

졸업작품을 진행하며 남긴 기록들을 블로그로 옮긴 글입니다. 따라서 블로그에는 졸업작품을 완성하기 위해 적용한 글들만 옮기려고 합니다.
전체적인 내용을 확인하시려면 아래 링크로 이동해주세요 !
1. 개요
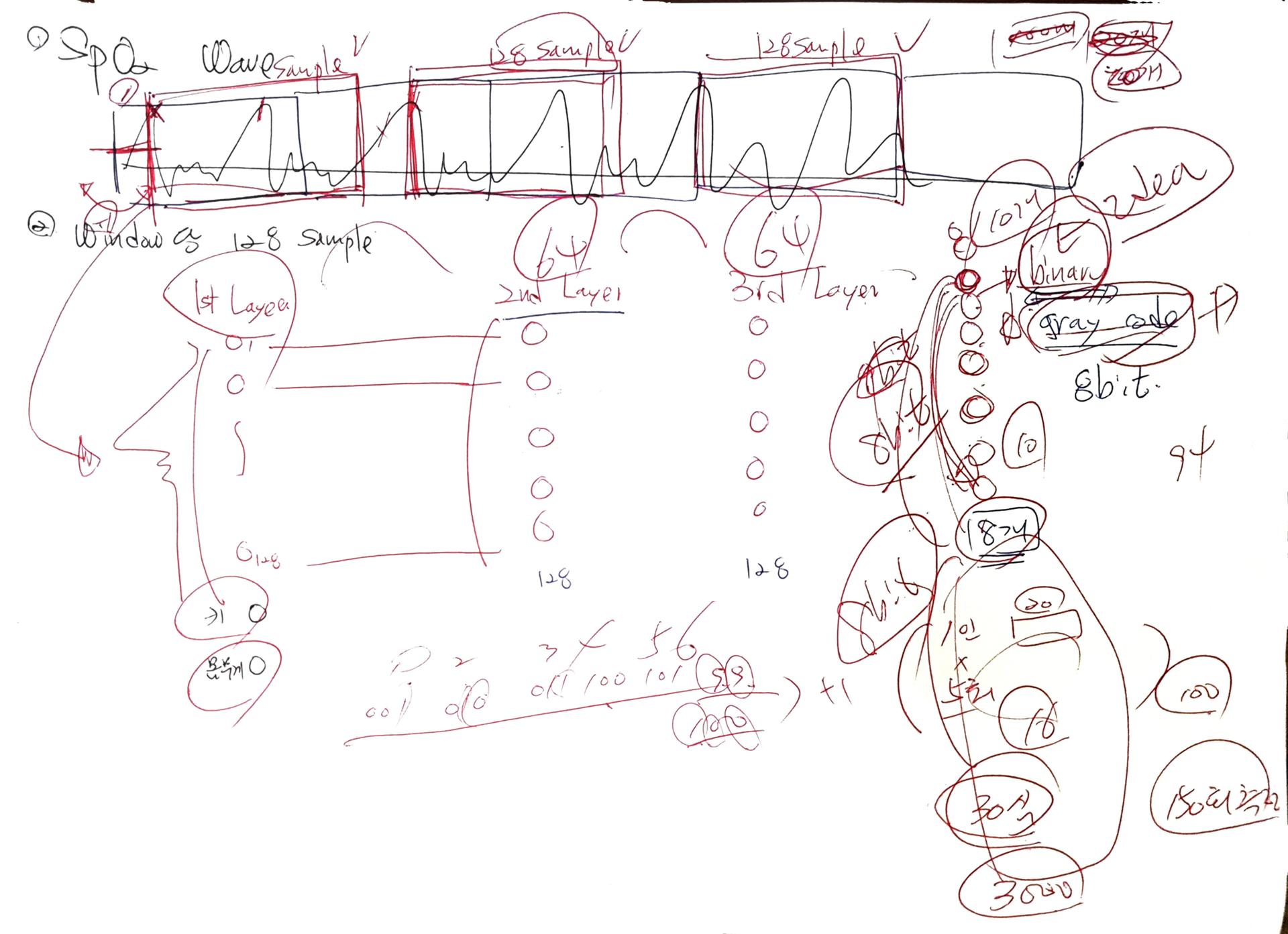
A. 전처리
- 교수님이 딥러닝을 사용하여 학습을 진행하면 굳이 파형을 1Wave로 나눠줄 필요가 없을 것이라고 하셔셨다.
- 대신 시작 지점을 파형의 최고점으로 정하고 진행하라 하셨다.
- 1Wave(Window)당 128개의 Data가 Sampling된다.
B. 딥러닝
a. Input Data
- 128개의 Sampling된 Data + 키 + 몸무게
- 키, 몸무게도 gray code
b. Output Data
- Gray Code
- 이완기 혈압, 수축기 혈압
2. 전처리
A. 해야할 것 분류
- Sampling할 Data의 시작지점을 자동으로 정해주는 알고리즘 구현
- 128개의 Data를 Sampling하는 데이터 선정하는 알고리즘
- 이전 Data와 다음 Data 사이에서 Data의 낭비가 최대한 없게 선정하는 알고리즘 구현
B. 진행 과정
a. Sampling Data의 시작지점 지정
- 하드코딩했다.
- 자동화 알고리즘을 구현하려고 했으나, 여러가지 변수때문에 시작지점을 직접 지정해주었다.
- 여러가지 변수들은 처음 일정 구간은 정상적인 파형으로 나타나다가 갑자기 파형이 뒤틀리는 경우가 있다.
b. 128개의 Data를 Sampling
- 지정한 시작지점부터 128개의 데이터만 추출하였다.
c. 다음 Data를 지정하는 알고리즘
1Sampling의 마지막 Data인 1번 동그라미를 기준으로 다음 Wave의 최고점을 찾아야한다.


### 문제
- 3번 동그라미같은 경우는 4번 동그라미를 찾기 쉬운 반면, 1번 동그라미처럼 끝나면 2번 동그라미를 찾기 힘들다.
### 해결
- 1Wave의 길이를 찾아내서 1Sampling의 마지막 Data부터 1Wave의 길이만큼 범위를 잡고 최고점을 탐색한다.
- 1Wave의 길이는 Wave마다 다르고 사람마다 다르기 때문에 알고리즘을 만들 필요성이 있다.
- 680개의 Sample이 만들어졌다.

4. 코드
5. 앞으로 생각하는 방향
-
정규화 없이 학습하기 -
gray code 사용하지 않고 학습하기 - Y값을 이완기 혈압, 수축기 혈압이 아닌 맥압으로 변경도 고려하기.