


연습문제
- 판다스의 특징으로 알맞은 것을 고르시오.
- 답 : 4. Excel, Json, Pickle, csv 등의 데이터 타입을 호출할 수 있다.
- 설명 : 판다스는 데이터 분석을 위한 파이썬 라이브러리로 데이터프레임은 여러 개의 시리즈 객체로 구성되어 있음
- 다음 코드를 실행할 경우 예상되는 결과값은 무엇인가?
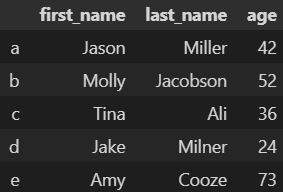
import pandas as pd raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'], 'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'], 'age': [42, 52, 36, 24, 73]} df = pd.DataFrame(raw_data, index=['a', 'b', 'c', 'd', 'e']) df["a"]
- 답 : 2. KeyError
- 설명 : 인덱스 이름으로 참고하려면 loc() 함수를 사용 (df["a"] -> df.loc["a"])
- 판다스에서는 엑셀의 피봇 테이블과 같이 데이터의 통계치를 산출하는 함수들이 있다. 다음 중 이러한 역할을 하지 못하는 함수는 무엇인가?
- 답 : 4. summary
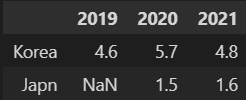
다음 코드를 실행할 경우 예상되는 결과값은 무엇인가?
nested_dict = {'Korea': {2019: 4.6, 2020: 5.7, 2021: 4.8}, 'Japn': {2020: 1.5, 2020: 1.5, 2021: 1.6}} df = pd.DataFrame(nested_dict).T # 전치 메소드- 답 : 1

- 답 : 1
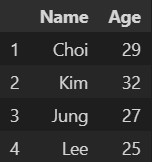
- 다음 코드를 실행할 경우 예상되는 결과값은 무엇인가?
data = [['Choi', 29], ['Kim', 32], ['Jung', 27], ['Lee', 25]] df = pd.DataFrame(data, columns=['Name', 'Age'], index=[1, 2, 3, 4]) df.iloc[2]['Age']- 답 : 4. 27
- 두 개의 데이터프레임을 병합하기 위해 merge 함수를 사용할 수 있다. 다음 중 merge 함수의 매개 변수 중 설명이 맞는 것을 고르시오.
- 답 : 1. how : 병합할 유형을 지정한다. full, left, right, inner가 있다.
- 다음 코드를 실행할 경우 예상되는 결과값은 무엇인가?
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3, 4, 1, 1, 2, 4, 1, 2], 'Year': [2014, 2015, 2014, 2015, 2014, 2015, 2016, 2017, 2016, 2014, 2015, 2017], 'Points': [876, 789, 863, 673, 741, 812, 756, 788, 694, 701, 804, 690]} df = pd.DataFrame(ipl_data) df.groupby("Team")["Points"].mean()- 답 : 4
Team Devils 768.000000 Kings 761.666667 Riders 762.250000 Royals 752.500000 kings 812.000000 Name: Points, dtype: float64
- 실행 결과와 같은 데이터가 존재할 때, df에 Age 열을 제외하여 저장하고 싶다고 가정하자. 적합하지 않은 코드는 무엇인가?
data = [['Choi', 29], ['Kim', 32], ['Jung', 27], ['Lee', 25]] df = pd.DataFrame(data, columns=['Name', 'Age'], index=[1, 2, 3, 4])
- 답 : 1. df = df.drop("Age"), 3. df.drop("Age", inplace=True)
- 설명 : 1, 3번 모두 axis=1로 설정해 주어야 함
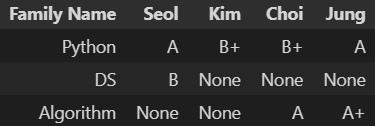
- 다음과 같은 데이터프레임 df가 존재할 때, 과목별로 Null 값의 개수를 구하려고 한다. 빈칸에 들어 갈 값을 고르시오.
df = pd.DataFrame(data=[['Seol', 'A', 'B', None], ['Kim', "B+", None, None], ['Choi', 'B+', None, 'A'], ['Jung', 'A', None, 'A+']], columns=['Family Name', 'Python', 'DS', 'Algorithm']) df = df.set_index('Family Name').T
- 답 : 2
df.isnull().sum(axis=1)Python 0 DS 3 Algorithm 2 dtype: int64
- 다음은 판다스의 내장 함수(built-in function)에 대한 설명이다. 함수와 기능이 잘못 짝지어진 것을 고르시오.
- 답 : 4. mean() : 시리즈(series) 데이터 값이 숫자형 값일 경우에는 평균값을, 문자열 타입일 경우 글자 수에 대한 카운터(counter) 값을 보여준다.
- 설명 : 문자열의 경우 오류 발생
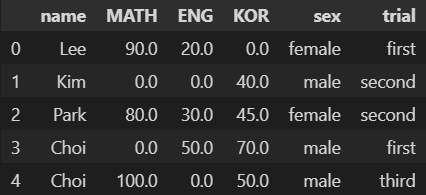
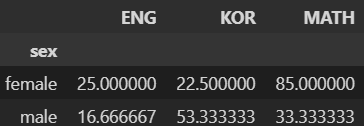
다음과 같은 데이터에서 숫자형 열들의 통계 데이터를 추출하고자 한다. 적절한 코드를 고르시오.
df = pd.DataFrame(data=[['Lee', 90.0, 20.0, 0.0, 'female', 'first'], ['Kim', 0.0, 0.0, 40.0, 'male', 'second'], ['Park', 80.0, 30.0, 45.0, 'female', 'second'], ['Choi', 0.0, 50.0, 70.0, 'male', 'first'], ['Choi', 100.0, 0.0, 50.0, 'male', 'third']], columns=['name', 'MATH', 'ENG', 'KOR', 'sex', 'trial']) df
- 답 : 1
pd.pivot_table(df, index=["sex"], aggfunc=np.mean)- 설명 : 1번만 문법상 문제가 없음

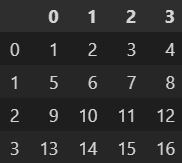
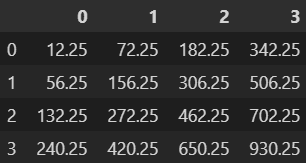
- 다음 실행 결과와 같은 데이터프레임이 존재할 때, 데이터프레임과 각 데이터프레임의 행의 평균에 대한 합의 제곱을 구하기 위한 코드로 올바른 것은?
df = pd.DataFrame(np.arange(1, 17).reshape(4, 4)) df
- 답 : 1. (df + df.mean(axis=1)) ** 2

- 답 : 1. (df + df.mean(axis=1)) ** 2
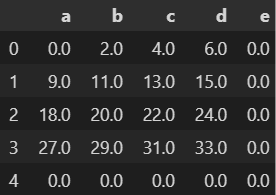
- 다음 실행 결과와 같은 결과를 출력하기 위해 빈칸의 코드로 적절한 것은?
df1 = pd.DataFrame(np.arange(25).reshape(5, 5), columns=list("abcde")) df2 = pd.DataFrame(np.arange(16).reshape(4, 4), columns=list("abcd"))
- 답 : 3. (df1 + df2).fillna(0)
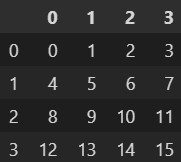
다음 실행 결과와 같은 결과를 출력하기 위해 빈칸의 코드로 적절한 것은?
df1 = pd.DataFrame(np.arange(16).reshape(4, 4)) df2 = pd.DataFrame([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]])
- 답 : 3. df1.dot(df2)
공부
출처
최성철, 『데이터 과학을 위한 파이썬 머신러닝』, 초판, 한빛아카데미, 2022