

Databricks blog에 posting된 글을 정리하였습니다.
https://www.databricks.com/blog/2019/08/21/diving-into-delta-lake-unpacking-the-transaction-log.html
transaction log는 Delta Lake를 이해하기 위한 핵심 개념이다. (transaction log는 ACID transaction, scalable metadata handling, time travel ..etc의 공통 개념이다). 이 글에서는 transaction log가 무엇인지, file level에서는 어떻게 동작하는지, 여러 개의 동시 읽기 및 쓰기 문제에 대한 해결책을 제공하는 방법에 대해 살펴본다.
1. What is the Delta Lake Transaction Log?
Delta Lake transaction log (DeltaLog)는 Delta Lake table이 처음 만들어진 이후 수행된 모든 transaction들이 순서대로 기록된 것이다.
2. What is the Transaction Log Used For?
A. Single Source of Truth
사용자에게 항상 정확한 데이터 view를 보여주기 위해, Deta Lake transaction log는 사용자가 테이블에 시도하는 모든 변경 사항을 추적하는 중앙 레포지토리(central repository) single source of truth 역할을 한다.
사용자가 처음으로 Delta Lake 테이블을 읽거나 마지막으로 읽은 이후 수정된 open table에 대해 새로운 쿼리를 실행하면, Spark는 transaction log를 확인하여 테이블에 새로운 transaction이 post되었는지 확인한 다음, end user의 테이블을 새로운 변경사항으로 update한다. 이렇게 하면 사용자의 테이블 버전이 항상 가장 최근 쿼리 시점의 마스터 레코드(모든 transaction log가 적용된 버전)와 synchronized된다.
B. The Implementation of Atomicity on Delta Lake
data lake에서 수행되는 작업(insert, update..)이 완전히 완료되거나 전혀 완료되지 않도록 보장한다. 하드웨어 장애나 소프트웨어 버그로 인해 데이터가 테이블에 부분적으로만 기록되는 문제를 방지한다.
transaction log는 delta lake가 atomicity를 보장하게하는 매커니즘이다. transaction log에 기록되지 않은 트랜잭션은 발생한 적이 없는 것이나 마찬가지이다. 완전하고 완벽하게 실행된 transaction만 기록하고 이 기록을 single source of truth로 사용한다.
3. How Doese the Transaction Log Work?
A. Breaking Down Transaction Into Atomic Commits
사용자가 테이블을 수정하는 작업(INSERT, UPDATE, DELETE)을 수행할 때마다 Delta Lake는 해당 작업을 아래 작업 중 하나 이상의 작업으로 구성된 일련의 개별 단계로 세분화한다.
- Add file: 데이터 파일을 추가한다.
- Remove file: 데이터 파일을 제거한다.
- Update metadata: 테이블의 메타데이터를 업데이트한다. (table's name, schema, partitioning)
- Set transaction: 구조화된 스트리밍 작업이 지정된 ID로 micro-batch를 commit했음을 기록한다.
- Change protocol: Delta Lake transaction log를 최신 software protocol로 전환하여 새로운 기능을 사용할 수 있다.
- Commit info: commit과 관련된 정보, 어떤 작업이 언제 어디서 수행되었는지에 대한 정보를 포함한다.
그 후 transaction log에 commit이라는 정렬된 원자 단위로 기록된다.
a. 예시
user가 table에 새로운 column을 추가하고 데이터를 더 추가하기 위해 transaction을 생성한다. Delta Lake는 해당 transaction을 구성 요소로 나누고, transaction이 완료되면 다음 commit으로 transaction log에 추가한다.
- Update metadata: 새로운 column을 포함하도록 schema를 변경한다.
- Add file: 추가된 각 파일에 대해
B. The Delta Lake Transaction Log at the File Level
user가 Delta Lake 테이블을 생성하면 해당 table의 transaction log가 _delta_log 하위 디렉토리에 자동으로 생성된다. user가 해당 테이블을 변경하면 변경 사항은 transaction log에 순서대로 atomic commit으로 기록된다. 각 commit은 000000.json으로 시작하는 JSON 파일로 기록된다. 테이블을 추가로 변경하면 다음 commit이 000001.json으로 기록되는 식으로 후속 JSON 파일이 생성된다.
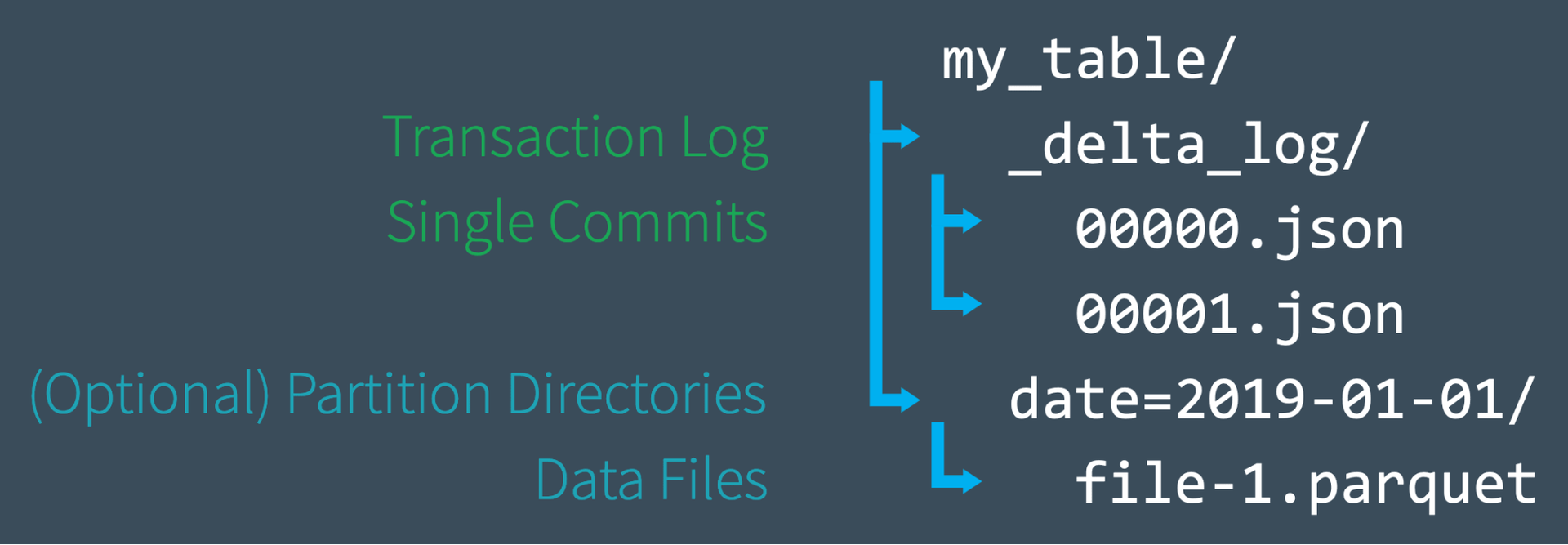
a. 예시
테이블에 1.parquet, 2.parquet 파일로 레코드를 추가할 수 있다. 이 transaction은 transaction log에 자동으로 추가되고 커밋 000000.json으로 distk에 저장된다.
그 다음 레코드를 삭제하여 1.parquet, 2.parquet을 삭제하고 새 레코드(3.parquet)를 추가할 수 있다. 이 작업은 000001.json으로 다음 commit에 기록된다.

1.parquet, 2.parquet은 더 이상 Delta lake 테이블의 일부가 아니지만, 궁극적으로 서로를 상쇄했음에도 불구하고 테이블에서 해당 작업이 수행되었기 때문에 transaction log에 추가, 삭제가 기록된다.
Delta Lake는 테이블을 audit하거나 특정 시점으로 time travel을 하는 경우 정확하게 확인할 수 있도록 atomic commit을 유지한다.
또한 테이블에서 데이터 파일을 제거했어도 Spark는 Disk에서 파일을 열심히 제거하지 않는다. 사용자는 더 이상 필요하지 않는 파일은 VACUUM을 사용하여 삭제할 수 있다.
C. Quickly Recomputing State With Checkpoint Files
transaction log에 여러 번의 commit을 수행한 후, Delta Lake는 동일한 _delta_log 하위 디렉토리에 Parquet 형식의 checkpoint 파일을 저장한다. Delta Lake는 우수한 읽기 성능을 유지하기 위해 필요에 따라 자동으로 checkpoint를 생성한다.
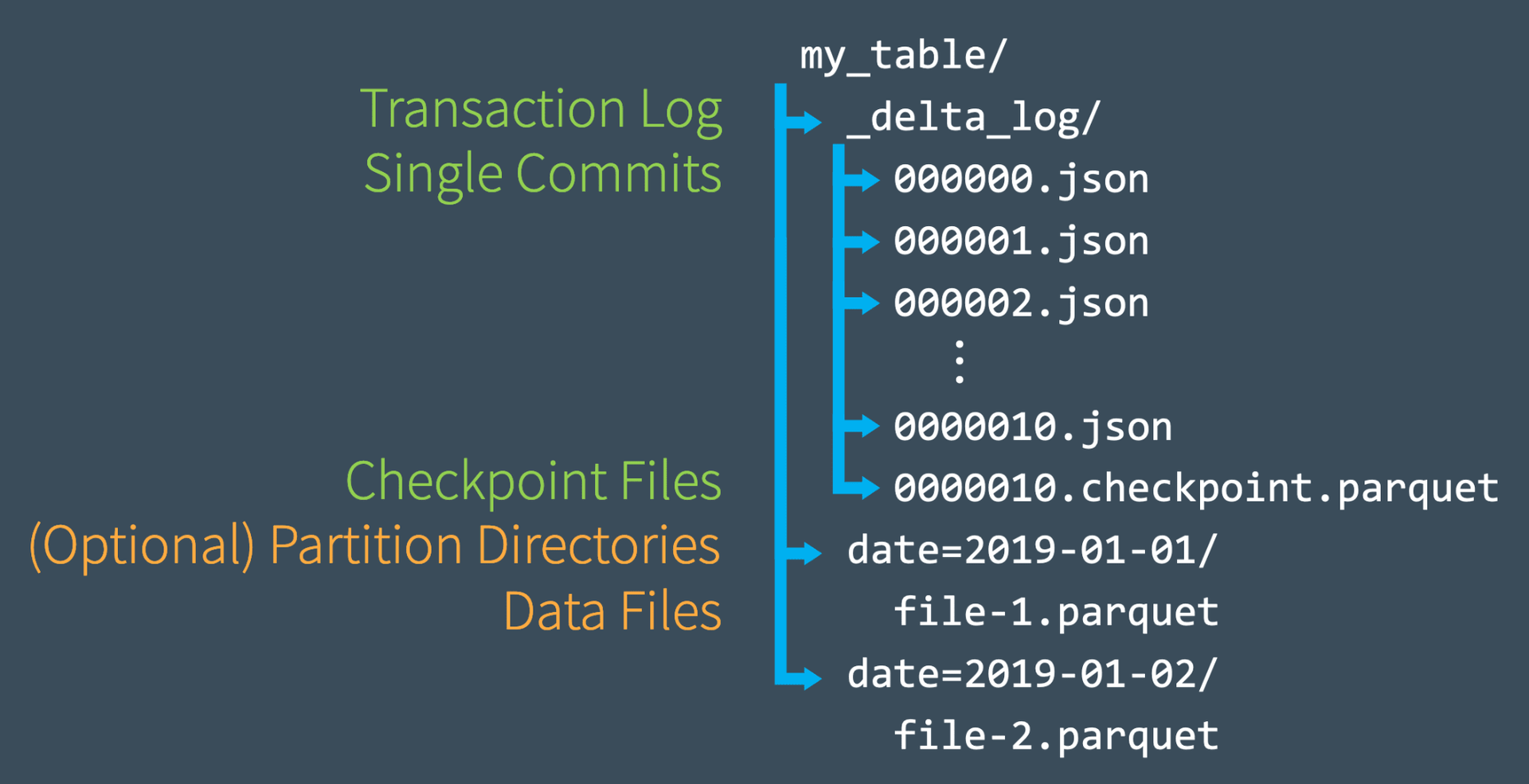
이런 checkpoint 파일은 특정 시점에 테이블의 전체 상태를 spark가 빠르고 쉽게 읽을 수 있는 parquet 형식으로 저장한다. 즉, 이 파일은 Spark 리더가 테이블의 상태를 완전히 재현할 수 있는 일종의 바로가기를 제공함으로써 Spark가 수천 개의 작고 비효율적인 JSON 파일을 재처리하지 않도록 한다.
속도를 높이기 위해 Spark는 listFrom작업을 실행하여 transaction log의 모든 파일을 보고, 최신 checkpoint 파일로 빠르게 건너뛰고, 가장 최근의 checkpoint 파일이 저장된 이후에 이루어진 JSON commit만 처리할 수 있다.
아래 그림에서 0000007.json 까지 commit을 생성했다고 생각하자. Spark는 이 commit을 통해 가장 최신 버전의 테이블을 memory에 자동으로 cache하여 빠르게 처리한다.
만약 다른 사용자가 테이블에 새 데이터를 작성하여 000012.json까지 commit을 추가할 수 있다. 이러한 새로운 transaction을 통합하고 테이블의 상태를 업데이트하기 위해 Spark는 listFrom version 7 작업을 실행하여 테이블의 새로운 변경 사항을 확인한다.
Spark는 중간의 모든 JSON 파일을 처리하는 대신 commit #10에 있는 테이블의 전체 상태가 포함되어 있는 가장 최근 checkpoint 파일로 건너뛸 수 있다. 이제 Spark는 000011.json, 000012.json의 증분 처리만 수행하면 테이블의 현재 상태를 확보할 수 있다. 그런 다음 Spark는 테이블의 version 12를 memory에 cache한다. 이 워크플로우를 따라 Delta Lake는 Spark를 사용하여 테이블의 상태를 항상 효율적으로 업데이트할 수 있다.

spark는 데이터를 memory 위에 올려서 사용한다.
D. Dealing With Multiple Concurrent Reads and Writes
만약 Delta Lake가 multiple concurrent read와 writes를 하는 경우에는 어떻게 될까?
Delta Lake는 Apache Spark로 구동되기 때문에 여러 사용자가 한 번에 테이블을 수정할 수 있다. 이러한 상황을 처리하기 위해 Delta Lake는 optimistic concurrency control을 사용한다.
E. What is Optimistic Concurrency Control?
Optimistic concurrency control은 여러 사용자가 테이블에 대해 수행한 transaction(changes)이 서로 충돌하지 않고 완료될 수 있닥 가정하는 concurrent transaction을 처리하는 방법이다. petabytes 단위의 데이터를 처리할 때 사용자가 데이터의 다른 부분에서 동시에 작업할 가능성이 높기 때문에 충돌하지 않는 transaction을 동시에 완료할 수 있다. 그래서 빠르다.
큰 퍼즐을 서로 다른 가장자리에서 맞추는 것처럼
optimistic concurrency control을 사용해서 사용자가 동일한 부분을 동시에 수정하려고 시도할 수 있다. Delta Lake에는 이를 위한 protocol이 있다.
F. Solving Conflicts Optimistically
Delta Lake는 ACID transaction을 제공하기 위해 commit을 어떻게 정렬해야 하는지(db에서 serializability 개념) 파악하고, 두 개 이상의 commit이 동시에 수행되는 경우 어떻게 해야 하는지 결정하는 protocol이 있다. Delta Lake는 mutual exclusion 규칙을 구현하여 이러한 경우를 처리한 다음 충돌이 발생하면 optimisticlly 해결하려고 시도한다. 이 protocol을 통해 Delta Lake는 여러 번의 동시 쓰기 후 테이블의 결과 상태가 서로 분리되어 연속적으로 발생한 경우와 동일하도록 보장하는 ACID isolation원칙을 구현할 수 있다.
- 일반적인 프로세스는
- 시작 테이블 버전을 기록한다.
- 일기/쓰기를 기록한다.
- 커밋을 시도한다.
- 다른 사람이 이긴 경우, 읽은 내용이 변경되었는지 확인한다.
- 반복한다.

- Delta Lake는 변경전에 읽은 테이블의 시작 테이블 버전(version 0)을 기록한다.
- user 1, 2가 동시에 테이블에 일부 데이터를 추가하려고 시도한다. 여기서 충돌이 발생하는 이유는 다음 커밋 중 하나만 000001.json으로 기록될 수 있기 때문이다.
- Delta Lake는 mutual exclusion라는 개념으로 이 충돌을 처리하는데, 이는 한 명의 사용자만 000001.json을 성공적으로 commit할 수 있다는 것을 의미한다. user 1의 commit은 accept되고 user 2는 reject된다.
- user 2에 대해 Delta Lake는 optimistically 처리하는 것을 선호한다. 테이블에 새로운 커밋이 수행되었는지 확인하고 해당 변경 사항을 반영하도록 테이블을 조용히 업데이트한 다음, 데이터 처리 없이 새로 업데이트된 테이블에 대한 사용자 2의 커밋을 다시 시도하여 000002.json을 성공적으로 commit한다.
Delta Lake가 optimistically 해결할 수 없는 조정 불가능한 문제가 있는 경우, 유일한 옵션은 오류를 발생시키는 것이다.
마지막으로, Delta Lake 테이블에서 이루어지는 모든 transaction은 disk에 직접 저장되므로, 이 프로세스는 durability라는 ACID 속성을 충족한다.
4. Other Use Cases
A. Time Travel
모든 테이블은 Delta Lake transaction log에 기록된 모든 commit을 합산한 결과이다. transaction log는 테이블의 원래 상태에서 현재 상태로 이동하는 방법을 정확하게 설명한다.
따라서 원본 테이블에서 시작하여 그 시점 이전의 commit만 처리함으로써 어느 시점에든 테이블의 상태를 재현할 수 있다. 이 기능을 time travel 또는 data versioning이라고 한다.
cc. Introducing Delta Time Travel for Large Scale Data Lakes, Delta Lake time travel documentation.
B. Data lineage and Debugging
테이블에 적용된 모든 변경 사항에 대한 최종 기록인 Delta Lake transaction log는 사용자에게 governance, audit, compliance purpose에 유용한 검증 가능한 data lineage를 제공한다. 또한, 의도치 않은 변경이나 파이프라인의 버그가 발생했을 때 그 원인이 된 정확한 작업까지 추적하는 데에도 사용할 수 있다. 사용자는 DESCRIBE HISTORY를 실행하여 변경된 내용과 관련된 메타데이터를 확인할 수 있다.