Chapter 4: Iceberg 테이블 성능 최적화
개요
3장에서 살펴본 것처럼, Apache Iceberg 테이블은 쿼리 엔진이 더 나은 성능을 위해 더 스마트한 쿼리 플랜을 생성할 수 있도록 하는 메타데이터 레이어를 제공합니다. 그러나 이 메타데이터는 데이터 성능을 최적화할 수 있는 방법의 시작에 불과합니다.
사용할 수 있는 다양한 최적화 레버에는 데이터파일 수 줄이기, 데이터 정렬, 테이블 파티셔닝, 행 수준 업데이트 처리, 메트릭 수집, 외부 요인 등이 있습니다. 이러한 레버들은 데이터 성능 향상에 중요한 역할을 하며, 이 장에서는 각각을 탐구하고 잠재적인 성능 저하를 해결하며 가속화 인사이트를 제공합니다.
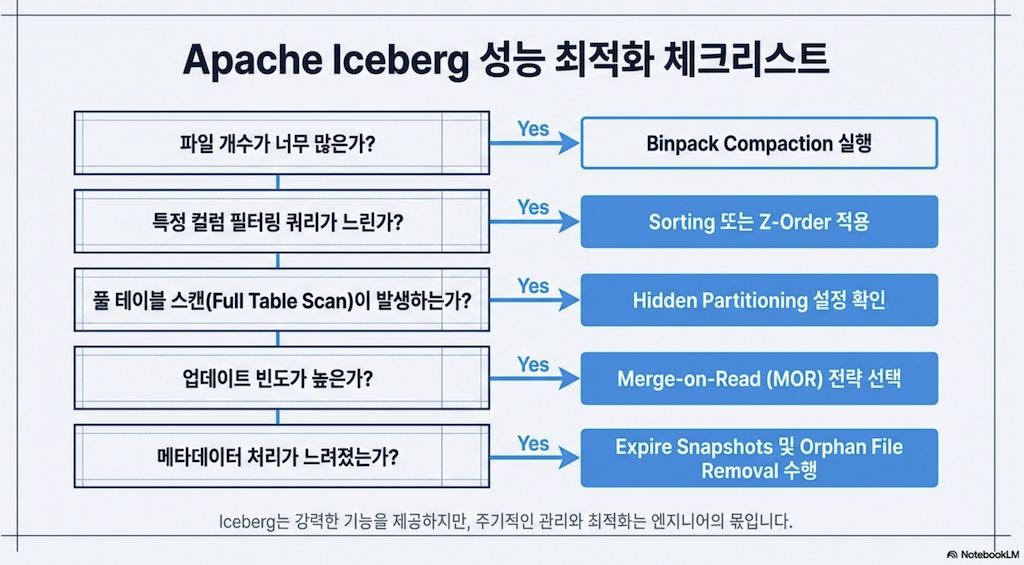
1. 컴팩션 (Compaction)
1.1 컴팩션의 필요성
모든 절차나 프로세스는 시간 비용이 듭니다. 즉, 더 긴 쿼리와 더 높은 컴퓨팅 비용을 의미합니다. 다시 말해, 무언가를 하기 위해 더 많은 단계를 거쳐야 할수록 그것을 하는 데 더 오래 걸립니다.
Apache Iceberg 테이블을 쿼리할 때, 각 파일을 열고 스캔한 다음 작업이 완료되면 파일을 닫아야 합니다. 쿼리에서 스캔해야 할 파일이 많을수록 이러한 파일 작업이 쿼리에 미치는 비용이 커집니다.
이 문제는 스트리밍 또는 "실시간" 데이터 환경에서 더욱 악화됩니다. 데이터가 생성되는 대로 수집되어 각각 몇 개의 레코드만 있는 많은 파일이 생성되기 때문입니다.
반면, 배치 수집은 하루치 또는 일주일치 레코드를 하나의 작업으로 수집할 수 있어, 더 잘 정리된 파일로 데이터를 쓰는 방법을 보다 효율적으로 계획할 수 있습니다.
배치 수집을 사용하더라도 "작은 파일 문제(small files problem)"가 발생할 수 있습니다. 너무 많은 작은 파일은 다음과 같은 이유로 스캔 속도와 성능에 영향을 미칩니다:
더 많은 파일 작업 수행
읽어야 할 메타데이터 증가 (각 파일에 메타데이터가 있음)
정리 및 유지보수 작업 시 삭제해야 할 파일 증가
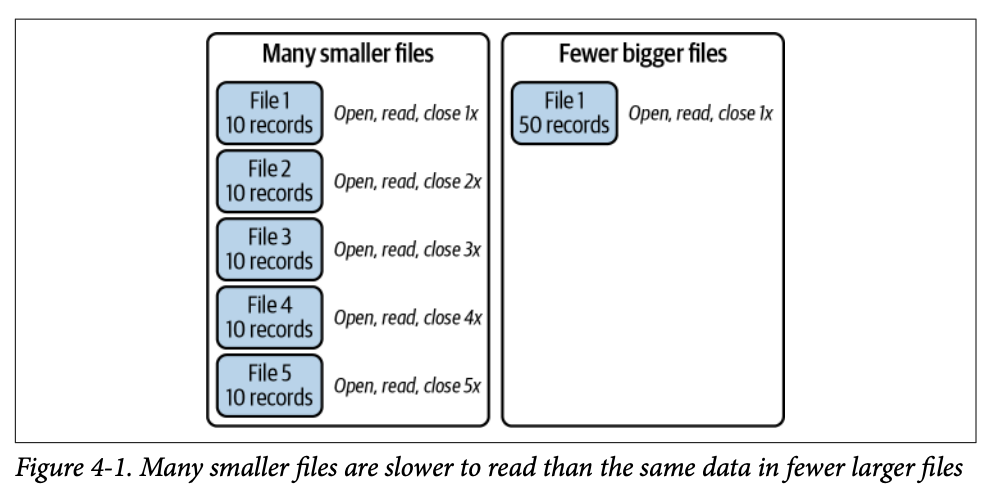
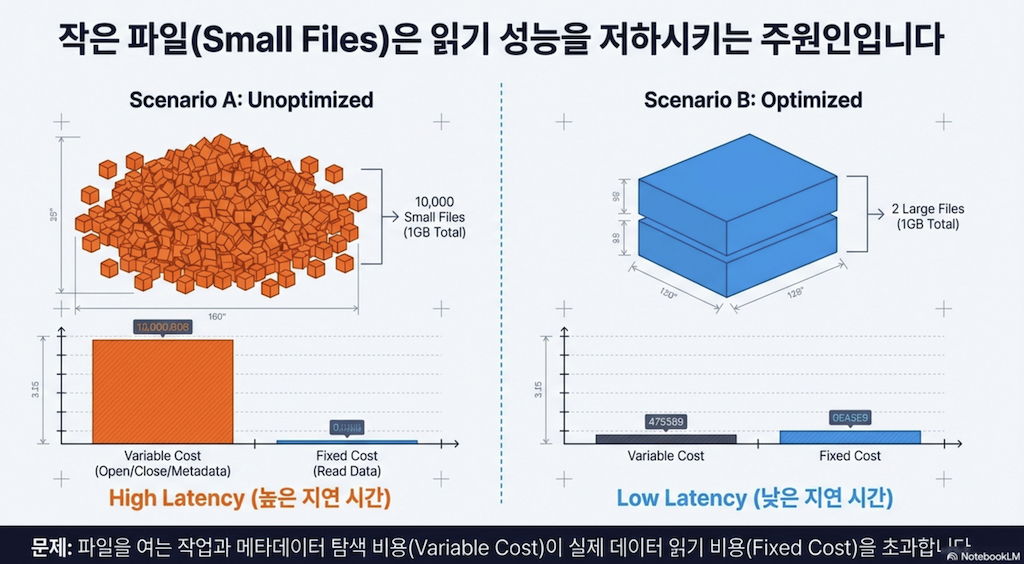
핵심 개념: 데이터를 읽을 때 피할 수 없는 고정 비용(쿼리와 관련된 특정 데이터 읽기)과 피할 수 있는 가변 비용(파일 접근을 위한 파일 작업)이 있습니다. 이 장에서 논의할 다양한 전략을 사용하면 가변 비용을 최대한 줄일 수 있습니다.
1.2 컴팩션의 개념
이 문제의 해결책은 모든 작은 파일들의 데이터를 주기적으로 가져와 더 적은 수의 큰 파일로 다시 쓰는 것입니다 (데이터파일 수에 비해 매니페스트가 너무 많은 경우 매니페스트도 다시 쓸 수 있습니다). 이 프로세스를 컴팩션(compaction)이라고 합니다. 많은 파일을 적은 수로 압축하는 것입니다.
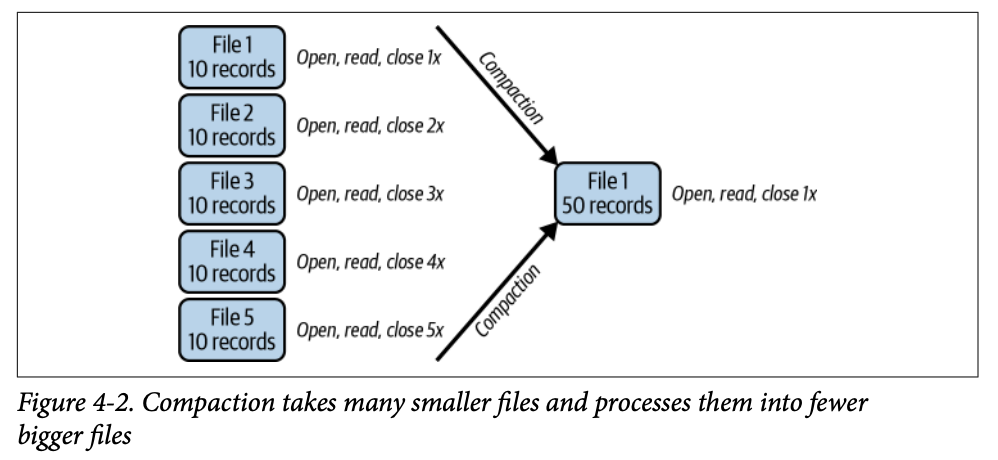
1.3 Hands-on with Compaction
해결책이 간단해 보이지만 Java나 Python으로 광범위한 코드를 작성해야 할 것이라고 생각할 수 있습니다. 다행히 Apache Iceberg의 Actions 패키지에는 여러 유지보수 프로시저가 포함되어 있습니다 (Actions 패키지는 특히 Apache Spark용이지만, 다른 엔진도 자체 유지보수 작업 구현을 만들 수 있습니다).
SparkActions의 주요 옵션들
옵션 | 설명 |
|---|---|
| 특정 파일만 대상으로 하는 표현식 |
| 정렬된 순서로 데이터를 재작성 |
| 단일 설정 지정 |
| 맵으로 여러 설정 지정 |
| 목표 파일 크기 (바이트) |
| 최대 파일 그룹 크기 |
| 동시 파일 그룹 재작성 최대 수 |
| 부분 진행 활성화 여부 |
| 부분 진행 시 최대 커밋 수 |
Spark SQL 확장을 사용한 컴팩션 예제
-- rewrite_data_files 프로시저를 사용한 컴팩션 작업
CALL catalog.system.rewrite_data_files(
table => 'musicians',
strategy => 'binpack',
where => 'genre = "rock"',
options => map(
'rewrite-job-order','bytes-asc',
'target-file-size-bytes','1073741824', -- 1GB
'max-file-group-size-bytes','10737418240' -- 10GB
)
)이 시나리오에서는 musicians 테이블에 일부 데이터를 스트리밍했고 rock 밴드에 대해 많은 작은 파일이 생성된 것을 발견했습니다. 전체 테이블에 컴팩션을 실행하는 대신(시간이 많이 소요됨), 문제가 있는 데이터만 대상으로 했습니다.
참고:
where필터에서 큰따옴표 사용에 주의하세요. 필터 주변에 작은따옴표를 사용했으므로, SQL이 일반적으로 사용하는 작은따옴표 대신 문자열 내에서 큰따옴표를 사용합니다.
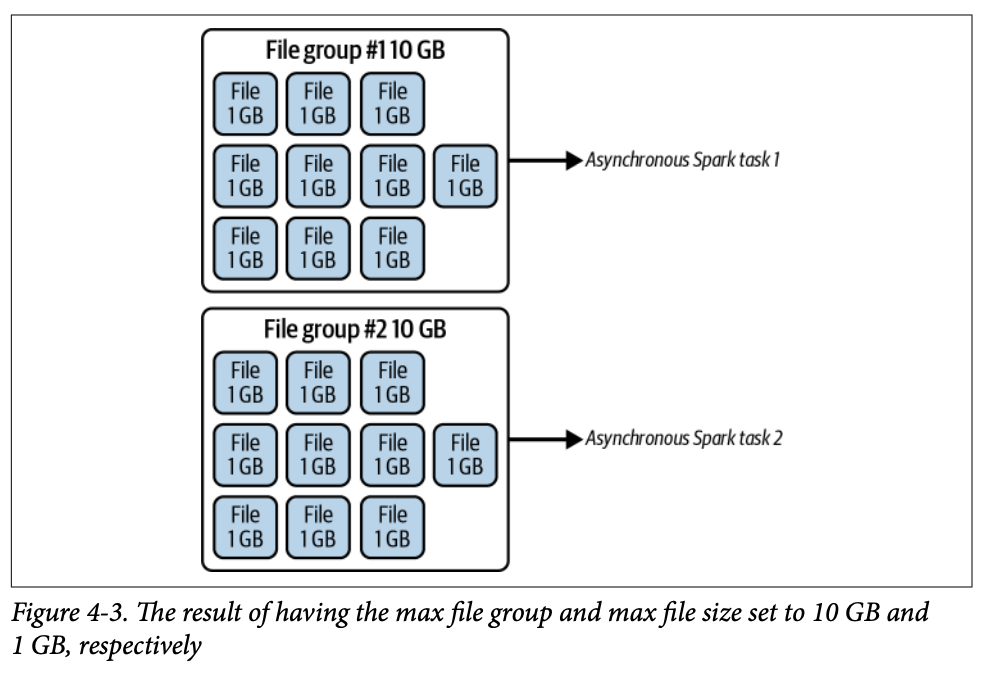
파일 그룹 (File Groups)
엔진이 컴팩션 작업에서 작성할 새 파일을 계획할 때, 이러한 파일들을 병렬로 작성될 파일 그룹으로 그룹화하기 시작합니다 (각 그룹에서 하나의 파일이 동시에 작성될 수 있음). 컴팩션 작업에서 이러한 파일 그룹의 크기와 동시에 작성할 수를 구성하여 메모리 문제를 방지할 수 있습니다.
부분 진행 (Partial Progress)
부분 진행을 사용하면 파일 그룹이 완료될 때마다 새 스냅샷이 생성됩니다. 이를 통해 쿼리가 다른 파일이 완료되는 동안 이미 컴팩션된 파일의 이점을 얻을 수 있습니다. 또한 진행 상황이 작업 완료 시 저장되고 메모리에 보관해야 하는 데이터가 줄어들어 대규모 컴팩션 작업의 OOM(Out-of-Memory) 상황을 방지하는 데 도움이 됩니다.
더 많은 스냅샷은 테이블 위치에서 저장 공간을 차지하는 더 많은 메타데이터 파일을 의미한다는 점을 명심하세요. 하지만 읽기 작업이 컴팩션 작업의 이점을 더 빨리 얻기를 원한다면 이것은 유용한 기능이 될 수 있습니다.
1.4 컴팩션 전략 (Compaction Strategies)
rewriteDataFiles 프로시저를 사용할 때 선택할 수 있는 여러 컴팩션 전략이 있습니다. 아래 표는 각 전략의 장단점을 요약합니다.
전략 | 기능 | 장점 | 단점 |
|---|---|---|---|
Binpack | 파일만 결합; 전역 정렬 없음 (태스크 내 로컬 정렬은 수행) | 가장 빠른 컴팩션 작업 | 데이터가 클러스터링되지 않음 |
Sort | 태스크 할당 전에 하나 이상의 필드로 순차적 정렬 (예: 필드 a로 정렬, 그 안에서 필드 b로 정렬) | 자주 쿼리되는 필드로 클러스터링된 데이터는 훨씬 빠른 읽기 시간 제공 | binpack에 비해 더 긴 컴팩션 작업 시간 |
Z-order | 태스크 할당 전에 동등한 가중치를 가진 여러 필드로 정렬 (이 범위의 X와 Y 값은 한 그룹에, 다른 범위는 다른 그룹에) | 쿼리가 여러 필드의 필터에 자주 의존하는 경우 읽기 시간을 더욱 개선 | binpack에 비해 더 긴 컴팩션 작업 시간 |
참고: Apache Iceberg 테이블에 정렬 순서가 설정되어 있으면, binpack을 사용하더라도 이 정렬 순서가 단일 태스크 내에서 데이터를 정렬하는 데 사용됩니다 (로컬 정렬). sort와 z-order 전략을 사용하면 쿼리 엔진이 레코드를 다른 태스크에 할당하기 전에 데이터를 정렬하여 태스크 간 데이터 클러스터링을 최적화합니다.
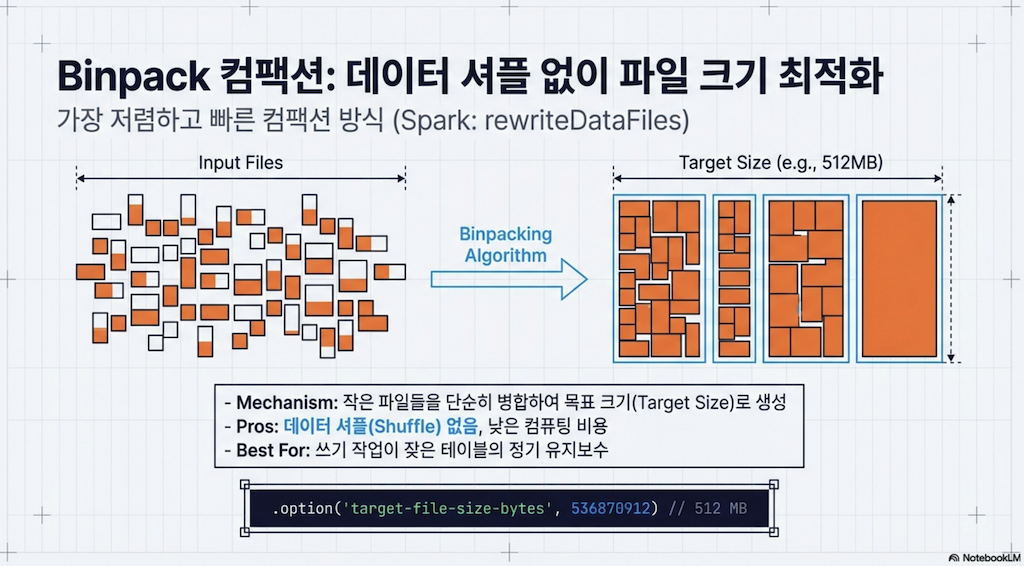
Binpack 전략
기본적으로 rewriteDataFiles 프로시저는 binpack 전략을 사용합니다. 이 전략은 데이터파일을 병합하는 데 초점을 맞추며, 데이터의 순서를 변경하지 않습니다. 이 방법은 단순히 여러 파일을 더 적은 수의 파일로 압축할 때 필요한 최소한의 작업입니다.
binpack 전략은 본질적으로 파일 크기 외에 데이터가 어떻게 구성되는지에 대한 다른 고려 없이 순수한 컴팩션입니다. 세 가지 전략 중 binpack이 가장 빠릅니다. 작은 파일의 내용을 목표 크기의 큰 파일에 그냥 쓸 수 있기 때문입니다. 반면 sort와 z-order는 파일 그룹을 쓰기 위해 할당하기 전에 데이터를 정렬해야 합니다. 이는 스트리밍 데이터가 있고 SLA(서비스 수준 계약)를 충족하는 속도로 컴팩션을 실행해야 할 때 특히 유용합니다.
1.5 컴팩션 자동화 (Automating Compaction)
컴팩션 작업을 수동으로 실행하면 모든 SLA를 충족하기 어려울 수 있으므로, 이러한 프로세스를 자동화하는 방법을 찾는 것이 실질적인 이점이 될 수 있습니다:
오케스트레이션 도구 사용: Airflow, Dagster, Prefect, Argo, Luigi 등을 사용하여 수집 작업 완료 후 또는 특정 시간이나 주기적 간격으로 Spark나 Dremio와 같은 엔진에 적절한 SQL을 전송
서버리스 함수: 클라우드 오브젝트 스토리지에 데이터가 도착한 후 작업을 트리거
크론 작업: 특정 시간에 적절한 작업을 실행하도록 설정
또한 Dremio Arctic과 Tabular과 같이 컴팩션을 포함한 자동화된 테이블 유지보수 기능을 갖춘 관리형 Apache Iceberg 카탈로그 서비스도 있습니다.
2. 정렬 (Sorting)
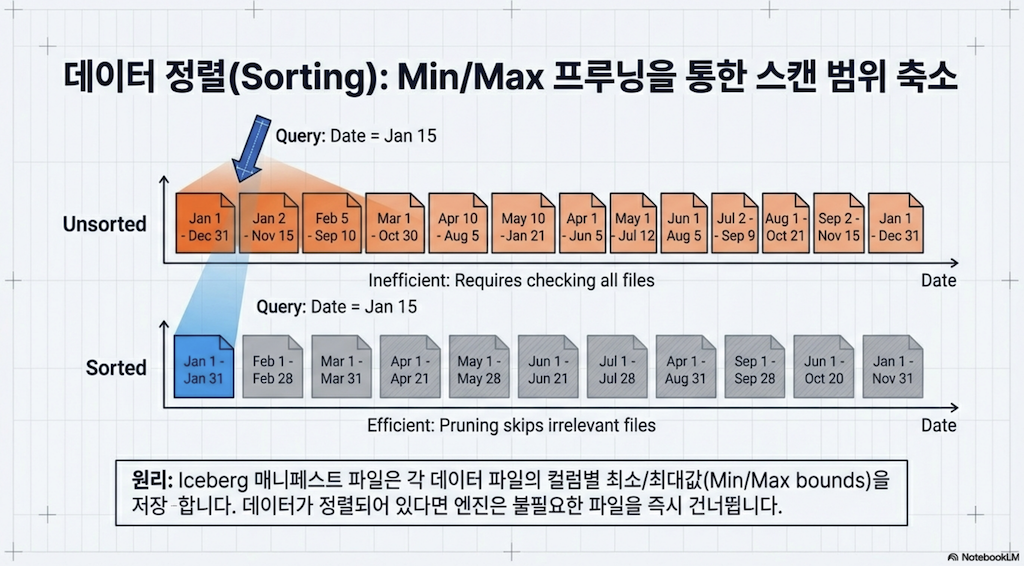
2.1 정렬의 이점
정렬 또는 "클러스터링"은 쿼리에 있어 매우 특별한 이점이 있습니다: 쿼리에 필요한 데이터를 얻기 위해 스캔해야 하는 파일 수를 제한하는 데 도움이 됩니다. 데이터를 정렬하면 유사한 값을 가진 데이터가 더 적은 파일에 집중되어 보다 효율적인 쿼리 계획이 가능해집니다.
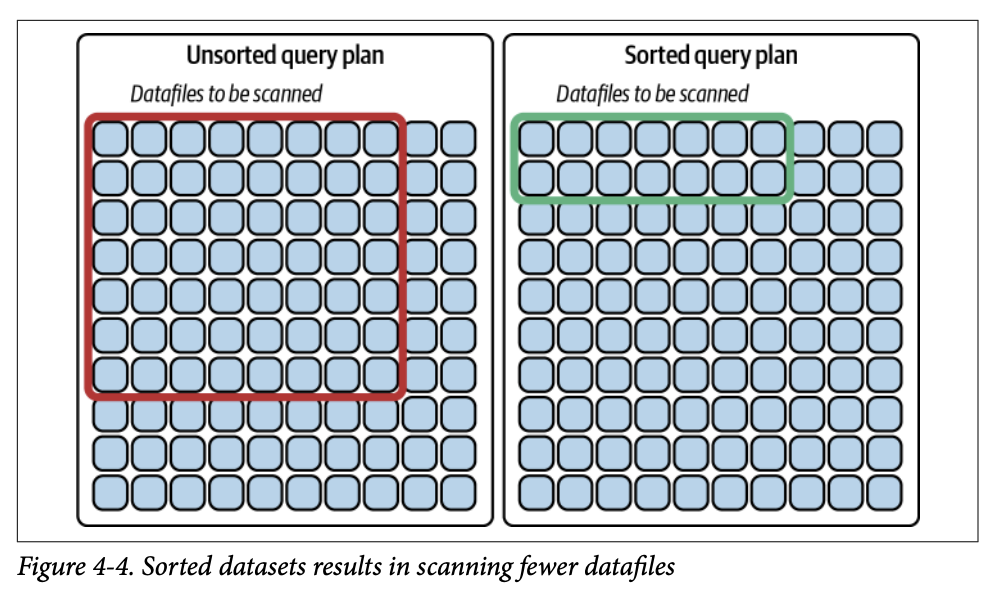
예시: NFL 팀의 모든 선수를 나타내는 데이터셋이 특별한 순서 없이 100개의 Parquet 파일에 걸쳐 있다고 가정합니다. Detroit Lions 선수만 쿼리하면, 100개의 레코드 중 Detroit Lions 선수가 단 하나뿐인 파일이 있더라도 해당 파일은 쿼리 플랜에 추가되어 스캔되어야 합니다. 이는 최대 53개의 파일(NFL 팀의 최대 선수 수)을 스캔해야 할 수 있음을 의미합니다.
팀 이름을 알파벳순으로 정렬하면 모든 Detroit Lions 선수는 약 4개의 파일에 있어야 합니다 (100개 파일 ÷ 32개 NFL 팀 = 3.125). 따라서 데이터를 정렬함으로써 스캔해야 할 파일 수를 53개에서 4개로 줄일 수 있습니다.
2.2 테이블 생성 시 정렬 설정
테이블을 생성하는 두 가지 주요 방법:
방법 1: 표준 CREATE TABLE 문
-- Spark SQL
CREATE TABLE catalog.nfl_players (
id bigint,
player_name varchar,
team varchar,
num_of_touchdowns int,
num_of_yards int,
player_position varchar,
player_number int
)방법 2: CREATE TABLE…AS SELECT (CTAS) 문
-- Spark SQL
CREATE TABLE catalog.nfl_players
AS (SELECT * FROM non_iceberg_teams_table);2.3 정렬 순서 설정
테이블 생성 후 정렬 순서를 설정합니다. 이 속성을 지원하는 모든 엔진은 쓰기 전에 데이터를 정렬하는 데 사용하며, sort 컴팩션 전략 사용 시 기본 정렬 필드로도 사용됩니다:
ALTER TABLE catalog.nfl_teams WRITE ORDERED BY team;CTAS를 수행하는 경우 AS 쿼리에서 데이터를 정렬합니다:
CREATE TABLE catalog.nfl_teams
AS (SELECT * FROM non_iceberg_teams_table ORDER BY team);
ALTER TABLE catalog.nfl_teams WRITE ORDERED BY team;INSERT INTO에서도 지정할 수 있습니다:
INSERT INTO catalog.nfl_teams
SELECT *
FROM staging_table
ORDER BY team2.4 Sort 컴팩션 전략
NFL 데이터셋이 매년 팀 로스터 변경을 위해 업데이트된다면, 여러 쓰기 작업에서 Lions와 Packers 선수를 분할하는 많은 파일이 생길 수 있습니다. 이는 현재 연도의 새 Lions 선수를 포함하는 새 파일을 작성해야 하기 때문입니다. 이때 sort 컴팩션 전략이 유용합니다.
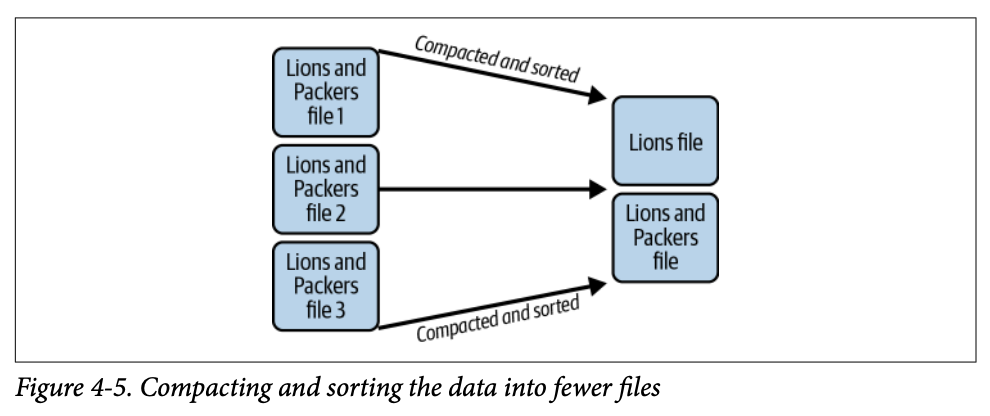
sort 컴팩션 전략은 작업 대상 모든 파일에 걸쳐 데이터를 정렬합니다:
CALL catalog.system.rewrite_data_files(
table => 'nfl_teams',
strategy => 'sort',
sort_order => 'team ASC NULLS LAST'
)
핵심 포인트: 정렬의 최대 이점을 얻으려면 최종 사용자가 묻는 질문 유형을 이해하여 그들의 질문에 효과적으로 대응할 수 있도록 데이터를 정렬해야 합니다.
3. Z-order
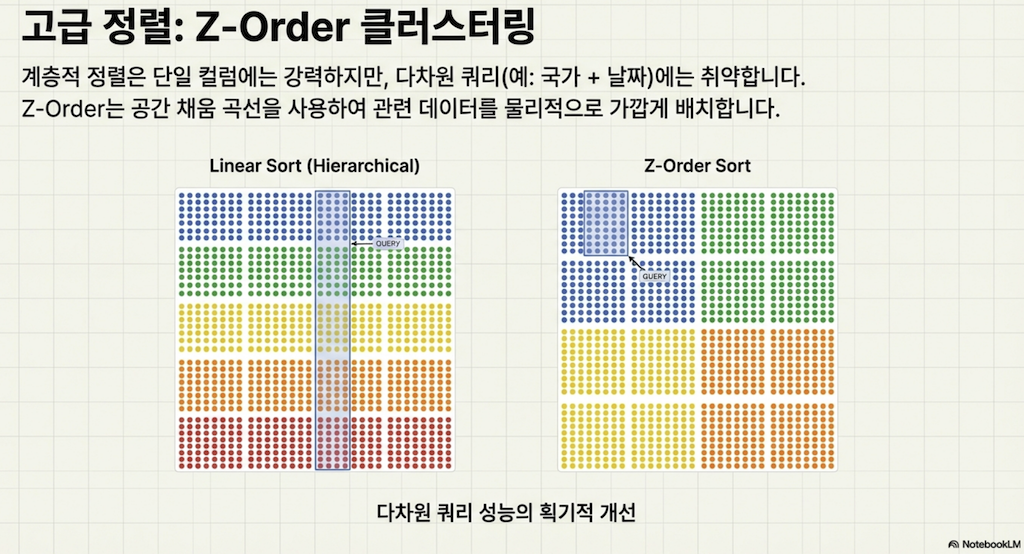
3.1 Z-order의 개념
테이블을 쿼리할 때 여러 필드가 우선순위인 경우가 있으며, 이때 z-order 정렬이 매우 유용할 수 있습니다. z-order 정렬은 여러 데이터 포인트로 데이터를 정렬하여 엔진이 최종 쿼리 플랜에서 스캔할 파일을 줄일 수 있는 더 큰 능력을 제공합니다.
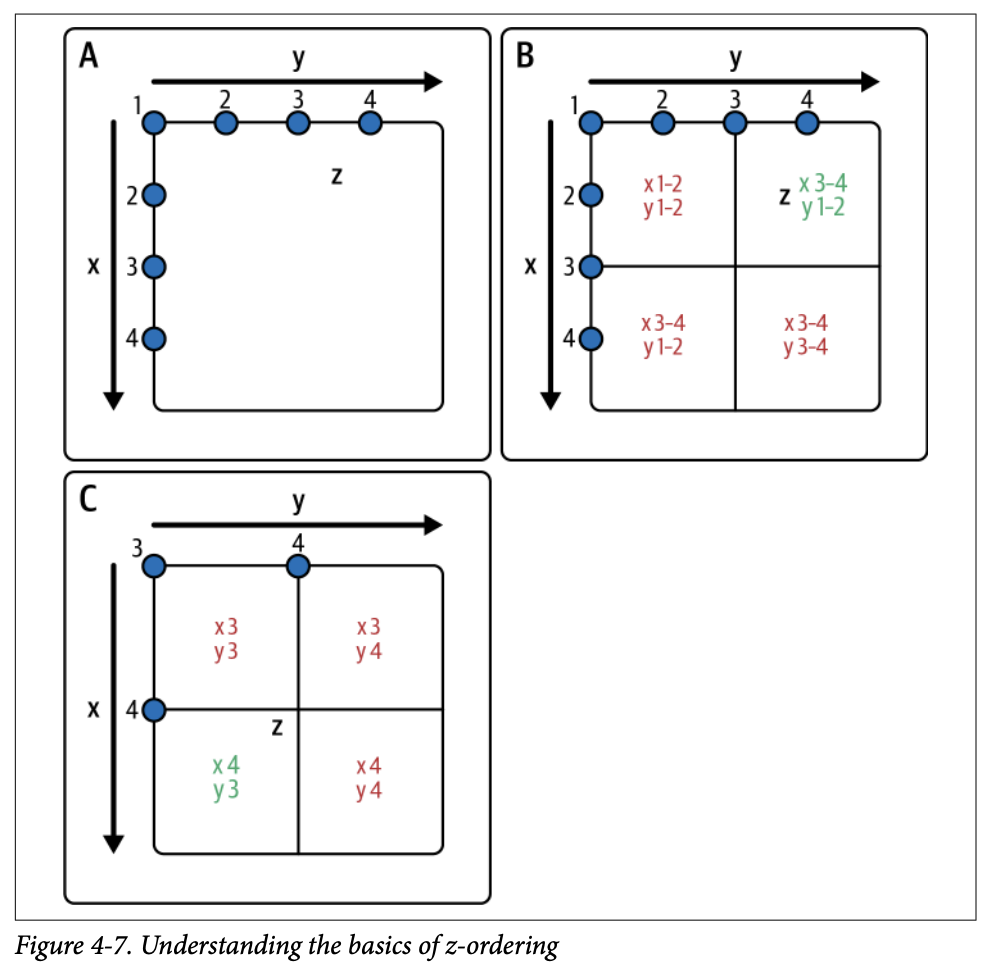
3.2 Z-order의 작동 방식
4×4 그리드에서 항목 Z를 찾으려 한다고 상상해 보세요. 값(z)이 3.5와 같다고 할 때:
X와 Y 값의 범위에 따라 필드를 4개의 사분면으로 나눕니다
검색하려는 데이터가 z-order로 정렬된 필드에 기반한다면, 데이터의 큰 부분 검색을 피할 수 있습니다
해당 사분면을 더 세분화하고 사분면 내 데이터에 또 다른 z-order 정렬을 적용할 수 있습니다
검색이 여러 요소(X와 Y)에 기반하므로, 이 접근 방식을 취함으로써 검색 가능한 영역의 75%를 제거할 수 있습니다
3.3 Z-order 실제 예시
의료 코호트 연구에 참여한 모든 사람의 데이터셋이 있고, 나이와 키로 코호트의 결과를 정리하려 한다면 z-order가 매우 유용할 수 있습니다.
특정 사분면에 속하는 데이터는 동일한 데이터파일에 있게 되어, 다른 연령/키 그룹에 대한 분석을 실행할 때 스캔할 파일을 정말로 줄일 수 있습니다. 키가 6피트이고 나이가 60세인 사람을 검색하면, 다른 세 사분면에 속하는 데이터를 가진 데이터파일을 즉시 제거할 수 있습니다.
데이터파일은 네 가지 범주로 분류됩니다:
A: Age 1–50, Height 1–5 레코드가 있는 파일
B: Age 51–100, Height 1–5 레코드가 있는 파일
C: Age 1–50, Height 5–10 레코드가 있는 파일
D: Age 51–100, Height 5–10 레코드가 있는 파일
60세이고 6피트인 사람을 검색하면, A, B, C 범주의 모든 데이터파일이 제거되어 스캔되지 않습니다. 나이만으로 검색하더라도 최소 네 사분면 중 두 개를 제거할 수 있어 클러스터링의 이점을 볼 수 있습니다.
3.4 Z-order 컴팩션 작업 실행
CALL catalog.system.rewrite_data_files(
table => 'people',
strategy => 'sort',
sort_order => 'zorder(age,height)'
)sort 및 z-order 컴팩션 전략을 사용하면 데이터가 존재하는 파일 수를 줄일 수 있을 뿐만 아니라, 해당 파일의 데이터 순서가 더욱 효율적인 쿼리 계획을 가능하게 합니다.
3.5 정렬의 한계
정렬은 효과적이지만 몇 가지 과제가 있습니다:
새 데이터 수집 시: 새 데이터가 수집되면 정렬되지 않은 상태가 되며, 다음 컴팩션 작업까지 데이터는 여러 파일에 걸쳐 다소 흩어진 상태로 남습니다
파일 내 다중 값: 파일에 정렬된 필드의 여러 값에 대한 데이터가 여전히 포함될 수 있어, 특정 값의 데이터만 필요한 쿼리에 비효율적일 수 있습니다
이러한 문제를 해결하기 위해 파티셔닝을 사용합니다.
4. 파티셔닝 (Partitioning)
4.1 파티셔닝의 개념
데이터 액세스 방식에 특정 필드가 핵심적이라면, 정렬을 넘어 파티셔닝을 고려할 수 있습니다. 테이블이 파티션되면, 필드에 기반하여 순서만 정렬하는 대신, 대상 필드의 고유 값을 가진 레코드를 자체 데이터파일에 씁니다.
예시: 정치에서 유권자 데이터를 유권자의 정당 소속에 따라 자주 쿼리할 가능성이 높아, 이것이 좋은 파티션 필드가 됩니다. 이는 "Blue" 정당의 모든 유권자가 "Red", "Yellow", "Green" 정당의 유권자와 별도의 파일에 나열됨을 의미합니다. "Yellow" 정당의 유권자를 쿼리하면, 스캔하는 데이터파일에는 다른 정당의 사람이 포함되지 않습니다.
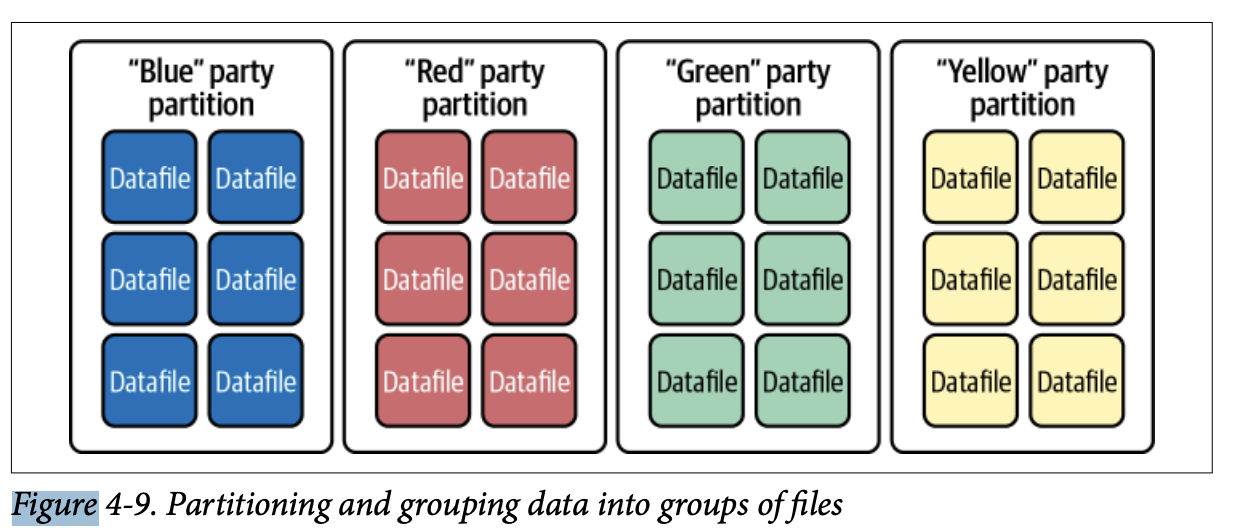
4.2 전통적인 파티셔닝의 문제점
전통적으로 특정 필드의 파생 값을 기반으로 테이블을 파티셔닝하려면 별도로 관리해야 하는 추가 필드를 생성해야 했고, 사용자가 쿼리할 때 해당 별도 필드에 대한 지식이 필요했습니다:
날짜 기반 파티셔닝: 타임스탬프 열의 일, 월, 또는 연도로 파티셔닝하려면 년, 월, 또는 일을 분리하여 표현하는 타임스탬프 기반의 추가 열을 생성해야 했습니다
텍스트 기반 파티셔닝: 텍스트 값의 첫 글자로 파티셔닝하려면 해당 글자만 있는 추가 열을 생성해야 했습니다
버킷 파티셔닝: 해시 함수에 기반하여 레코드를 균등하게 분배하는 일정 수의 분할(버킷)로 파티셔닝하려면 레코드가 속한 버킷을 명시하는 추가 열을 생성해야 했습니다
문제점: 엔진은 원래 필드와 파생 필드 간의 관계를 인식하지 못합니다. 이는 다음 쿼리가 파티셔닝의 이점을 받지만:
SELECT * FROM MYTABLE WHERE time BETWEEN '2022-07-01 00:00:00' AND '2022-07-31 00:00:00'
AND month = 7;사용자는 종종 이 우회 열을 인식하지 못합니다(인식해야 할 필요도 없습니다). 이는 대부분의 경우 사용자가 다음과 유사한 쿼리를 발행하여 전체 테이블 스캔이 발생하고, 쿼리 시간이 훨씬 오래 걸리고 훨씬 더 많은 리소스를 소비함을 의미합니다:
SELECT * FROM MYTABLE WHERE time BETWEEN '2022-07-01 00:00:00' AND '2022-07-31 00:00:00';4.3 히든 파티셔닝 (Hidden Partitioning)
Apache Iceberg는 파티셔닝을 상당히 다르게 처리하여 테이블을 파티셔닝으로 최적화할 때 이러한 많은 문제점을 해결합니다. 이 접근 방식의 결과적인 기능을 히든 파티셔닝이라고 합니다.
Iceberg가 파티셔닝을 추적하는 방식에서 시작됩니다. 파일이 물리적으로 배치되는 방식에 의존하는 대신, Iceberg는 스냅샷과 매니페스트 수준에서 파티션 값의 범위를 추적하여 많은 수준의 새로운 유연성을 허용합니다:
변환 값을 기반으로 파티셔닝하기 위해 추가 열을 생성할 필요 없이, 쿼리 계획 시 엔진과 도구가 메타데이터에서 적용할 수 있는 내장 변환을 사용할 수 있습니다
이러한 변환을 사용할 때 추가 열이 필요하지 않으므로 데이터파일에 저장하는 양이 줄어듭니다
메타데이터가 원래 열에 대한 변환을 엔진이 인식할 수 있게 하므로, 원래 열만으로 필터링해도 파티셔닝의 이점을 얻을 수 있습니다
예시: 월별로 파티션된 테이블을 생성하면:
CREATE TABLE catalog.MyTable (...) PARTITIONED BY months(time) USING iceberg;다음 쿼리가 파티셔닝의 이점을 받습니다:
SELECT * FROM MYTABLE WHERE time BETWEEN '2022-07-01 00:00:00' AND '2022-07-31 00:00:00';4.4 파티션 변환 함수
파티셔닝 계획 시 사용 가능한 여러 변환:
변환 | 설명 |
|---|---|
| 연도만 |
| 월과 연도 |
| 일, 월, 연도 |
| 시간, 일, 월, 연도 |
| 값을 잘라서 파티셔닝 |
| 해시 함수를 사용하여 지정된 버킷 수로 분배 |
year, month, day, hour 변환은 타임스탬프 열에서 작동합니다. month를 지정하면 메타데이터에서 추적되는 파티션 값은 타임스탬프의 월과 연도를 반영하고, day를 사용하면 연도, 월, 일을 반영하므로 더 세분화된 파티셔닝을 위해 여러 변환을 사용할 필요가 없습니다.
truncate 변환 예시:
-- 사람 이름의 첫 글자를 기반으로 파티셔닝
CREATE TABLE catalog.MyTable (...) PARTITIONED BY truncate(name, 1) USING iceberg;bucket 변환 예시:
-- 우편번호 기반 유권자 데이터 파티셔닝 (너무 많은 고유 값이 있는 경우)
CREATE TABLE catalog.voters (...) PARTITIONED BY bucket(24, zip) USING iceberg;모든 버킷에 여러 우편번호가 포함되지만, 적어도 특정 우편번호를 찾으면 전체 테이블 스캔이 아닌 검색하는 우편번호가 포함된 버킷만 스캔하면 됩니다.
4.5 파티션 진화 (Partition Evolution)
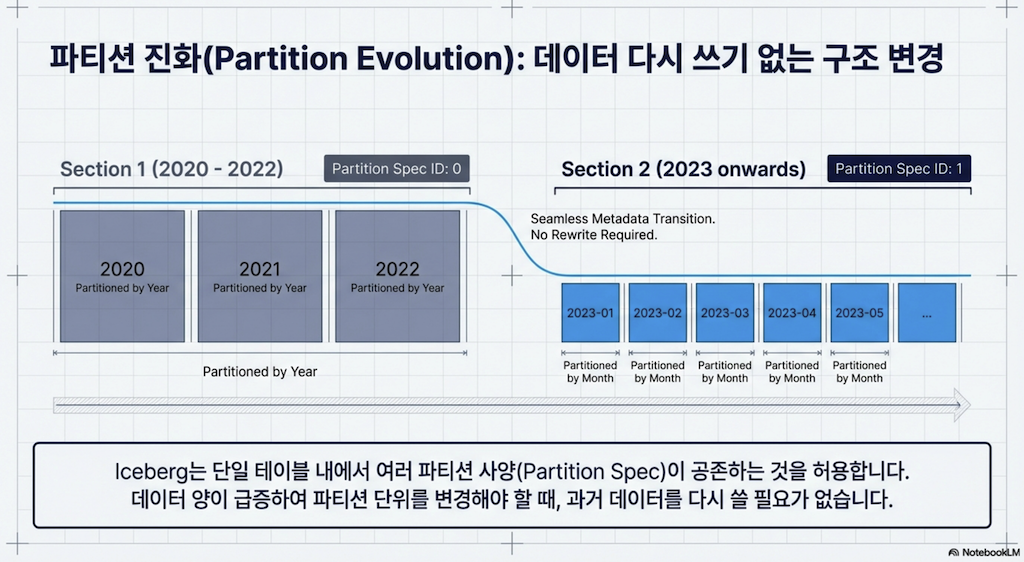
전통적인 파티셔닝의 또 다른 과제는 파일이 하위 디렉토리로 배치되는 물리적 구조에 의존했기 때문에, 테이블이 파티션되는 방식을 변경하려면 전체 테이블을 다시 작성해야 했다는 것입니다. 이는 데이터와 쿼리 패턴이 진화하면서 피할 수 없는 문제가 되어, 데이터를 파티션하고 정렬하는 방법을 재고해야 합니다.
Apache Iceberg는 메타데이터 추적 파티셔닝으로 이 문제를 해결합니다. 메타데이터가 파티션 값뿐만 아니라 과거 파티션 체계도 추적하기 때문에 파티션 체계가 진화할 수 있습니다.
예시:
-- 회원 등록 연도별로 파티션된 테이블
CREATE TABLE catalog.members (...) PARTITIONED BY years(registration_ts) USING iceberg;수년 후, 회원 성장 속도가 월별로 레코드를 세분화할 가치가 있게 되면:
ALTER TABLE catalog.members ADD PARTITION FIELD months(registration_ts)더 이상 특정 필드로 파티셔닝하지 않으려면:
ALTER TABLE catalog.members DROP PARTITION FIELD bucket(24, id);핵심 포인트:
파티셔닝 체계가 업데이트되면 앞으로 테이블에 쓰이는 새 데이터에만 적용되므로 기존 데이터를 다시 쓸 필요가 없습니다
rewriteDataFiles프로시저로 다시 쓴 모든 데이터는 새 파티셔닝 체계를 사용하여 다시 쓰입니다이전 데이터를 이전 체계로 유지하려면 컴팩션 작업에서 적절한 필터를 사용하여 다시 쓰지 않도록 해야 합니다
4.6 Hive vs Iceberg 파티션 조회 방식 비교
구분 | Hive Table Format | Iceberg |
|---|---|---|
파티션 컬럼 | 별도 컬럼 존재 (year, month, day 등) | 별도 컬럼 없음 |
쿼리 시 | 파티션 컬럼 직접 명시 필요 | 원본 컬럼으로 필터링 (자동 프루닝) |
파티션 정보 조회 |
| 메타데이터 테이블 ( |
파티션 변경 | 테이블 재작성 필요 | 메타데이터만 변경 (Partition Evolution) |
Iceberg의 히든 파티셔닝은 사용자에게 파티션 구조를 숨기면서도, 메타데이터 테이블을 통해 관리자/엔지니어가 파티션 상태를 모니터링하고 최적화할 수 있게 해줍니다.
쿼리 예시
Hive Table Format
-- 별도 파티션 컬럼이 실제로 존재
SELECT * FROM orders WHERE year = 2024 AND month = 1 AND day = 15;
-- 파티션 컬럼을 직접 명시해야 파티션 프루닝 적용Iceberg (Hidden Partitioning)
-- 원본 컬럼만으로 쿼리 (파티션 프루닝 자동 적용)
SELECT * FROM orders WHERE order_ts BETWEEN '2024-01-15 00:00:00' AND '2024-01-15 23:59:59';Iceberg는 메타데이터가 order_ts와 day(order_ts) 변환 간의 관계를 알고 있어서, 원본 타임스탬프 컬럼으로 필터링해도 자동으로 파티션 프루닝이 적용됩니다.
Iceberg 파티션 메타데이터 조회 방법
1. partitions 메타데이터 테이블
-- Spark SQL
SELECT * FROM my_catalog.table.partitions;
-- Trino
SELECT * FROM "test_table$partitions";partitions 테이블 스키마:
필드명 | 데이터 타입 | 예시 값 | 설명 |
|---|---|---|---|
| List |
| 실제 파티션 값 |
| Int |
| 파티션 스펙 ID |
| Int |
| 파티션 내 레코드 수 |
| Int |
| 파티션 내 파일 수 |
| Int |
| 위치 삭제 레코드 수 |
| Int |
| 위치 삭제 파일 수 |
| Int |
| 동등 삭제 레코드 수 |
| Int |
| 동등 삭제 파일 수 |
2. files 메타데이터 테이블 (파일별 파티션 정보)
-- Spark SQL
SELECT partition, file_path, record_count, file_size_in_bytes
FROM my_catalog.table.files;
-- Dremio
SELECT * FROM TABLE(table_files('catalog.table'));실용적인 파티션 조회 쿼리 예시
파티션별 파일 수 확인 (컴팩션 대상 식별)
SELECT partition, file_count
FROM catalog.table.partitions;파티션별 총 크기 확인
SELECT partition, SUM(file_size_in_bytes) AS partition_size
FROM catalog.table.files
GROUP BY partition;파티션 스펙별 파티션 수 확인 (파티션 진화 후)
SELECT
spec_id,
COUNT(*) as partition_count
FROM
catalog.table.partitions
GROUP BY
spec_id;컴팩션이 필요한 파티션 식별
SELECT
partition,
COUNT(*) AS num_files,
AVG(file_size_in_bytes) AS avg_file_size
FROM
catalog.table.files
GROUP BY
partition
ORDER BY
num_files DESC,
avg_file_size ASC;4.7 기타 파티셔닝 고려사항
테이블 마이그레이션 시 파티션 변환
migrate 프로시저(13장에서 논의)를 사용하여 Hive 테이블을 마이그레이션할 때, 현재 파생 열(예: 같은 테이블의 타임스탬프 열에 기반한 월 열)로 파티션되어 있지만 Apache Iceberg에 Iceberg 변환을 대신 사용해야 함을 표현하고 싶을 수 있습니다. 이를 위해 REPLACE PARTITION 명령을 사용할 수 있습니다:
sql
ALTER TABLE catalog.members REPLACE PARTITION FIELD registration_day
WITH days(registration_ts) AS day_of_registration;이 명령은 데이터파일을 변경하지 않지만, 메타데이터가 Iceberg 변환을 사용하여 파티션 값을 추적할 수 있게 해줍니다.
5. Copy-on-Write vs Merge-on-Read
5.1 개요
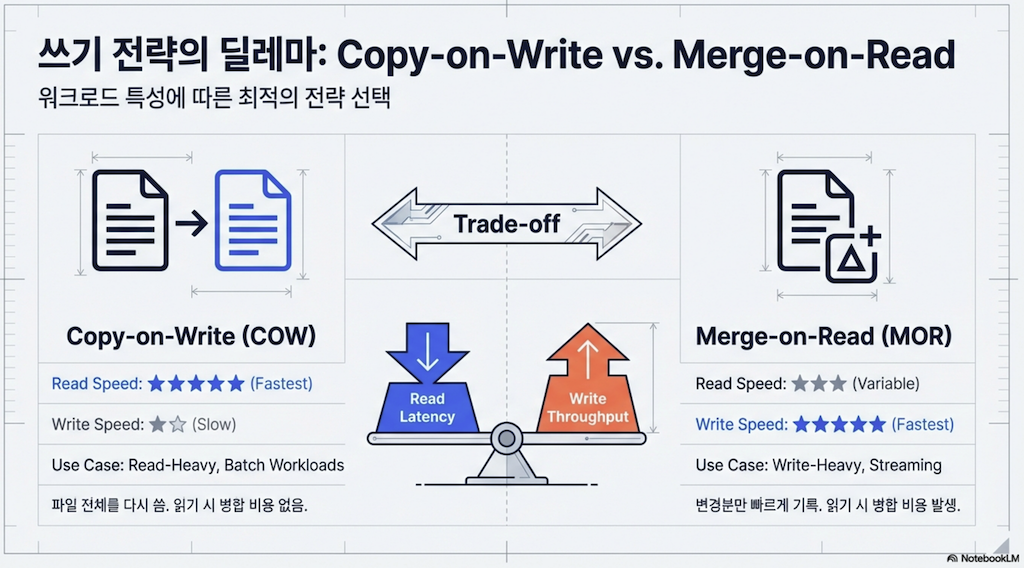
Apache Iceberg를 사용할 때 행 수준 업데이트(updates)와 삭제(deletes)가 테이블에서 어떻게 처리될지 선택해야 합니다. 선택하는 전략은 업데이트와 삭제를 많이 하는지, 테이블을 쿼리 최적화에 대해 얼마나 관심이 있는지에 따라 달라집니다.
전략 | 읽기 성능 | 업데이트/삭제 성능 | 최적화 방법 |
|---|---|---|---|
Copy-on-Write | 빠른 읽기 | 느린 업데이트/삭제 | 수정 빈도가 낮은 데이터에 이상적 |
Merge-on-Read (positional deletes) | 읽기 부하 있음 | 빠른 업데이트/삭제 | 정기적인 컴팩션을 사용하여 읽기 비용 최소화 |
Merge-on-Read (equality deletes) | 느린 읽기 | 가장 빠른 업데이트/삭제 | 더 빈번한 컴팩션을 사용하여 읽기 비용 최소화 |
5.2 Copy-on-Write (COW)
기본 접근 방식은 copy-on-write(COW)라고 합니다. 이 접근 방식에서는 데이터파일의 단일 행이라도 업데이트되거나 삭제되면, 해당 데이터파일이 다시 쓰이고 새 파일이 새 스냅샷에서 그 자리를 대신합니다.

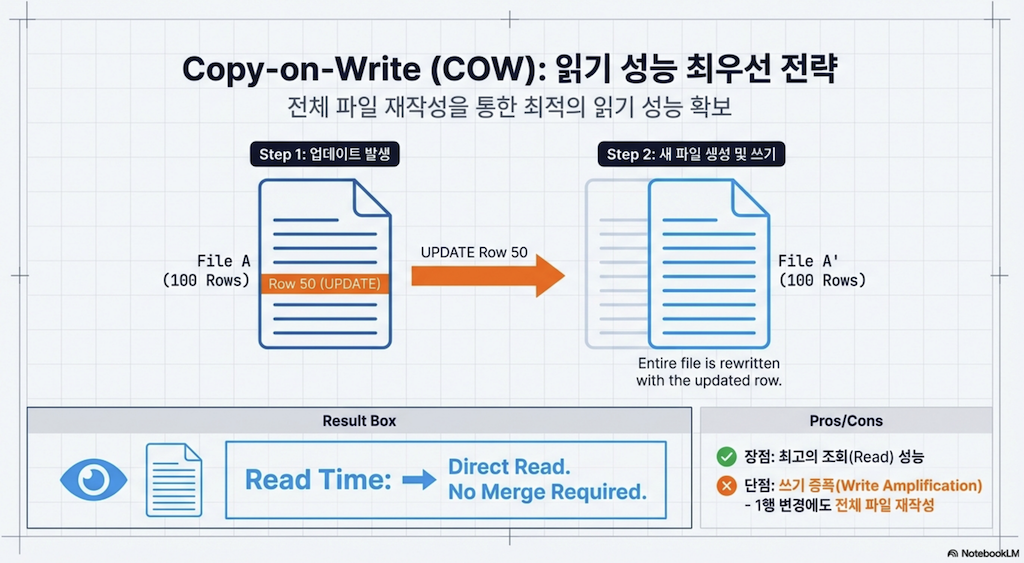
이것은 읽기 쿼리가 삭제되거나 업데이트된 파일을 조정할 필요 없이 데이터를 읽을 수 있어 읽기에 최적화하려는 경우 이상적입니다. 그러나 작업 부하가 매우 정기적인 행 수준 업데이트로 구성되면, 해당 업데이트를 위해 전체 데이터파일을 다시 쓰는 것이 SLA가 허용하는 것 이상으로 업데이트를 느리게 할 수 있습니다.
장점: 더 빠른 읽기
단점: 더 느린 행 수준 업데이트 및 삭제
5.3 Merge-on-Read (MOR)
copy-on-write의 대안은 merge-on-read(MOR)입니다. 전체 데이터파일을 다시 쓰는 대신, 삭제 파일에 기존 파일에서 업데이트할 레코드를 캡처하고, 삭제 파일이 어떤 레코드를 무시해야 하는지 추적합니다.
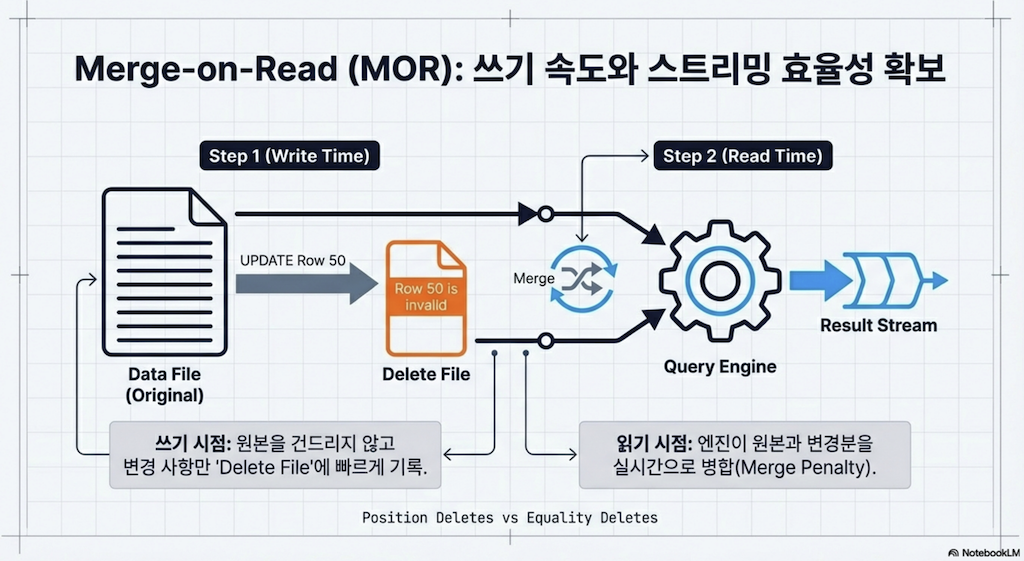
레코드 삭제 시:
레코드가 삭제 파일에 나열됩니다
리더가 테이블을 읽을 때, 데이터파일과 삭제 파일을 조정합니다
레코드 업데이트 시:
업데이트할 레코드가 삭제 파일에 추적됩니다
업데이트된 레코드만 있는 새 데이터파일이 생성됩니다
리더가 테이블을 읽을 때, 삭제 파일 때문에 레코드의 이전 버전을 무시하고 새 데이터파일의 새 버전을 사용합니다
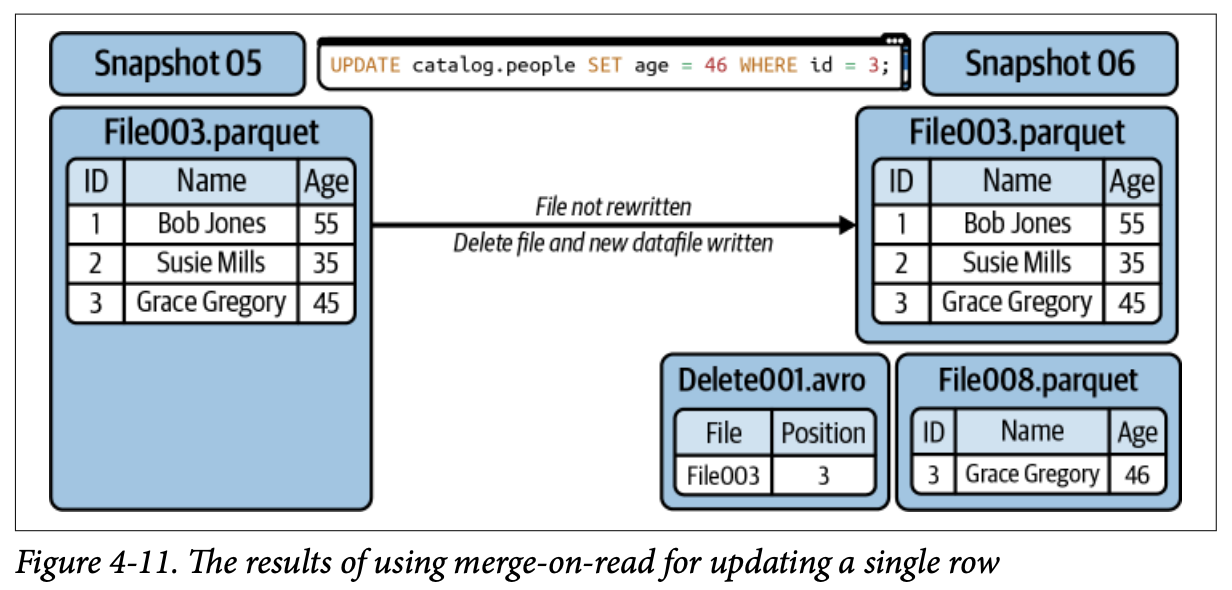
이는 업데이트할 레코드와 함께 데이터파일에 존재한다는 이유만으로 변경되지 않은 레코드를 새 파일에 다시 쓸 필요를 피하고, 쓰기 트랜잭션을 가속화합니다. 그러나 쿼리가 삭제 파일을 스캔하여 적절한 데이터파일에서 어떤 레코드를 무시해야 하는지 알아야 하므로 더 느린 읽기의 비용이 따릅니다.
읽기 비용을 최소화하기 위해:
정기적인 컴팩션 작업을 실행합니다
컴팩션 작업이 효율적으로 실행되도록 다음 속성을 활용합니다:
filter/where절을 사용하여 마지막 시간 프레임(시간, 일)에 수집된 파일에만 컴팩션을 실행부분 진행 모드를 사용하여 파일 그룹이 다시 쓰일 때마다 커밋하여 리더가 점점 개선을 더 빨리 볼 수 있도록 함
장점: 더 빠른 행 수준 업데이트
단점: 삭제 파일을 조정해야 하므로 더 느린 읽기
5.4 삭제 파일 유형
MOR 쓰기를 할 때, 삭제 파일을 통해 향후 읽기를 위해 기존 데이터파일에서 어떤 레코드를 무시해야 하는지 추적할 수 있습니다.
Positional Delete Files (위치 삭제 파일)
특정 행을 제거하고 싶을 때, 데이터셋에서 위치에 따라 행 데이터를 찾을 수 있습니다. 영화관에서 좌석 번호로 친구를 찾는 것과 같습니다.
위치 삭제는 어떤 파일의 어떤 행을 무시해야 하는지 추적합니다:
Filepath | Position |
|---|---|
001.parquet | 0 |
001.parquet | 5 |
006.parquet | 5 |
지정된 파일을 읽을 때, 위치 삭제 파일은 지정된 위치의 행을 건너뜁니다. 이는 행을 건너뛰어야 하는 상당히 구체적인 지점이 있으므로 읽기 시 훨씬 작은 비용이 필요합니다. 그러나 삭제 파일의 작성자가 삭제된 레코드의 위치를 알아야 하므로 삭제된 레코드가 있는 파일을 읽어 해당 위치를 식별해야 하는 쓰기 시 비용이 있습니다.
Equality Delete Files (동등 삭제 파일)
레코드가 일치하면 무시해야 하는 값을 대신 지정합니다. 군중에서 밝은 빨간 모자를 쓰고 있어서 친구를 고르는 것과 같습니다.
Team | State |
|---|---|
Yellow | NY |
Green | MA |
파일을 열고 읽어 대상 값을 추적할 필요가 없으므로 쓰기 시 비용이 없지만, 훨씬 더 큰 읽기 시 비용이 있습니다. 읽기 시 비용은 일치하는 값이 있는 레코드가 어디에 있는지에 대한 정보가 없어서, 데이터를 읽을 때 일치하는 레코드를 포함할 수 있는 모든 레코드와 비교해야 하기 때문입니다.
5.5 COW 및 MOR 구성
행 수준 업데이트와 삭제를 수행하려는 쓰기 유형을 기본적으로 테이블 속성에서 지정할 수 있습니다:
ALTER TABLE catalog.MyTable SET TBLPROPERTIES (
'write.delete.mode'='copy-on-write',
'write.update.mode'='merge-on-read',
'write.merge.mode'='merge-on-read',
);테이블 속성을 설정하는 대신, 쓰기 옵션에서 직접 COW 또는 MOR 속성을 지정할 수도 있습니다 (Spark의 DataFrame API 사용 시):
df.write \
.option("write-format", "parquet") \
.option("merge-mode", "merge-on-read")비 Apache Spark 엔진 작업 시 주의사항:
테이블 속성이 준수될 수도 있고 아닐 수도 있습니다. 엔진이 지원을 구현하는지에 따라 달라집니다
MOR 사용 시, 데이터를 쿼리하는 데 사용하는 엔진이 삭제 파일을 읽을 수 있는지 확인해야 합니다
6. 기타 고려사항 (Other Considerations)
6.1 메트릭 수집 (Metrics Collection)
2장에서 논의한 것처럼, 각 데이터파일 그룹에 대한 매니페스트는 min/max 필터링 및 기타 최적화를 돕기 위해 테이블의 각 필드에 대한 메트릭을 추적합니다. 추적되는 열 수준 메트릭 유형:
값, null 값, 고유 값의 개수
상한 및 하한 값
매우 넓은 테이블(필드가 많은 테이블, 예: 100개 이상)이 있다면, 추적되는 메트릭의 수가 메타데이터를 읽는 데 부담이 되기 시작할 수 있습니다.
Apache Iceberg의 테이블 속성을 사용하면 어떤 열의 메트릭을 추적하고 어떤 열은 추적하지 않을지 세밀하게 조정할 수 있습니다:
ALTER TABLE catalog.db.students SET TBLPROPERTIES (
'write.metadata.metrics.column.col1'='none',
'write.metadata.metrics.column.col2'='full',
'write.metadata.metrics.column.col3'='counts',
'write.metadata.metrics.column.col4'='truncate(16)'
);메트릭 수집 레벨:
레벨 | 설명 |
|---|---|
| 메트릭을 수집하지 않음 |
| 개수만 수집 (값, 고유 값, null 값) |
| 개수를 세고 값을 특정 문자 수로 잘라서 상한/하한을 그에 기반함 |
| 전체 값을 기반으로 개수와 상한/하한 계산 |
기본적으로 Iceberg는 이를 truncate(16)로 설정합니다.
6.2 매니페스트 재작성 (Rewriting Manifests)
때때로 문제는 데이터파일이 아닐 수 있습니다. 데이터파일은 잘 정렬된 데이터로 적절한 크기를 가지고 있지만, 여러 스냅샷에 걸쳐 작성되어 개별 매니페스트가 더 많은 데이터파일을 나열할 수 있습니다. 매니페스트가 더 가볍지만, 더 많은 매니페스트는 여전히 더 많은 파일 작업을 의미합니다.
Apache Iceberg에는 매니페스트를 재작성하는 프로시저가 있습니다:
CALL catalog.system.rewrite_manifests('MyTable')이 프로시저는 기본적으로 매니페스트당 데이터파일 평균에 기반하여 매니페스트를 재작성합니다.
전달할 수 있는 인수:
인수 | 설명 |
|---|---|
| 작업을 실행할 테이블 |
| true이면 데이터파일을 읽을 때 Spark 캐시 사용 |
6.3 스토리지 최적화 (Optimizing Storage)
스냅샷 만료 (Expire Snapshots)
테이블에서 스냅샷을 절대 만료시키지 않으면 증가하는 메타데이터 양이 시간이 지남에 따라 부담이 될 수 있습니다. 모든 스냅샷을 유지하면 다음과 같은 추가 비용이 있습니다:
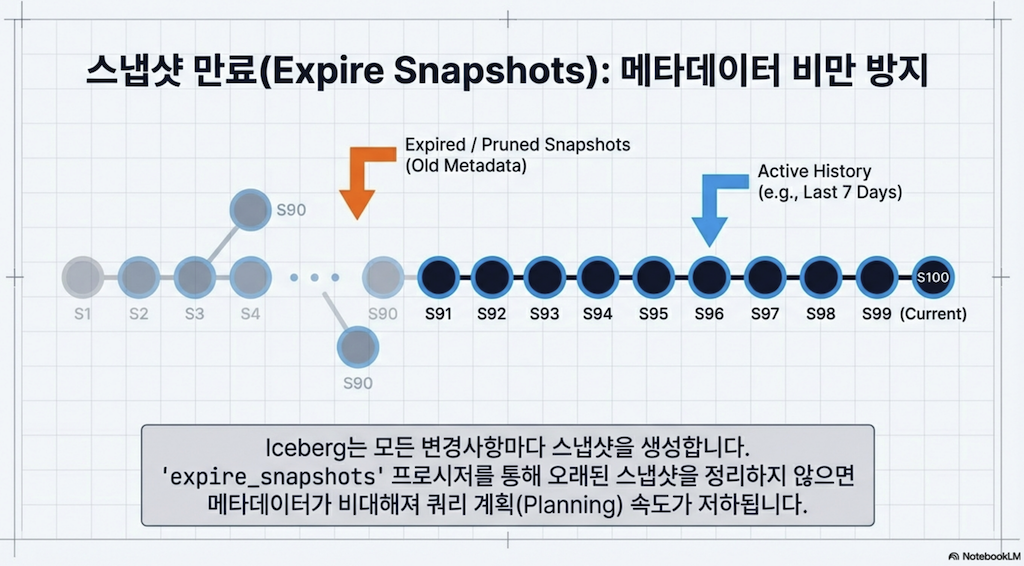
테이블을 구성하는 파일을 호스팅하는 스토리지 비용
쿼리 전에 테이블의 메타데이터 구조를 파싱하는 데 드는 계산 비용
CALL catalog.system.expire_snapshots(table => 'MyTable', older_than => TIMESTAMP '2023-06-01 00:00:00')특정 스냅샷 ID를 만료시킬 수도 있습니다:
CALL catalog.system.expire_snapshots(table => 'MyTable', snapshot_ids => ARRAY(53))expire_snapshots 프로시저에 전달할 수 있는 인수:
인수 | 설명 |
|---|---|
| 작업을 실행할 테이블 |
| 이 타임스탬프 이전의 모든 스냅샷 만료 |
| 유지할 최소 스냅샷 수 |
| 만료할 특정 스냅샷 ID |
| 파일 삭제에 사용할 스레드 수 |
| true이면 삭제된 파일을 RDD 파티션별로 Spark 드라이버로 전송 |
고아 파일 관리 (Orphan File Management)
스토리지를 최적화할 때 또 다른 고려사항은 고아 파일입니다. 이는 테이블의 데이터 디렉토리에 축적되지만 실패한 작업에 의해 작성되어 메타데이터 트리에서 추적되지 않는 파일과 아티팩트입니다. 이러한 파일은 스냅샷 만료로 정리되지 않으므로 이를 처리하기 위해 특별한 프로시저를 간헐적으로 실행해야 합니다.
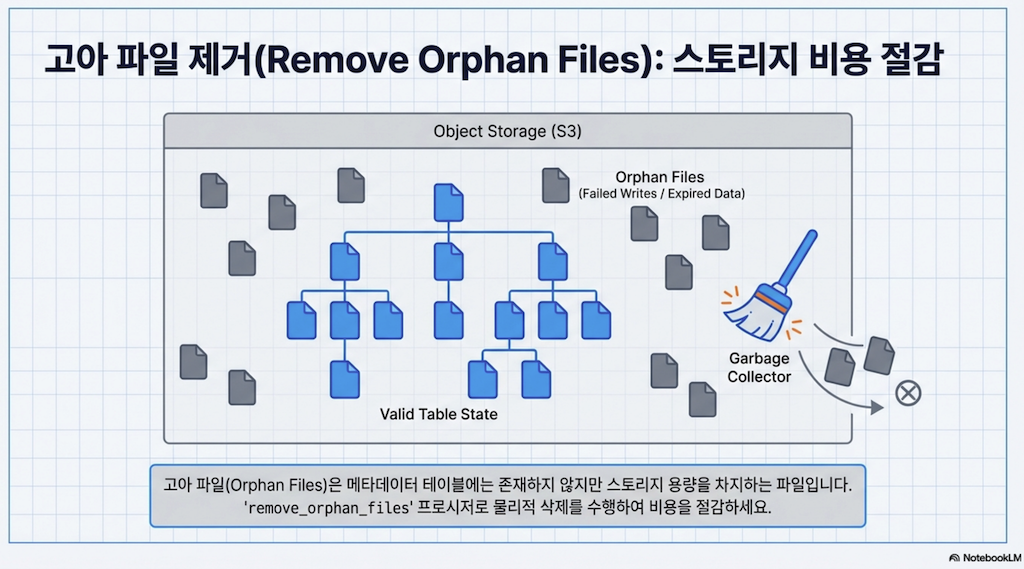
CALL catalog.system.remove_orphan_files(table => 'MyTable')removeOrphanFiles 프로시저에 전달할 수 있는 인수:
인수 | 설명 |
|---|---|
| 작업할 테이블 |
| 이 타임스탬프 이전에 생성된 파일만 삭제 |
| 고아 파일을 찾을 위치; 기본값은 테이블의 기본 위치 |
| true이면 파일을 삭제하지 않고 삭제될 파일 목록만 반환 |
| 파일 삭제를 위한 최대 스레드 수 |
6.4 쓰기 분배 모드 (Write Distribution Mode)
쓰기 분배 모드는 대규모 병렬 처리(MPP) 시스템이 파일 쓰기를 처리하는 방식을 이해해야 합니다. 이러한 시스템은 작업을 여러 노드에 분배하며, 각각 작업이나 태스크를 수행합니다. 쓰기 분배는 쓰려는 레코드가 이러한 태스크에 어떻게 분배되는지입니다.
특정 쓰기 분배 모드가 설정되지 않으면, 데이터는 임의로 분배됩니다. 첫 X개의 레코드는 첫 번째 태스크로, 다음 X개는 다음 태스크로, 등등.
세 가지 옵션:
모드 | 설명 |
|---|---|
| 특별한 분배 없음. 쓰기 시 가장 빠르며 미리 정렬된 데이터에 이상적 |
| 파티션 키로 해시 분배됨 |
| 파티션 키 또는 정렬 순서로 범위 분배됨 |
ALTER TABLE catalog.MyTable SET TBLPROPERTIES (
'write.distribution-mode'='hash',
'write.delete.distribution-mode'='none',
'write.update.distribution-mode'='range',
'write.merge.distribution-mode'='hash'
);해시 분배: 각 레코드의 값이 해시 함수를 통과하고 결과에 따라 함께 그룹화됩니다.
범위 분배: 데이터가 정렬되고 분배됩니다. 파티션 값 또는 테이블에 SortOrder가 있는 경우 SortOrder에 의해 정렬됩니다. 이는 특정 필드에서 클러스터링의 이점을 받을 수 있는 데이터에 이상적입니다.
6.5 오브젝트 스토리지 고려사항 (Object Storage Considerations)
오브젝트 스토리지는 데이터를 저장하는 독특한 방식입니다. 전통적인 파일시스템처럼 깔끔한 폴더 구조에 파일을 유지하는 대신, 오브젝트 스토리지는 모든 것을 버킷이라고 불리는 곳에 넣습니다.
오브젝트 스토리지의 아키텍처와 병렬 처리 방식 때문에, 종종 같은 "prefix" 아래의 파일로 갈 수 있는 요청 수에 제한이 있습니다. /prefix1/fileA.txt와 /prefix1/fileB.txt에 접근하려 할 때, 서로 다른 파일이지만 둘 다 접근하는 것은 prefix1에 대한 제한에 포함됩니다. 이는 많은 파일이 있는 파티션에서 문제가 되며, 쿼리가 이러한 파티션에 많은 요청을 보내 스로틀링이 발생하여 쿼리가 느려질 수 있습니다.
Apache Iceberg는 파일이 물리적으로 배치되는 방식에 의존하지 않으므로 이 시나리오에 독특하게 적합합니다. 같은 파티션의 파일을 여러 prefix에 걸쳐 쓸 수 있습니다.
ALTER TABLE catalog.MyTable SET TBLPROPERTIES (
'write.object-storage.enabled'= true
);이전:
s3://bucket/database/table/field=value1/datafile1.parquet
s3://bucket/database/table/field=value1/datafile2.parquet
s3://bucket/database/table/field=value1/datafile3.parquet이후:
s3://bucket/4809098/database/table/field=value1/datafile1.parquet
s3://bucket/5840329/database/table/field=value1/datafile2.parquet
s3://bucket/2342344/database/table/field=value1/datafile3.parquet해시가 파일 경로에 있어서, 같은 파티션의 각 파일이 이제 다른 prefix 아래에 있는 것처럼 취급되어 스로틀링을 피할 수 있습니다.
6.6 데이터파일 블룸 필터 (Datafile Bloom Filters)
블룸 필터는 값이 데이터셋에 존재할 가능성이 있는지 알 수 있는 방법입니다. 결정한 길이의 비트(이진 코드의 0과 1) 줄을 상상해 보세요. 데이터를 데이터셋에 추가할 때, 각 값을 해시 함수라는 프로세스를 통해 실행합니다. 이 함수는 비트 줄의 한 지점을 내놓고, 그 비트를 0에서 1로 뒤집습니다. 이 뒤집힌 비트는 "이 지점에 해시되는 값이 데이터셋에 있을 수 있다"고 말하는 플래그와 같습니다.
예시: 10비트의 블룸 필터를 통해 1,000개의 레코드를 공급하면:
[0,1,1,0,0,1,1,1,1,0]값 X를 찾고 싶다고 합니다. X를 같은 해시 함수를 통해 넣으면 비트 줄의 3번째 지점을 가리킵니다. 블룸 필터에 따르면 3번째 지점에 1이 있습니다. 이는 값 X가 데이터셋에 있을 가능성이 있음을 의미합니다. 그래서 X가 정말 있는지 데이터셋을 확인합니다.
값 Y를 찾는다고 합니다. Y를 해시 함수를 통해 실행하면 4번째 지점을 가리킵니다. 하지만 블룸 필터에 그 지점에 0이 있어서, 이 지점에 해시된 값이 없다는 의미입니다. 따라서 Y가 데이터셋에 확실히 없다고 자신있게 말할 수 있고, 데이터를 뒤지지 않아 시간을 절약할 수 있습니다.
ALTER TABLE catalog.MyTable SET TBLPROPERTIES (
'write.parquet.bloom-filter-enabled.column.col1'= true,
'write.parquet.bloom-filter-max-bytes'= 1048576
);블룸 필터가 명확히 필요한 데이터가 존재하지 않음을 나타내는 데이터파일을 건너뛰어 데이터파일 읽기를 더욱 빠르게 할 수 있습니다.