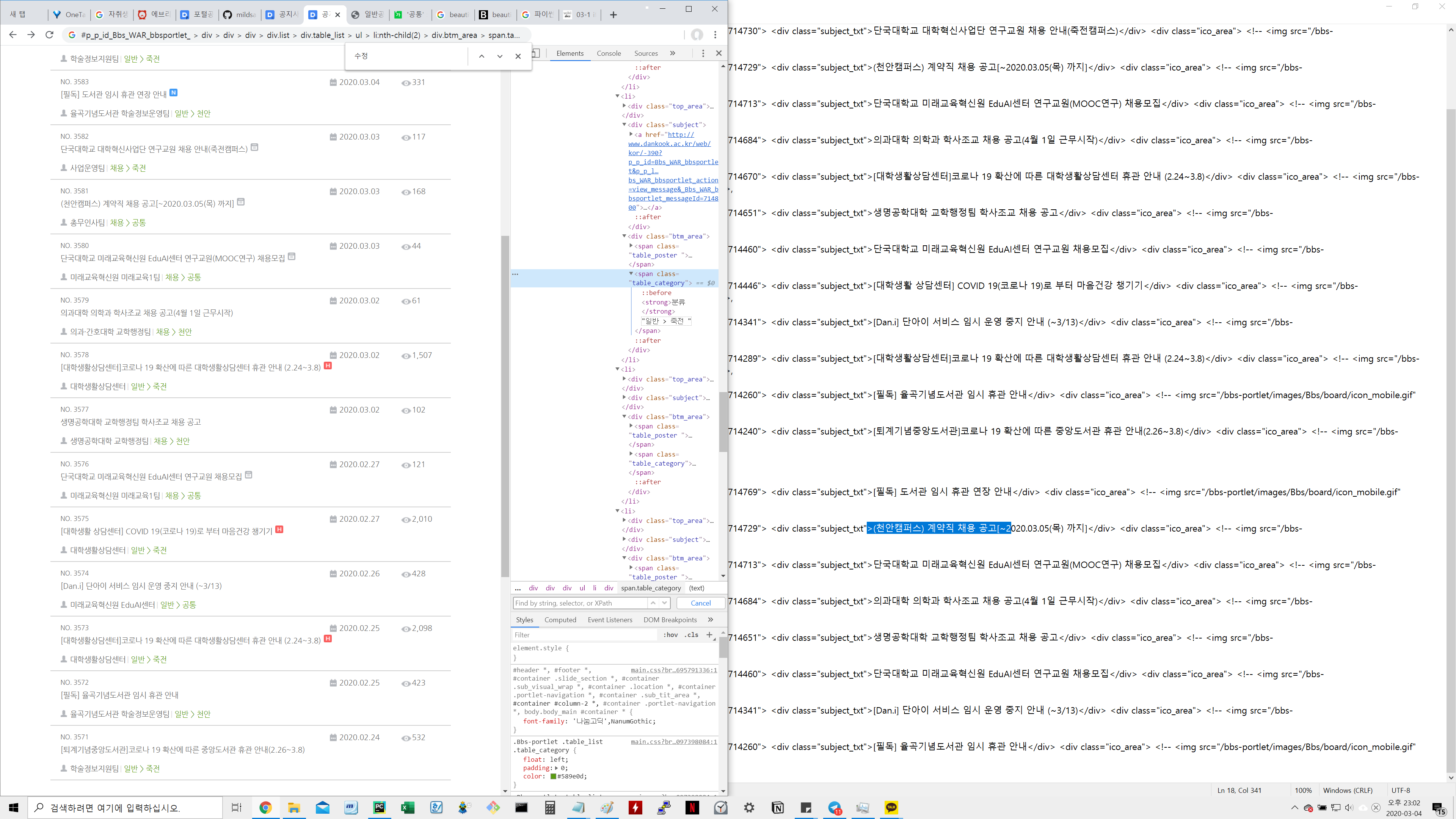
이런 결과물이 나온다.
게시물 필터링 코딩
이제 게시물이 최신 게시물인지 확인할 방법을 생각해야한다.
단국대도 한라대의 boardSeq처럼 _Bbs_WAR_bbsportlet_messageId=714769이 있다.
게시물 고유 넘버.
이 것을 이용해서 최신 게시물을 판단하자.
# 원하는 데이터
# _Bbs_WAR_bbsportlet_messageId=714769
# 앞 뒤에 중복되는 문자열이 없다
# 그래서 a href 부분을 save_url_~ 리스트에 입력하고
# &로 다시 분리한다.
for i, CheonanCommonPost in enumerate(CheonanCommonPosts):
save_url_messageld.append(str(CheonanCommonPost).split('"')[1])
save_messageld.append(save_url_messageld[i].split('&')[9])
use_url_messageld.append(str(CheonanCommonPost.get('href')))
use_messageld.append(use_url_messageld[i].split('&')[9])
print(use_messageld)
print(save_messageld).get 태그를 사용해서 url만 뽑아서 데이터를 정제할 수도 있고,
텍스트 형식으로 뽑아서 데이터를 정제할 수 있다.
변수를 좀 많이 쓴 이유는 변수를 재사용하기 싫어서이다.
변수를 재사용하다보면 코드를 쓰는 나조차 헷갈리는 경우가 많기 때문이다.
데이터는 print로 한번씩 찍어서 확인해주자.
그냥 맞겠지 하고 넘어가다가는 나중에 어디서 빵꾸난건지 찾는게 정말 힘들다.
코드
# -*- coding: utf-8 -*-
########## 테스트 코드
import requests
from bs4 import BeautifulSoup
import os
import telegram
import sys
import time
import re
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
my_token = '봇 토큰'
my_chat_id = "채널 주소 / 서비스 채널은 '@***' / 테스트 채널은 '-***'"
req = requests.get('http://www.dankook.ac.kr/web/kor/-390') # 단국대는 일반공지 - 천안 / 죽전 / 공통
client_errors = [400, 401, 403, 404, 408]
server_errors = [500,502, 503, 504]
print(time.strftime("%c", time.localtime(time.time())))
if req.status_code in client_errors:
print(req.status_code + ": 클라이언트 에러")
sys.exit(1)
elif req.status_code in server_errors:
print(req.status_code + ": 서버 에러")
sys.exit(1)
bot = telegram.Bot(token=my_token)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
all_posts_subject = soup.select('ul > li > div.subject > a')
all_posts_btm_area = soup.select('ul > li > div.btm_area > span.table_category')
num = soup.find_all(alt='상단공지') # 상단 공지 크롤링 / num에 리스트로 들어가니까 카운트 가능
save_url_messageld = []
save_messageld = []
use_url_messageld = []
use_messageld = []
CheonanCommonPosts = []
CheonanCommonArea = []
for i in range(len(num)): # 공지로 위로 올라간 게시글 제외한 최신 게시글 분류
del all_posts_subject[0]
del all_posts_btm_area[0]
for i in range(len(all_posts_btm_area)):
all_posts_btm_area[i] = all_posts_btm_area[i].text[8:10] # 천안 / 죽전 / 공통 단어만 뽑아내기
for i, all_post_subject in enumerate(all_posts_subject): # 뽑아낸 단어 인덱스를 기반으로
if all_posts_btm_area[i] != "죽전": # 게시글 필터링
CheonanCommonPosts.append(all_posts_subject[i]) # 원하는 데이터는 공통, 천안
CheonanCommonArea.append(all_posts_btm_area[i])
for i, CheonanCommonPost in enumerate(CheonanCommonPosts): # 원하는 데이터
save_url_messageld.append(str(CheonanCommonPost).split('"')[1]) # _Bbs_WAR_bbsportlet_messageId=714769
save_messageld.append(save_url_messageld[i].split('&')[9]) # 앞 뒤에 중복되는 문자열이 없다.
use_url_messageld.append(str(CheonanCommonPost.get('href'))) # 그래서 a href 부분을 save_url_~ 리스트에 입력하고
use_messageld.append(use_url_messageld[i].split('&')[9]) # &로 다시 분리한다.
print(use_messageld) # .get을 안쓴 이유는 CheonanCommonPosts가 리스트이기 때문.
print(save_messageld)
save_messageld[0] = save_messageld[0].lstrip(";") # 파일 리스트로 불러올때 ; 기준으로 나누려고 0번 앞에 ;를 제거함
if not(os.path.isfile(os.path.join(BASE_DIR, 'dankook_latest.txt'))):
new_file = open("dankook_latest.txt", 'w+',encoding='utf-8')
new_file.writelines(save_messageld)
new_file.close()
with open(os.path.join(BASE_DIR, 'dankook_latest.txt'), 'r+',encoding='utf-8') as f_read: # DB 구현후 변경 에정
before = f_read.readline().split(";")
for i, CheonanCommonPost in enumerate(CheonanCommonPosts): # 기존 크롤링 한 부분과 최신 게시글 사이에 게시글이 존재하는지 확인
print("post = " + CheonanCommonPost.text)
print("new = " + use_messageld[i])
print("before = " + before[0]) #
if before[0] == use_messageld[i]:
print("최신글입니다.")
break
elif before[1] == use_messageld[i]:
print("두번째 게시글이랑 체크, 첫 게시글 삭제된거냐")
break
elif before[2] == use_messageld[i]:
print("게시글 2개 삭제는 에바자나")
break
else:
url = CheonanCommonPost.get('href')
print(url)
try:
if CheonanCommonPost != CheonanCommonPosts[5]: # 10번 post 이상 넘어가는지 확인 / 텔레그램 메시지가 url 10개 이상 한번에 못보냄
bot.sendMessage(chat_id=my_chat_id, text= CheonanCommonArea[i] + "공지 : " + CheonanCommonPost.text)
bot.sendMessage(chat_id=my_chat_id, text=url)
else:
break
except Exception as ex:
print("timeout") # 짧은 시간에 message를 과도하게 보내면 timeout이 뜨는것같다.
break # message를 많이 보내서 발생한다기 보다는, 한번에 보낼 수 있는 url의 양이 10개로 제한되어 있는듯
with open(os.path.join(BASE_DIR, 'dankook_latest.txt'),'w+',encoding='utf-8') as f_write:
f_write.writelines(save_messageld)
print("\n")마치며
데이터 분석은 이것으로 끝났다.
어제저녁에 갑자기 민*이 생각나서 연락해서 만들어주겠다고 했다.
스스로 정한 취침 시간이 12시 정각이었고,
만들어주겠다고 하고 공지사항 url을 받은게 21시 44분이다.
최소 11시 30분 전까지는 만들어야겠다고 생각하고,
그냥 달렸다.
이미 한라대 공지 알림 봇을 만들면서 만든 코드가 있어서 좀 많이 빠르게 작업한 것 같다.
어차피 데이터 분석이 메인이고,
내가 가고 싶은 분야가 데이터 분석이라 한번 도전해볼 만한 가치가 있었다.
퀄리티는 그렇게 이쁘다고 생각하지 않는다.
작동만 되면 된다.라는 생각으로 만들었으니까.
23시 49분에 코드를 완성했다.
2시간쯤 걸렸다.
별 의미 없는 타임어택이긴 해도.
재밌었다.
뭐. 그럼 된 거지
참고문헌
스마트 경제, http://www.dailysmart.co.kr/news/articleView.html?idxno=21924, 사진