

0. To-Do
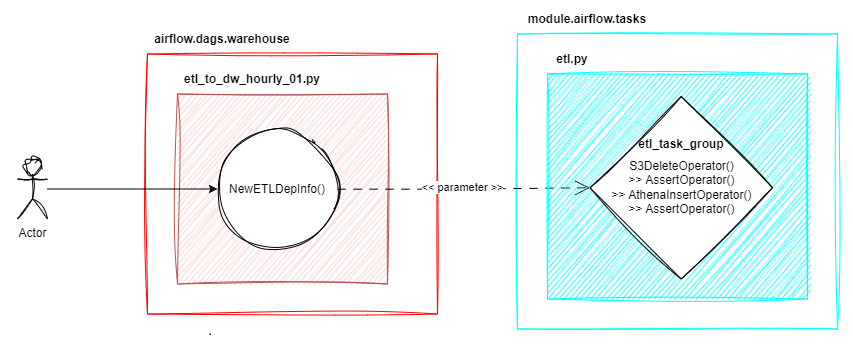
Data Warehouse에 Data를 적재하기 전후로 필요한 Data가 잘 적재되어 있는지, 적재한 데이터가 잘 적재되었는지를 검증할 필요가 생겼다.
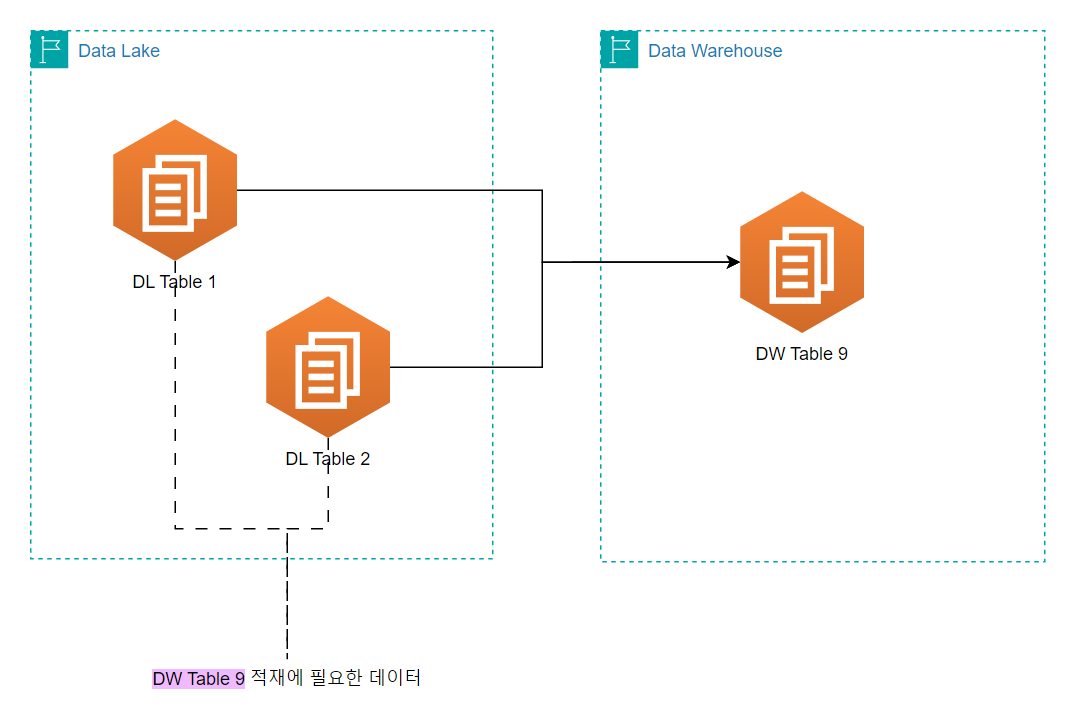
[사진 1]로 예를 들면 DW Table 9를 적재하기 전에는 DL Table 1, DL Table 2 데이터가 누락되지 않았는지 확인해야 한다. DW Table 9를 적재한 후에는 잘 적재되었는지 확인해야 한다.
1. 배경 지식
A. Data Architecture
우리의 Data Architecture는 [사진 2]처럼 구성되어 있다.
- DB에 저장된 데이터를 수정없이 Data Lake에 저장한다.
- Data Lake의 데이터를 가공 또는 집계하여 Data Warehouse에 적재한다.

B. Data Lake Quality Check Process
Data Architecture 중에 DB -> DL에 예전부터 Data Quality Check를 하고 있었다. (Data Validation이라고 이름지었었는데, 다시 생각해보니 잘못 지은 것 같다.)
DB -> DL에 적용되어 있는 Data Quality Check는 두 개의 데이터 소스(DB, DL)로부터 데이터를 가져와서 누락된 데이터가 있는지 검증하는 방식이다.
따라서 JDBC로 DB와 연결할 수 있고 Glue Data Catalog로 Data Lake를 쿼리할 수 있는 Spark를 사용했다.

이 방식을 DW Quality Check에 사용하기에는 여러가지 부적절한 부분들이 있다.
- DL Quality Check는 확장할 수 없다. (당시에 주요 Table만 검증하고자 했기에 수백개의 테이블의 Quality Check에는 적합하지 않다.)
- DW Quality Check는 Spark를 사용할 필요가 없다. (Source와 Target이 같은 Metadata store(glue data catalog)를 사용하기 때문에 Spark가 아닌 방법으로도 충분히 해결할 수 있다.)
2. To-Be
- DW Quality Check Process를 개발한다.
- 지금은 AWS의 Glue Data Catalog를 Metadata store로 사용하지만, 추후 Databricks의 Unity Catalog를 사용할 수도 있기 때문에 이를 고려해서 개발한다.
- 사용자는 쿼리라는 개념을 모르더라도 Quality Check를 할 수 있도록 구현한다. (사용자는 Assert Condition만 선언적으로 입력하고 어떻게 처리할지는 시스템에 위임한다.)
3. 해결 과정
A. UML Diagram
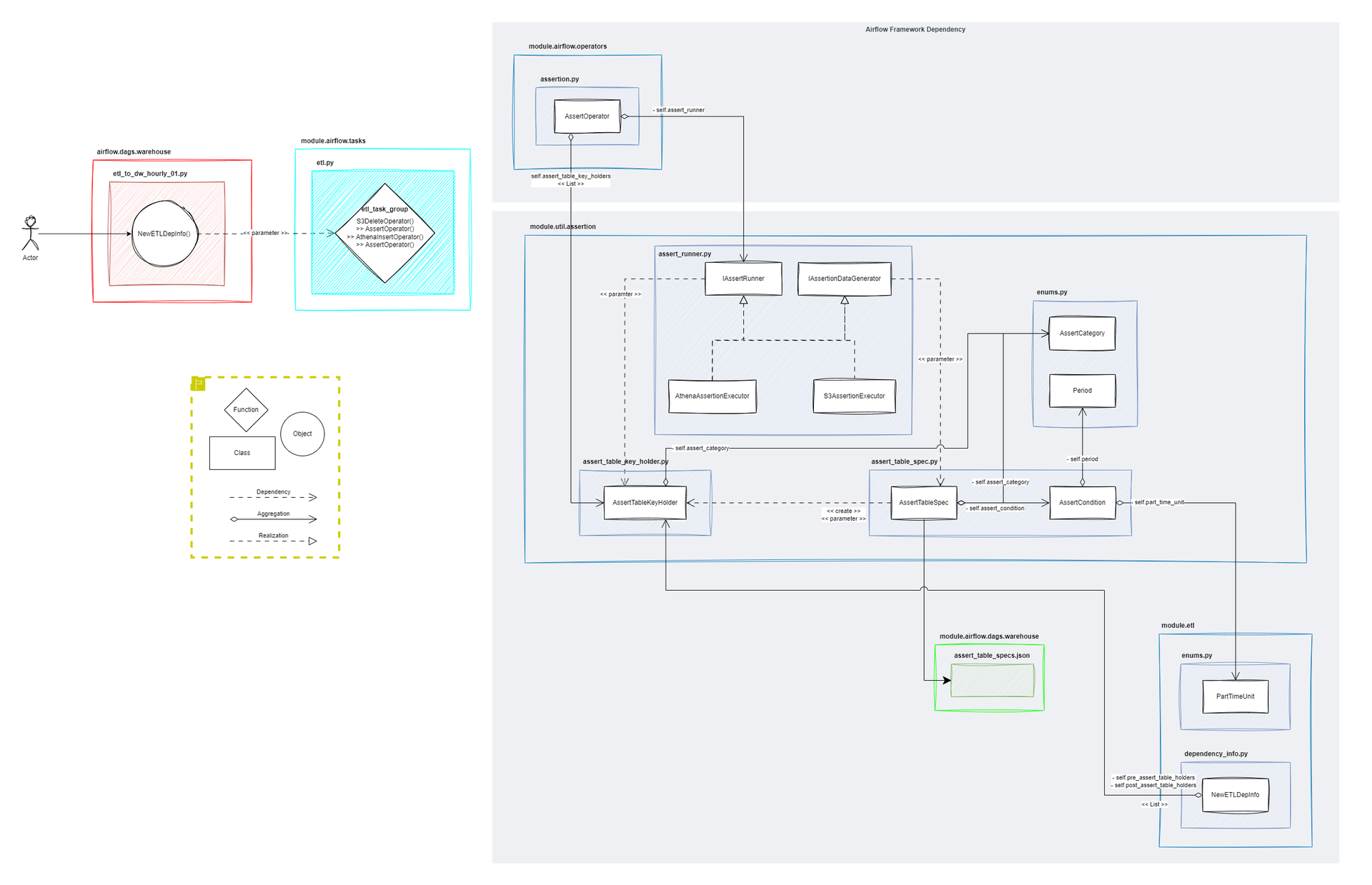
B. AssertRunner: ISP, OCP, DIP
OOP의 SOLID Principle을 지켜서 확장성 있는 코드를 개발한다.
책임과 역할의 분리
a. ISP (Interface Segregation Principle)
여러개의 기능을 가진 하나의 인터페이스보다 하나의 기능을 가진 여러개의 인터페이스가 낫다.
Assert를 execute하는 IAssertRunner와 Assert Data를 build하는 IAssertionDataGenerator로 인터페이스를 분리하였다. 이로써 인터페이스의 기능별로 역할이 분리되게 된다.

b. OCP (Open Closed Principle)
소프트웨어 요소는 확장에는 열려 있으나 변경에는 닫혀 있어야 한다.
인터페이스를 구현한 클래스를 만들어서 새로운 기능을 구현한다.

b. DIP (Dependency Inversion Principle)
추상화에 의존해야지, 구체화에 의존하면 안된다.
인터페이스를 구현한 구체 클래스(AthenaAssertionExecutor, S3AssertionExecutor)를 모르더라도 EX-1 함수처럼 추상화에 의존하는 코드를 작성할 수 있다.
만약 객체를 생성하고 연관관계를 맺어주는 시스템(e.g. Spring Container)이 있다면, 적절한 구현 객체를 선택해준다. 이를 DI (Dependency Injection)이라고 한다.
# EX-1
def test(assert_runner: IAssertRunner):
...
다만, Airflow는 Spring Container와 같은 역할을 하지 못하기 때문에 구현 객체를 직접 생성하고 주입해줘야 한다. 이 말은 구현 객체를 변경하려면 코드를 변경해야 한다는 의미라서 OCP 원칙 DI를 위배하게 된다. (EX-2 코드를 EX-3 코드처럼 직접 수정해야 한다.)
# EX-2
a = AthenaAssertionExecutor()
test(assert_runner = a)
# EX-3
b = S3AssertionExecutor()
test(assert_runner = b)
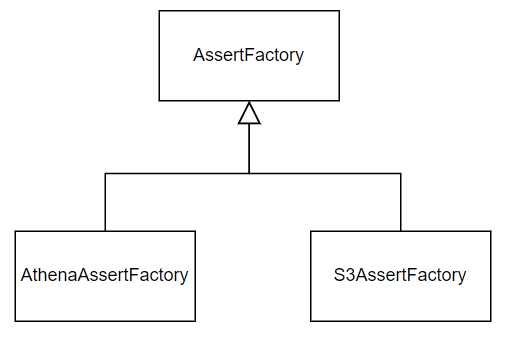
c. Factory Method Pattern
위 방식(부모 클래스에서 인터페이스를 정의하고 자식 클래스에서 인터페이스를 구현하여 구체적인 객체 처리 로직을 수행하)은 Factory Method Pattern이라고 생각할 수 있다.
Factory Method는 [사진 7]처럼 부모 클래스의 method를 자식 클래스들이 구현하는 방식인데, [사진 6]를 보면 부모 클래스의 method를 자식 클래스에서 구현하기 때문이다.
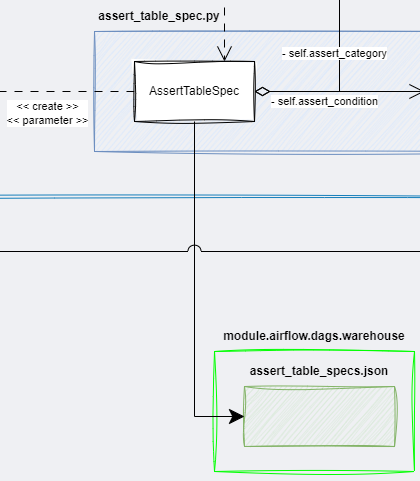
C. *_specs.json: Declarative Programming
사용자가 '무엇을' 해야하는지 명시하고 '어떻게'해야하는지는 시스템이 결정
사용자는 코드를 수정하지 않고 원하는 동작을 선언적으로 입력하면 시스템이 어떻게 동작해야할 지를 결정한다.
이로 인해 사용자와 실제 구현된 코드를 떼어놓을 수 있기 때문에 추상화 레벨이 높아진다는 점과 간결성, 유지보수성 향상 등의 장점이 있다.
e.g. 사용자는 쿼리라는 개념을 모르더라도 원하는 Asset 조건을 추가할 수 있다. 시스템은 사용자가 입력한 Assert 조건을 쿼리로 해석해서 결과를 만든다.
4. 결론
내가 직접 설계하고 구현하는 모든 과정이 재미있었다.
UML Diagram을 그리는 과정은 조금 귀찮았으나 그리고 나니 머릿속에 떠다니던 점들이 연결되는 느낌을 받았다.
처음에는 IAssertRunner 쪽만 구현하고 DAG를 생성하는 코드에서 AthenaAssertRunner객체를 생성해서 주입해주는 방식으로 개발했다. 개발하고 나니 DAG를 생성하는 코드가 너무 더럽고 유지보수하기 힘들 것 같다는 생각이 들었다.
이 방식보다는 json 파일에 사용자가 원하는 행동을 선언하고 DAG를 생성하는 코드에 문자열만 입력하면 시스템이 알아서 동작하는 방식이 더 유지보수하기 편리하겠다는 생각이 들었다. (이 과정에서 많은 조언을 해주신 리더님께 감사하다.)
구조를 바꾸려고 생각하고 간략하게 다이어그램을 그렸는데, 지금 그린 다이어그램에서 많은 것들이 생략되었었다. 처음부터 완벽하게 틀을 짜고 구현하고 싶었는데 쉽지 않았다. 그래도 계속 시도하다보면 자연스럽게 초기 설계와 일치하는 코드를 구현하게 될지 않을까? (이게 더 안좋은건가?)