

1. 이진 나무 순회 (Tree Traverse)
전위 순회 (preorder traverse)
- 뿌리(root)를 먼저 방문
- 뿌리 → 왼쪽 자식 → 오른쪽 자식
- Ro → L → R
중위 순회 (inorder traverse)
- 왼쪽 하위 트리를 방문 후 뿌리(root)를 방문
- 왼쪽 자식 → 뿌리 → 오른쪽 자식
- L → Ro → R
후위 순회 (postorder traverse)
- 하위 트리 모두 방문 후 뿌리(root)를 방문
- 왼쪽 자식 → 오른쪽 자식 → 뿌리
- L → R → Ro
층별 순회 (level order traverse)
- 위 쪽 node들 부터 아래방향으로 차례로 방문
- 노드의 순서대로
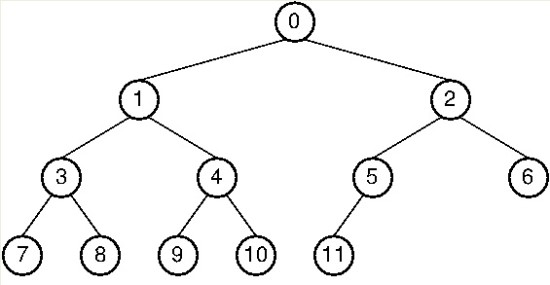
전위 순회 : 0->1->3->7->8->4->9->10->2->5->11->6
중위 순회 : 7->3->8->1->9->4->10->0->11->5->2->6
후위 순회 : 7->8->3->9->10->4->1->11->5->6->2->0
층별 순회 : 0->1->2->3->4->5->6->7->8->9->10->11
2. 알고리즘
시간 복잡도별 분류
- O(1)
- O(logn)
- 이분 탐색
- O(n)
- 최댓값 찾기, 순차 탐색
- O(nlogn)
- 병합 정렬, 퀵 정렬
- O(n^2)
- 선택 정렬, 삽입 정렬
- O(2^n)
- 하노이의 탑
3. 알고리즘 설계 기법
Divide and Conquer (분할 정복 알고리즘)
- 그대로 해결할 수 없는 문제를 작은 문제로 분할하여 문제를 해결하는 알고리즘
Greedy (탐욕 알고리즘)
- 현재 시점에서 가장 최적의 방법을 선택하는 알고리즘
Backtracking
- 모든 조합을 시도하여 문제의 답을 찾는 알고리즘
4. 트리
개념
- 계층적인 구조를 표현
- 조직도
- 디렉터리와 서브디렉터리 구조
- 가계도
- 트리는 노드(node)들과 노드들을 연결하는 링크(link)들로 구성
용어
- 루트 노드 (root node)
- 부모가 없는 노드
- 트리는 하나의 루트 노드만을 가진다
- 단말 노드 (leaf node)
- 자식이 없는 노드
- 내부(internal) 노드
- 리프 노드가 아닌 노드
- 링크 (link), edge, branch
- 노드를 연결하는 선
- 형제 (sibling)
- 같은 부모를 가지는 노드

- 노드의 크기(size)
- 자신을 포함한 모든 자손 노드의 개수
- C의 크기 = 6
- 노드의 깊이(depth)
- 루트에서 어떤 노드에 도달하기 위해 거쳐야 하는 간선의 수
- D의 깊이 = 2
- L의 깊이 = 3
- 노드의 레벨(level)
- 트리의 특정 깊이를 가지는 노드의 집합
- A의 레벨 = 1
- B, C의 레벨 = 2
- 노드의 차수(degree)
- 부(하위) 트리 갯수/간선수
- 각 노드가 지닌 가지의 수
- A의 차수 = 2
- B의 차수 = 3
- 트리의 차수(degree of tree)
- 트리의 최대 차수
- B가 최대 차수를 가짐 = 3
- 트리의 높이(height)
- 루트 노드에서 가장 깊숙히 있는 노드의 깊이
- 3
5. 해싱함수
해싱
- Hash Table이라는 기억공간을 할당하고, 해시 함수(Hash Table)이라는 기억공간을 할당하고, 해시함수(Hash Function)을 이용하여 레코드 키에 대한 Hash Table 내의 Home Address를 계산한 후 주어진 레코드를 해당 기억장소에 저장하거나 검색 작업을 수행하는 방식
- 해싱은 DAM(직접 접근)파일을 구성할 때 사용되며, 접근 속도는 빠르나 기억공간이 많이 요구된다
- 다른 방식에 비해 검색 속도가 가장 빠르다
- 삽입 삭제 작업의 빈도가 많을 때 유리한 방식이다
- 키-주소 변환 방법이라고도 한다
해시테이블 (Hash Table)
- 레코드를 한 개 이상 보관할 수 있는 Bucket들로 구성된 기억공간으로 보조기억장치에 구성할 수도 있고 주기억장치에 구성할 수도 있다
버킷 (Bucket)
- 하나의 주소를 갖는 파일의 한 구역을 의미
- 버킷의 크기는 같은 주소에 포함될 수 있는 레코드 수를 의미
슬롯 (Slot)
- 한 개의 레코드를 저장할 수 있는 공간으로 n개의 슬롯이 모여 하나의 버킷을 형성한다
Collision (충돌현상)
- 서로 다른 두 개 이상의 레코드가 같은 주소를 갖는 현상
Synonym
- 충돌로 인해 같은 Home Address를 갖는 레코드들의 집합
Overflow
- 계산된 Home Address의 Bucket 내에 저장할 기억공간이 없는 상태로, Bucket을 구성하는 Slot이 여러개일 때 Collision은 발생해도 Overflow는 발생하지 않을 수 있다.
해싱 함수 (Hasing Function)
제산법 (Division)
- 레코드키로 해시표의 크기보다 큰 수 중에서 가장 작은 소수로 나눈 나머지를 홈 주소로 삼는 방식
제곱법
- 레코드키 값을 제곱한 후 그 중간 부분의 값을 홈주소로 삼는 방식
폴딩법 (Folding)
- 레코드키 값을 여러 부분으로 나눈 후 각 부분의 값을 더하거나 XOR(배타적 논리합)한 값을 홈주소로 삼는 방식
기수변환법
- 키 숫자의 진수를 다른 진수로 변환시켜 주소 크기를 초과한 높은 자릿수를 절단하고, 이를 다시 주소 범위에 맞게 조정하는 방법
대수적 코딩법
- 키 값을 이루고 있는 각 자리의 비트 수를 한 다항식의 계수로 간주하고, 이 다항식을 해시표의 크기에 의해 정의된 다항식으로 나누어 얻은 나머지 다항식의 계수를 홈 주소로 삼는 방식
계수 분석법 (숫자 분석법)
- 키 값을 이루는 숫자의 분포를 분석하여 비교적 고른 자리를 필요한 만큼 선택해서 홈 주소로 삼는 방식
무작위법 (Random)
- 난수 (Random Number)를 발생시켜 나온 값을 홈 주소로 삼는 방식
6. 자료구조의 종류
배열(Array)
- 동일한 자료형의 데이터들이 같은 크기로 나열되어 순서를 갖고 있는 집합
선형 리스트(Linear List)
- 일정한 순서에 의해 나열된 자료 구조로, 배열을 이용하는 연속 리스트(Contiguous List)와 포인터를 이용하는 연결 리스트(Linked List)로 구분됨
스택(Stack)
- 리스트의 한쪽 끝으로만 자료의 삽입, 삭제 작업이 이루어지는 자료 구조
큐(Queue)
- 리스트의 한쪽에서는 삽입 작업이 이루어지고 다른 한쪽에서는 삭제 작업이 이루어지도록 구성한 자료 구조
트리(Tree)
- 정점(Node, 노드)과 선분(Branch, 가지)을 이용하여 사이클을 이루지 않도록 구성하는 그래프(Graph)의 특수한 형태
Notion 정리본
https://www.notion.so/mildsalmon/1-0d6f0735ed7e4b508b48500225790916