

![[한라대학교 공지 알림 봇] 유지보수](/resources/media/images/title/2020/3/2/mildsalmon/12xqYx.jpg)
Intro
내가 다시 이 시리즈를 작성할 일은 없을 줄 알았는데...
사건 설명
사건 개요
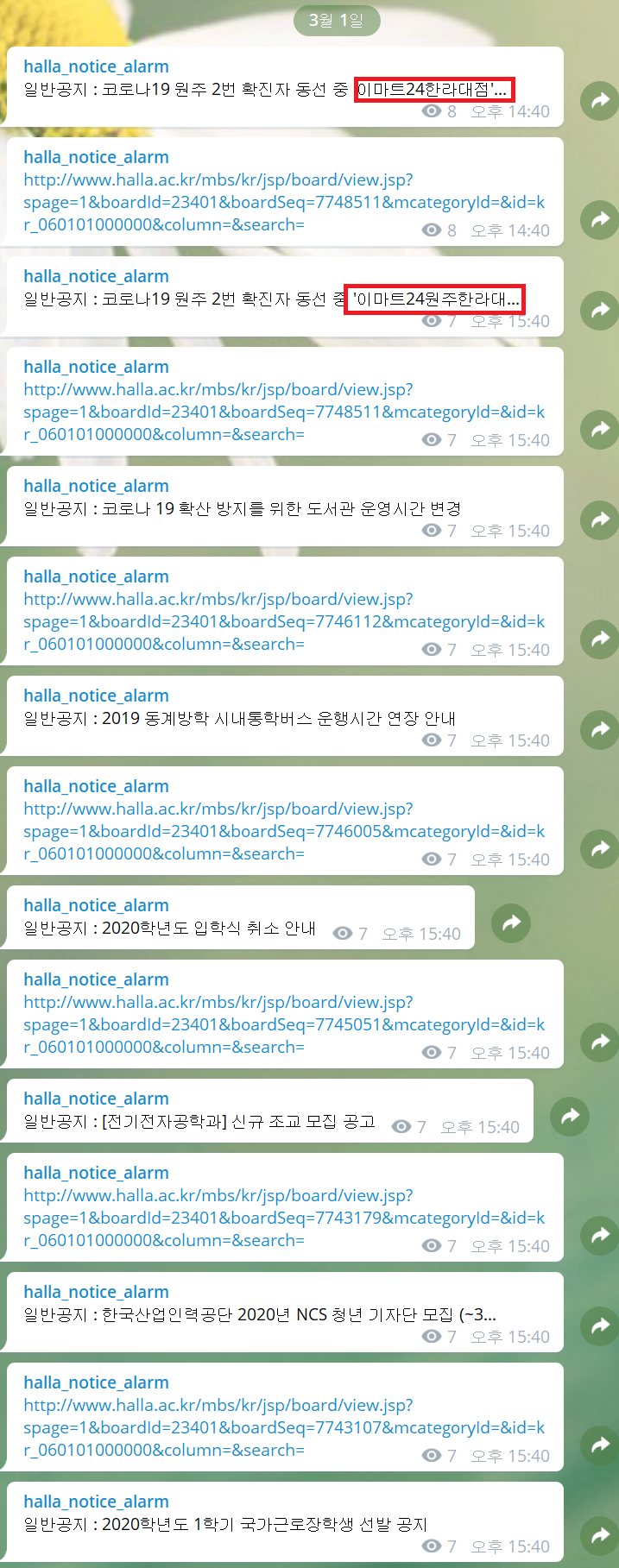
학교에서 일반공지 게시글의 제목을 바꿨다.
수정 과정
...
new_file.write(posts[0].text)
...
elif before != post.text:
...
지금까지 사용한 코드는 post.text (게시글의 제목)으로 최신 게시글인지 판단했다.
게시한 공지의 제목을 바꾼다는 생각을 하지 못해서이다.
충분히 가능했으나, 에측하지 못해서 에러가 발생했다.
그래서 학교 측에서 변경하기 힘든, 변경할리 없는 값을 찾기로 했다.
[ <a href="view.jsp?spage=1&boardId=23401&boardSeq=7748511&mcategoryId=&id=kr_060101000000&column=&search=">코로나19 원주 2번 확진자 동선 중 '이마트24원주한라대...</a>,
<a href="view.jsp?spage=1&boardId=23401&boardSeq=7746112&mcategoryId=&id=kr_060101000000&column=&search=">코로나 19 확산 방지를 위한 도서관 운영시간 변경</a>,
<a href="view.jsp?spage=1&boardId=23401&boardSeq=7746005&mcategoryId=&id=kr_060101000000&column=&search=">2019 동계방학 시내통학버스 운행시간 연장 안내</a>,
...]
메모장을 열고 내가 크롤링해오는 데이터를 붙여넣고 비교, 분석을 시작했다.
가능하면 내가 크롤링 한 데이터 중에서 값을 찾아야한다.
내가 크롤링해서 가지고 있는 데이터 밖에서 찾으면 크롤링할 부분이 더 늘어나기 때문이다.
이것은 용량, 속도에 영향을 끼친다. 물론 아주 미미하겠지만.
데이터를 보면 boardSeq= 이 부분만 다르다.
boardnum인거같다.
boardId는 학사 공지인지 일반 공지인지 확인해주는 게시판 ID이다.
그러면 저 데이터에서 boardnum을 분리해야한다.
posts는 리스트 형식의 <class 'bs4.element.Tag'>이고 posts[0]은 <class 'bs4element.Tag'>이다.
posts[0]이 str이 아니다.
그래서 str로 강제형변환을 해준다.
split_posts = str(posts[0]).split("&") # 가장 최신 공지랑 같은지 검사
str로 강제형변환을 하면, split으로 문자열을 쪼갤 수 있다.
쪼개는 지점은 boardSeq=7748511 앞 뒤를 분리하는게 가장 좋다.
boardSeq=~ 앞 뒤에는 &가 있다.
이걸 기점으로 분리하자.
['<a href="view.jsp?spage=1',
'boardId=23401',
'boardSeq=7748511',
'mcategoryId=',
'id=kr_060101000000',
'column=',
'search=">코로나19 원주 2번 확진자 동선 중 \'이마트24원주한라대...</a>']
우리가 사용할 데이터는 세번째인 2번 인덱스다.
그리고 메시지가 한꺼번에 20개가 날라오니 많이 당황스러웠다.
더군다나 내가 알바를 하고 있을 때 저렇게 날라와서 더 당황했다.
그래서 최신 게시글을 메시지로 보내는 수를 좀 더 제한하는 것도 나쁘지 않다고 생각한다.
최대 url 10개를 보낼 수 있지만,
서버가 항상 켜져있어서 3개 혹은 5개까지면 충분히 1시간 안에 발생하는 게시글을 전부 크롤링 할 수 있다고 생각한다.
공지 게시판이 자유게시판처럼 매 분마다 게시글이 쏟아져나오는 곳이 아니기 때문이다.
그래서 일단은 최대 최신 게시글을 메시지로 보내는 수를 10개에서 5개로 제한했다.
유지보수 결과
import requests
from bs4 import BeautifulSoup
import sys
import telegram
import os
import time
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
my_token = '봇 토큰'
my_chat_id = '채널 주소 / 서비스 채널은 @*** / 테스트 체널은 -***'
req = requests.get('http://www.halla.ac.kr/mbs/kr/jsp/board/list.jsp?boardId=23401&mcategoryId=&id=kr_060101000000')
# 일반 = boardId = 23401
client_errors = [400, 401, 403, 404, 408]
server_errors = [500,502, 503, 504]
print(time.strftime("%c", time.localtime(time.time())))
if req.status_code in client_errors:
print(req.status_code + ": 클라이언트 에러")
sys.exit(1)
elif req.status_code in server_errors:
print(req.status_code + ": 서버 에러")
sys.exit(1)
bot = telegram.Bot(token=my_token)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
posts = soup.select('td > a')
num = soup.find_all(title='공지')
for i in range(len(num)): # 공지로 위로 올라간 게시글 제외한 최신 게시글 분류
del posts[0]
split_posts = str(posts[0]).split("&")[2] # 가장 최신 공지랑 같은지 검사
if not(os.path.isfile(os.path.join(BASE_DIR, 'latest.txt'))):
new_file = open("latest.txt", 'w+',encoding='utf-8')
new_file.write(split_posts)
new_file.close()
with open(os.path.join(BASE_DIR, 'latest.txt'), 'r+',encoding='utf-8') as f_read: # DB 구현후 변경 에정
before = f_read.readline()
for post in posts: # 기존 크롤링 한 부분과 최신 게시글 사이에 게시글이 존재하는지 확인
split_post = str(post).split("&")[2]
print("post = " + post.text)
print("new = " + split_post)
print("before = " + before) # split_posts
if before == split_post:
print("최신글입니다.")
break
elif before != split_post:
url = "http://www.halla.ac.kr/mbs/kr/jsp/board/" + post.get('href')
print(url)
try:
if post != posts[5]: # 10번 post 이상 넘어가는지 확인 / 텔레그램 메시지가 url 10개 이상 한번에 못보냄
bot.sendMessage(chat_id=my_chat_id, text="일반공지 : " + post.text)
bot.sendMessage(chat_id=my_chat_id, text=url)
else:
break
except Exception as ex:
print("timeout") # 짧은 시간에 message를 과도하게 보내면 timeout이 뜨는것같다.
break # message를 많이 보내서 발생한다기 보다는, 한번에 보낼 수 있는 url의 양이 10개로 제한되어 있는듯
with open(os.path.join(BASE_DIR, 'latest.txt'),'w+',encoding='utf-8') as f_write:
f_write.write(split_posts)
print("\n")
마치며
한라대 공지 알림 봇을 사용하는 인원 수가 두자리를 넘겼다.
더 많이 늘어나기를 바라며,
버그는 더 발생하지 않기를 바라며 마치겠다.
감사합니다.