

어제 데이터 엔지니어 직무로 면접을 봤다.
면접 질문 중에 내가 제대로 대답하지 못한 부분들에 대해 면접 복기를 해보면서 다시 공부해봤다.
면접 보기 전에는 남들의 지식을 바탕으로 학습을 했다면, 지금은 내가 모든 것을 뜯어볼 시간이다.
- S3의 key가 어떻게 생겼는지 아는가?
- 아직 모르겠다. 이번주 안으로 S3를 활성화해서 어떻게 데이터가 저장되는지 확인해볼 계획이다.
- MySQLToS3Operator는 key가 존재하면 반드시 에러를 발생시킨다고 했는데, 그 이유에 대해서 생각해 봤는가?
- S3를 공부하면 더 확실해지겠지만, 동일한 key를 갖는 S3 bucket이 존재해서 그런 것으로 추정된다.
- 그리고 key가 존재한다고 하더라도, replace 파라미터를 True로 주면 bucket을 갱신할 수 있다.
- MySQLToS3Operator가 어떻게 동작하는지 아는가?
- 지금부터 확인해보려고 한다.
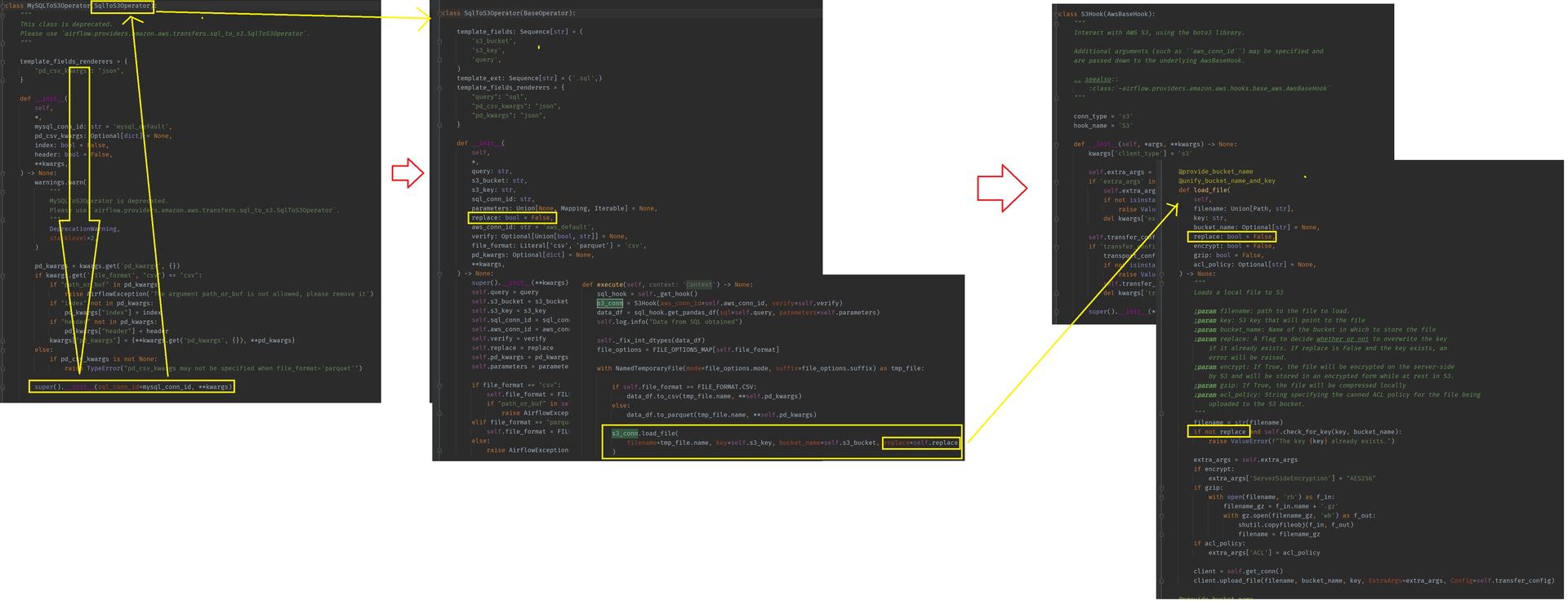
나는 MySQLToS3Operator를 사용할때는 S3 key가 있으면 MySQLToS3Operator가 동작하지 않는다고 생각했었다..
그런데 오늘 소스코드를 뜯어보니 replace 파라미터가 있었고, replace=True이면 S3 key가 있어도 정상적으로 동작하는 것을 알게 되었다.
Version - 3.3.0
1. airflow.providers.amazon.aws.transfers.mysql_to_s3
A. 공식 Document
airflow.providers.amazon.aws.transfers.mysql_to_s3 — apache-airflow-providers-amazon Documentation
위 document를 보면 This class is deprecated. Please use airflow.providers.amazon.aws.transfers.sql_to_s3.SqlToS3Operator.라고 적혀있다.
이 클래스는 사용되지 않으니, SqlToS3Operator를 사용하라고 한다.
B. Source Code
path: airflow\providers\amazon\aws\transfers\mysql_to_s3.py
import warnings
from typing import Optional
from airflow.exceptions import AirflowException
from airflow.providers.amazon.aws.transfers.sql_to_s3 import SqlToS3Operator
warnings.warn(
"This module is deprecated. Please use airflow.providers.amazon.aws.transfers.sql_to_s3`.",
DeprecationWarning,
stacklevel=2,
)
class MySQLToS3Operator(SqlToS3Operator):
"""
This class is deprecated.
Please use `airflow.providers.amazon.aws.transfers.sql_to_s3.SqlToS3Operator`.
"""
template_fields_renderers = {
"pd_csv_kwargs": "json",
}
def __init__(
self,
*,
mysql_conn_id: str = 'mysql_default',
pd_csv_kwargs: Optional[dict] = None,
index: bool = False,
header: bool = False,
**kwargs,
) -> None:
...
...
...
super().__init__(sql_conn_id=mysql_conn_id, **kwargs)
소스코드를 열어보니 This module is deprecated. Please use airflow.providers.amazon.aws.transfers.sql_to_s3이라는 warning 메시지가 보인다.
그리고 MySQLToS3Operator class가 SqlToS3Operator를 상속받고 있는 것을 알 수 있다.
부모 클래스로 매개변수 값들을 다 넘기는 걸 보면, 내가 찾고자 하는 정보는 여기에 없는 것 같다.
2. airflow.providers.amazon.aws.transfers.sql_to_s3
A. 공식 Document
airflow.providers.amazon.aws.transfers.sql_to_s3 — apache-airflow-providers-amazon Documentation
a. Classes
- SqlToS3Operator
- Saves data from a specific SQL query into a file in S3.
b. Attributes
- FILT_FORMAT
- FileOptions
- FILE_OPTIONS_MAP
c. Inheritance Structure
- airflow.models.BaseOperator
- airflow.providers.amazon.aws.transfers.sql_to_s3
d. more information
SQL to Amazon S3 Transfer Operator — apache-airflow-providers-amazon Documentation
SqlToS3Operator를 사용하여 SQL server로부터 Amazon S3 file로 data를 copy한다.
SQL hook이 SQL 결과를 pandas dataframe으로 변환하는 function이 있는 한, 어느 SQL connection도 SqlToS3Operator는 호환된다.
ㄱ) Prerequisite Tasks
- AWS Console이나 AWS CLI를 사용하여 필요한 자원을 생성하라.
pip install 'apache-airflow[amazon]'을 설치하라.- Setup Connection.
ㄴ) MySQL to Amazon S3
MySQL query에 대한 응답을 Amazon S3 file로 보내는 예제
sql_to_s3_task = SqlToS3Operator(
task_id="sql_to_s3_task",
sql_conn_id="mysql_default",
query=SQL_QUERY,
s3_bucket=S3_BUCKET,
s3_key=S3_KEY,
replace=True,
)
e. Parameters
query: str
- 실행될 sql query
- 만약 절대 경로에 위치한 file을 실행하려면,
.sql확장자로 끝나야 한다.
s3_bucket: str
- data가 저장될 bucket
s3_key: str
- 파일에 필요한 key
- 파일의 이름이 포함된다.
replace: bool
- 만약 S3에 file이 존재한다면 교체여부.
sql_conn_id: str
- 특정 database를 참조.
- MySQL, Postgre ...
parameters: (Union[None, Mapping, Iterable])
- SQL query를 render할 parameter 지정.
aws_conn_id: str
- 특정 S3 connection을 참조.
verify: Optional[Union[bool, str]]
- S3 connection의 SSL certificates 확인 여부
- default로 SSL certificates가 확인된다.
- False
- path/to/cert/bundle.pem
file_format: typing_extensions.Literal[csv, json, parquet]
- 대상 파일 형식, 오직
csv,json,parquet만 허용된다. - S3에 저장될 파일 형식
pd_kwargs: Optional[dict]
- DataFrame
.to_parquet(),.to_json(),.to_csv()가 포함될 인자들.
f. Field
template_fields: Sequence[str]
['s3_bucket', 's3_key', 'query']
template_ext: Sequence[str]
['.sql']
template_fields_renderers
[
"query": "sql",
"pd_csv_kwargs": "json",
"pd_kwargs": "json",
]
g. Method
execute(self, context)
이것은 operator를 생성할때 파생되는 main method이다.
Context는 jinka templates를 rendering할 때와 동일한 dictionary이다.
더 많은 context는 get_template_context를 참고하라.
이 context가 pythonOperator에서 python_callable로 입력되는 함수의 **context parameter와 동일한 것 같다.
B. Source Code
a. Attributes
FILT_FORMAT
FILE_FORMAT = Enum(
"FILE_FORMAT",
"CSV, PARQUET",
)
FileOptions
FileOptions = namedtuple('FileOptions', ['mode', 'suffix'])
FILE_OPTIONS_MAP
FILE_OPTIONS_MAP = {
FILE_FORMAT.CSV: FileOptions('r+', '.csv'),
FILE_FORMAT.PARQUET: FileOptions('rb+', '.parquet'),
}
b. Classes
SqlToS3Operator
class SqlToS3Operator(BaseOperator):
...
...
...
BaseOperator를 상속받는다.
c. Method
execute
def execute(self, context: 'Context') -> None:
sql_hook = self._get_hook()
s3_conn = S3Hook(aws_conn_id=self.aws_conn_id, verify=self.verify)
data_df = sql_hook.get_pandas_df(sql=self.query, parameters=self.parameters)
self.log.info("Data from SQL obtained")
self._fix_int_dtypes(data_df)
file_options = FILE_OPTIONS_MAP[self.file_format]
with NamedTemporaryFile(mode=file_options.mode, suffix=file_options.suffix) as tmp_file:
if self.file_format == FILE_FORMAT.CSV:
data_df.to_csv(tmp_file.name, **self.pd_kwargs)
else:
data_df.to_parquet(tmp_file.name, **self.pd_kwargs)
s3_conn.load_file(
filename=tmp_file.name, key=self.s3_key, bucket_name=self.s3_bucket, replace=self.replace
)
execute method는 BaseOperator class의 execute를 overriding한 것이다.
BaseOperator class의 execute method는 raise NotImplementedError로 작성되어서 execute method를 overriding하여 구현하지 않으면 에러가 발생한다.
sql_hook = self._get_hook()- Database의 hook을 얻는다.
self.sql_conn_id를 사용
- Database의 hook을 얻는다.
s3_conn = S3Hook(aws_conn_id=self.aws_conn_id, verify=self.verify)- S3의 hook을 얻는다.
self.aws_conn_id를 사용
- S3의 hook을 얻는다.
data_df = sql_hook.get_pandas_df(sql=self.query, parameters=self.parameters)- Database의 hook을 통해 query를 실행하고 DataFrame 형태로 반환받는다.
self._fix_int_dtypes(data_df)- null 값에 대해 처리한다.
file_options = FILE_OPTIONS_MAP[self.file_format]- 파일 종류에 따라 어떤 방식으로 추출할지 정하는 부분으로 추정된다.
s3_conn.load_file(filename=tmp_file.name, key=self.s3_key, bucket_name=self.s3_bucket, replace=self.replace)- 위에서 얻은
csvorparquet파일을 S3에 업로드한다. - airflow - s3
- 위에서 얻은
_get_hook
def _get_hook(self) -> DbApiHook:
self.log.debug("Get connection for %s", self.sql_conn_id)
conn = BaseHook.get_connection(self.sql_conn_id)
hook = conn.get_hook()
if not callable(getattr(hook, 'get_pandas_df', None)):
raise AirflowException(
"This hook is not supported. The hook class must have get_pandas_df method."
)
return hook
Database의 connection을 얻어오고 hook을 얻어온다.
얻어온 hook을 반환한다.
반환되는 type은 DbApiHook이다.
execute Method에서 호출된다.
_fix_int_dtypes
@staticmethod
def _fix_int_dtypes(df: pd.DataFrame) -> None:
"""Mutate DataFrame to set dtypes for int columns containing NaN values."""
for col in df:
if "float" in df[col].dtype.name and df[col].hasnans:
# inspect values to determine if dtype of non-null values is int or float
notna_series = df[col].dropna().values
if np.equal(notna_series, notna_series.astype(int)).all():
# set to dtype that retains integers and supports NaNs
df[col] = np.where(df[col].isnull(), None, df[col])
df[col] = df[col].astype(pd.Int64Dtype())
elif np.isclose(notna_series, notna_series.astype(int)).all():
# set to float dtype that retains floats and supports NaNs
df[col] = np.where(df[col].isnull(), None, df[col])
df[col] = df[col].astype(pd.Float64Dtype())
staticmethod라서 클래스 변수인 self를 사용하지 않았다.
따로 return값은 없는데, 여기에서 pandas의 DataFrame은 mutable한 성질이 있음을 알 수 있다.
참고