

1. DAG Factory 설계 방향 📙
DAG Factory라고 했지만, DAG class는 앞에서 설명한 Simple Factory 방법을 사용하였다.
정석이라고 할 수 있는 Factory method 패턴처럼 추상화된 인터페이스를 구현하지 않았다. 그 이유는 추상화된 인터페이스를 구현하는 서브 클래스가 단 1개만 나올 것이라 예상했기 때문이다. 추상화된 인터페이스 개념은 1:N 관계로 서브 클래스를 구현하고 객체 호출시에는 추상화된 인터페이스만 참조할 때 효과적이라 생각했다. 그래서 1:1 관계에서는 인터페이스 개념을 만드는 것이 비효율적일 것이라는 판단을 내렸다.
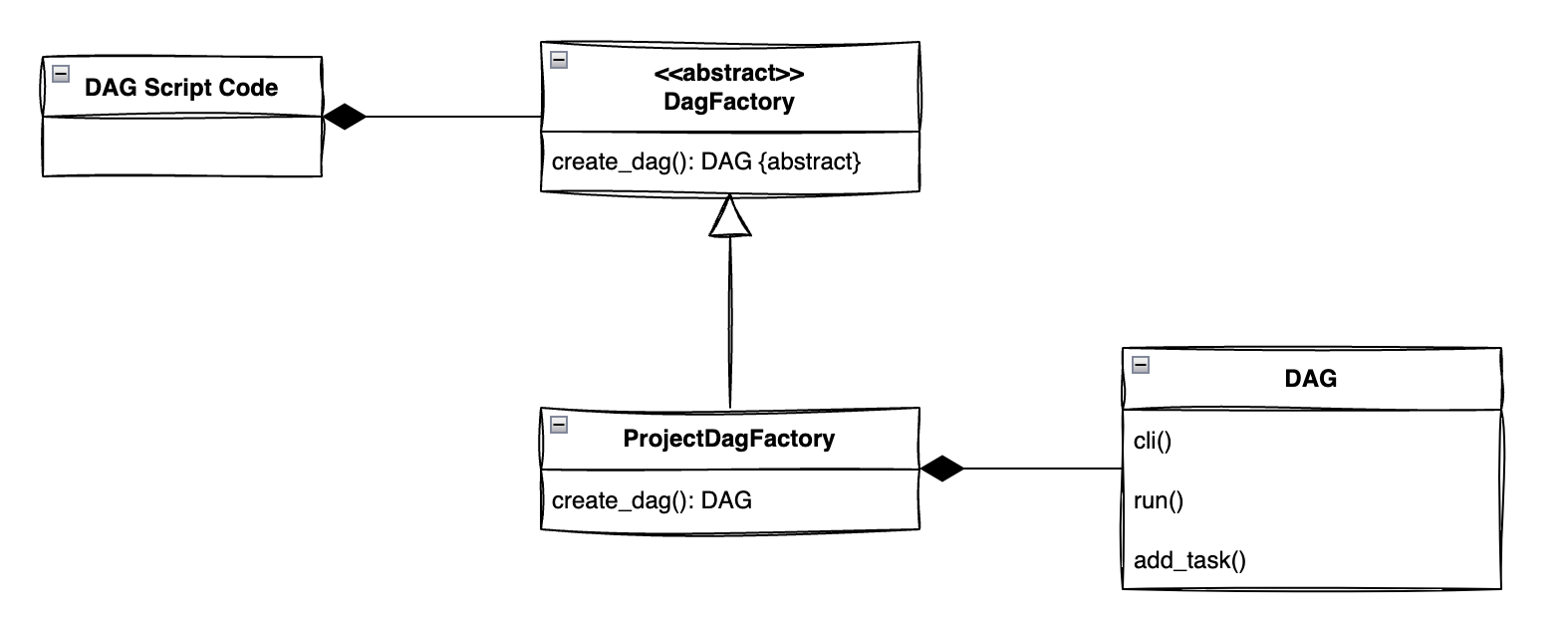
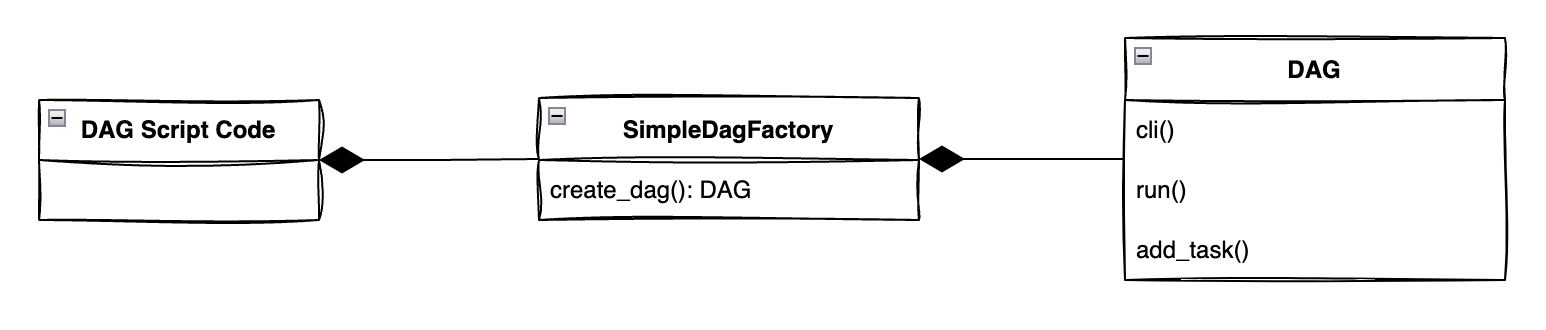
DAG class는 Task(operator, sensor) class들과는 다르게 1개만 존재하므로 중간에 인터페이스 개념을 추가해서 복잡도를 높일 이유가 없다. 인터페이스 개념의 장점은 클라이언트가 복잡한 내부 구현을 알 필요가 없어서 쉽게 변경할 수 있다는 점인데, 지금 상황에서는 인터페이스 개념을 사용하지 않아도 큰 문제가 없어보인다.
2. DAG Factory UML 다이어그램 🖌️
아래 다이어그램처럼 구조를 잡고 코드를 짜려고 한다.
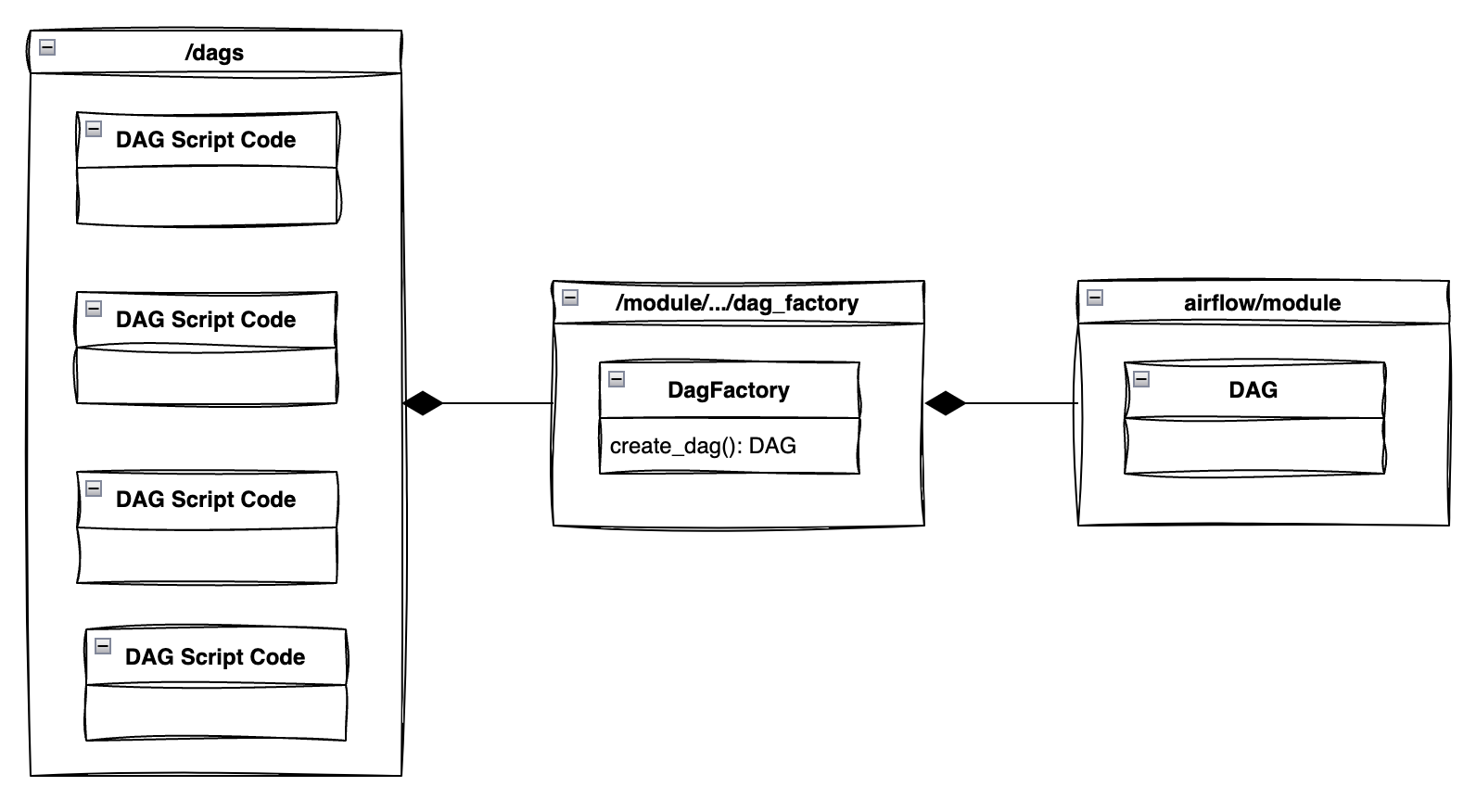
3. Code 🧑💻
위 UML 다이어그램에 맞춰 DAGFactory 코드의 구조를 짜보자.
A. 전체 구조 잡기 👷
Factory 패턴이니까 DAG 객체를 만드는 메소드를 하나 만든다.
class SushiDAGFactory:
def __init__(
self,
...
):
...
def build_dag(self) -> DAG:
...
B. build_dag 메서드 구현 🏗️
Factory method를 구현해보자.
Factory method로 생성되는 DAG 객체는 기존에 DAG script에서 사용하던 DAG 객체를 대체할 수 있어야 한다. 그러니 기존에 DAG 객체를 생성할 때 한 번이라도 사용된 parameter는 전부 작성해주자.
보통 Factory method로 구현하면 build_dag()의 파라미터로 생성될 객체의 구분자를 넣어준다. 그렇지만 내가 지금 만들 DAG Factory에서 DAG가 구분자가 필요할 만큼 종류가 많지 않고, Simple Factory라는 야매 방식으로 구현할 것이다. 그래서 build_dag()에서는 구분자로 사용될 parameter를 받지 않고 생성자 쪽에서 받으려고 한다. (~~이렇게 되니까 그냥 wrapping하는 것과 다를게 없..)
def build_dag(self) -> DAG:
return DAG(
dag_id=self._dag_id,
description=self._description,
schedule=self._schedule,
start_date=self._start_date,
end_date=self._end_date,
catchup=self._catchup,
default_args=self._task_args,
max_active_tasks=self._max_active_tasks,
max_active_runs=self._max_active_runs,
dagrun_timeout=self._dagrun_timeout,
on_success_callback=self._on_success_callback,
on_failure_callback=self._on_failure_callback,
doc_md=self._doc_md,
render_template_as_native_obj=self._render_template_as_native_obj,
tags=self._tags,
owner_links=self._owner_links,
)
C. DAGFactory 생성자 구현 🏭
build_dag()에서 한 번이라도 사용한 parameter를 전부 넣어서 DAG 객체를 만들도록 코드를 작성했다. 그런데 DAG 객체를 생성하는데 사용한 parameter를 한꺼번에 다루기에는 양이 방대하기 때문에 조금씩 나눠서 진행해보려고 한다.
a. ScheduleConfiguration Value Object (VO)
일단 DAG를 생성하는데, 정말 필요한 argument부터 골라보자.
class SushiDAGFactory:
def __init__(
self,
dag_id: str,
schedule: str,
start_date: datetime,
end_date: datetime,
catchup: bool=False,
):
...
정말 필요한 argument만 골랐는데 6개다. 아마 pylint의 too-many-arguments 에러가 발생할 것이다. pylint disable을 사용하기는 싫으니 argument를 압축할 방법을 찾아보자.
schedule, start_date, end_date, catchup 모두 스케줄과 관련된 argument이다. 이 argument들을 하나의 스케줄 VO로 묶을 수 있을 것 같다.
VO는 값만 가지고 있는 값 객체로 특정 값을 나타내는 개념이다. 값 객체이기 때문에 별도로 수정이 불가능해야한다는 특징이 있다. (현재 __post_init__의 동작 방식을 파악하지 못해서 @dataclass(frozen=False)로 수정 불가능한 옵션을 주지 못했다.)
@dataclass
class ScheduleConfiguration:
"""
schedule conf VO class
"""
tz: Timezone = pendulum.timezone("Asia/Seoul")
schedule: str = None
start_date: datetime = datetime(2022, 12, 31)
end_date: datetime = None
catchup: bool = False
def __post_init__(self):
self.start_date = pendulum.instance(self.start_date, tz=self.tz)
if self.end_date:
self.end_date = pendulum.instance(self.end_date, tz=self.tz)
ScheduleConfiguration VO를 적용한 DAGFactory의 생성자를 확인해보자. 이 정도면 pylint에서 에러가 발생하지는 않을 것 같다.
class SushiDAGFactory:
def __init__(
self,
dag_id: str,
schedule_conf: ScheduleConfiguration = ScheduleConfiguration(),
):
self._schedule = schedule_conf.schedule
self._start_date = schedule_conf.start_date
self._end_date = schedule_conf.end_date
self._catchup = schedule_conf.catchup
...
b. default_args, tags
별로 특별한 것은 아니기 때문에 코드만 남기고 넘어간다.
class SushiDAGFactory:
def __init__(
self,
schedule_conf: ScheduleConfiguration = ScheduleConfiguration(),
task_args: dict = None,
tags: list = None,
):
self._schedule = schedule_conf.schedule
self._start_date = schedule_conf.start_date
self._end_date = schedule_conf.end_date
self._catchup = schedule_conf.catchup
self._task_args = self._build_defualt_args_for_task(task_args)
self._tags = tags
...
@staticmethod
def _build_defualt_args_for_task(task_args) -> dict:
args = {
"retries": 0,
"retry_delay": timedelta(minutes=1),
}
if task_args:
args.update(task_args)
return args
c. dag_id argument는 호출한 파일명을 사용하도록 수정
나는 이전 포스팅에서 작성한 것처럼 dag_id를 각각 직접 입력해주지 않는다. 보통 사용하는 방식처럼 os.path.basename(__file__).replace(".py", "")를 통해 파일명을 자동으로 파싱해서 dag_id로 사용한다. 이렇게 되면 dag_id와 script 파일명이 동일하기 때문에 dag 관리가 편해지는 장점이 있다.
그런데 DAGFactory에서는 저 방식을 사용할 수 없다. DAGFactory에서 __file__을 호출하면 User/mildsalmon/airflow-lab/module/airflow/pattern/factory/dag_factory.py가 나오기 때문이다. 내가 기대한 것은User/mildsalmon/airflow-lab/dags/test_dag.py이지 dag_factory 파일명은 아니다.
os 라이브러리를 사용하지 않고 inspect 라이브러리를 사용해서 caller의 정보를 가지고 와서 이 문제를 해결할 수 있다. 추가로 script 파일의doc_md도 가져오자.
class SushiDAGFactory:
def __init__(
self,
schedule_conf: ScheduleConfiguration = ScheduleConfiguration(),
task_args: dict = None,
tags: list = None,
):
...
self._task_args = self._build_defualt_args_for_task(task_args)
self._tags = tags
caller_info = inspect.stack()[1]
dag_file_name = caller_info.filename
self._dag_id = os.path.basename(dag_file_name).replace(".py", "")
self._doc_md = caller_info.frame.f_globals.get("__doc__")
d. 1차 마무리
이 정도면, 처음 계획한 내용은 다 구현한 것 같다. 최종 마무리를 하기 전에 코드를 정리해보자.
class SushiDAGFactory:
def __init__(
self,
schedule_conf: ScheduleConfiguration = ScheduleConfiguration(),
task_args: dict = None,
tags: list = None,
):
self._schedule = schedule_conf.schedule
self._start_date = schedule_conf.start_date
self._end_date = schedule_conf.end_date
self._catchup = schedule_conf.catchup
self._task_args = self._build_defualt_args_for_task(task_args)
self._tags = tags
caller_info = inspect.stack()[1]
dag_file_name = caller_info.filename
self._dag_id = os.path.basename(dag_file_name).replace(".py", "")
self._doc_md = caller_info.frame.f_globals.get("__doc__")
self._max_active_runs = 3
self._max_active_tasks = 3
self._description = None
self._dagrun_timeout = None
self._render_template_as_native_obj = True
self._owner_links = None
self._on_success_callback = None
self._on_failure_callback = [failure_callback_slack_handler]
self._sla_miss_callback = None
@staticmethod
def _build_defualt_args_for_task(task_args) -> dict:
args = {
"retries": 0,
"retry_delay": timedelta(minutes=1),
}
if task_args:
args.update(task_args)
return args
def build_dag(self) -> DAG:
return DAG(
dag_id=self._dag_id,
description=self._description,
schedule=self._schedule,
start_date=self._start_date,
end_date=self._end_date,
catchup=self._catchup,
default_args=self._task_args,
max_active_tasks=self._max_active_tasks,
max_active_runs=self._max_active_runs,
dagrun_timeout=self._dagrun_timeout,
on_success_callback=self._on_success_callback,
on_failure_callback=self._on_failure_callback,
doc_md=self._doc_md,
render_template_as_native_obj=self._render_template_as_native_obj,
tags=self._tags,
owner_links=self._owner_links,
)
Factory 구조는 잘 짠 것 같은데, 뭔가 더 개선할 수 있을 것 같다. 🤔
D. Builder 패턴 추가 🛠️
모든 DAG script에서 전부 아래와 동일한 parameter를 사용할까? 🙅♂️ 아마 DAG 객체마다 조금씩 다를 것이다. 그러면 아래 값들을 전부 생성자의 argument에 넣어줘서 인자로 받을 수 있게 하는 것이 최선일까? 🤷♂️ 파이썬의 특성 상 그래도 상관없지만, Airflow DAG class를 처음 봤을 때 화면을 가득 채운 argument를 생각해보자... (처음 airflow 코드를 파먹는다며 DAG class를 열었지만, 여러번 포기했다..)
self._max_active_runs = 3
self._max_active_tasks = 3
self._description = None
self._dagrun_timeout = None
self._render_template_as_native_obj = True
self._owner_links = None
self._on_success_callback = None
self._on_failure_callback = [failure_callback_slack_handler]
self._sla_miss_callback = None
대부분의 경우 DAGFactory로 DAG 객체를 생성할 때 아래 값들을 변경해줄 일이 거의 없다. 그럼에도 불구하고 아주 가끔은 아래 값들을 수정해줘야할 때가 있다. 이런 극히 드문 경우를 위해 수정하지 않는 값을 생성자에 물고 있는 것이 좋은 상황일까? 좋지 않다는 것은 pylint가 too-many-argument 에러를 밷으면서 알려준다.
builder 패턴을 조금 활용하면 이 문제를 쉽게 해결할 수 있다. builder 패턴에 대해 찾아보니, product class, builder class, director class를 만들어서 구현한다고 되어 있었다. 그러나 지금 사용하려는 builder 패턴도 어떻게 보면 야매에 가까울 수 있을 것 같다. 단순히 client에서 원한다면 값을 수정하고 체이닝을 통해 쌓는 방식으로 구현했기 때문이다.
a. Builder 패턴 구현
client가 DAG 생성하기 위해 반드시 필요한 argument만 생성자로 받는다. client가 굳이 건들 필요는 없지만, 건들여도 되는 값들은 builder 패턴으로 열어주었다.
대부분 아래 코드와 같은 방식으로 구현하였다.
def description(self, desc: str) -> object:
self._description = desc
return self
E. 총 정리 😇
DAGFactory를 마무리하기 전에 UML 다이어그램을 아래와 같이 구체적으로 그릴 수 있다.
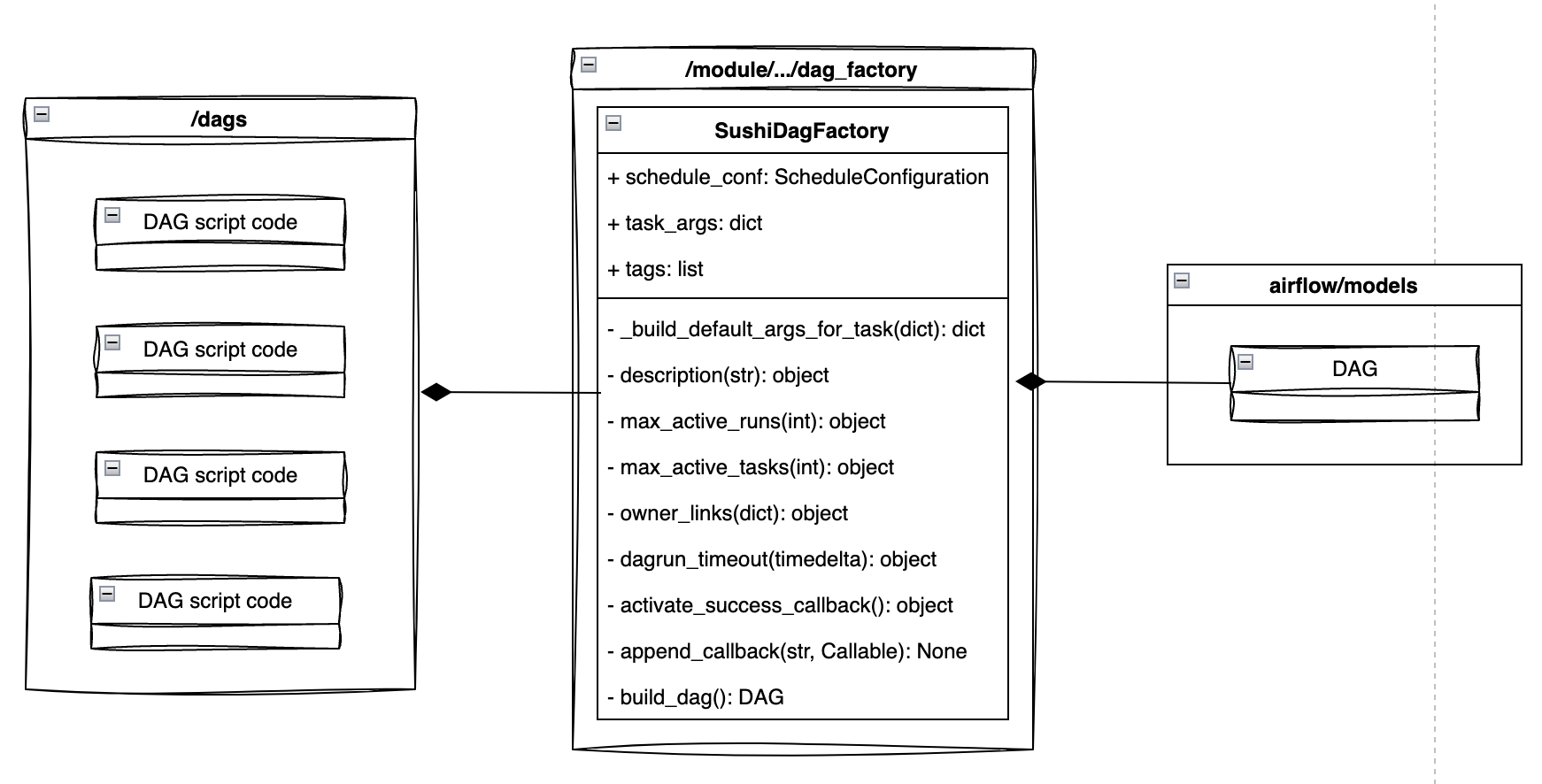
이 포스팅을 위해 사용된 소스 코드는 아래 깃헙에 올려두었다.
https://github.com/taco-DE/airflow-lab/blob/main/module/airflow/pattern/factory/dag_factory.py
F. 소감 🥰
디자인 패턴을 신경쓰면서 코드를 작성한 것은 이번이 처음에 가깝다. 생각보다 신경써야할 것들이 많았고, 블로그 글을 쓰기 위해서 디자인 패턴을 더 많이 공부할 수 있어서 좋은 기회였다. 테크리더님이 이런 설계가 너무 재밌다고 하셨는데, 그게 왜 그러셨는지 완전 공감된다. 설계하는 과정은 힘들고 머리아프지만, 결과를 보면 뿌듯하다. (그리고 언젠가 뒤엎을 날을 생각하면 아찔하다.)
학교에서만 배운 디자인 패턴을 직접 실무에 적용하며 코드를 작성했다는 것도 새롭게 다가온 부분이다. 그리고 학교에서 배울때는 디자인 패턴을 하나만 적용하여 배우는데 (기초 단계에서 여러개를 섞어서 배우는 것이 무리이겠지..) 실무에서는 적당한 타협을 통해 여러개가 동시에 섞일 수도 있다는 것도 신선한 충격이였다.
엔지니어는 답을 찾는 사람이 아니다. 트레이드 오프 안에서 최선의 결정을 하는 사람이다.
스트리미 데이터팀 테크리더 (쬬님)