

1. DDL (데이터 정의어)
CREATE
- CREATE SCHEMA
- CREATE DOMAIN
- CREATE TABLE
- CREATE VIEW
- CREATE INDEX
정의하는 명령문
ALTER
- ALTER TABLE
정의를 변경하는 명령문
DROP
제거하는 명령문- RESTRICT
- 참조되는 테이블이 있다면 삭제 명령을 모두 취소한다
- CASCADE
- 참조되는 테이블이 있다면 모두 삭제한다.
2. DCL (데이터 제어어)
GRANT
권한 부여- 사용자 등급 지정
GRANT (사용자 등급) TO (사용자 ID 리스트) [IDENTIFIED BY 암호];
- 테이블 및 속성에 대한 권한 부여
GRANT (권한 리스트) ON (개체) TO (사용자) [WITH GRANT OPTION];- 권한 종류
- ALL, SELECT, INSERT, DELETE, UPDATE, ALTER 등
- WITH GRANT OPTION
- 부여받은 권한을 다른 사용자에게 다시 부여할 수 있는 권한을 부여함
- 권한 종류
REVOKE
권한 취소- 사용자 등급 해제
REVOKE (사용자등급) FROM (사용자 ID 리스트); - 테이블 및 속성에 대한 권한 취소
REVOKE [GRANT OPTION FOR] (권한 리스트) ON (개체) FROM (사용자) [CASCADE];- GRANT OPTION FOR
- 다른 사용자에게 권한을 부여할 수 있는 권한을 취소함
- CASCADE
- 권한 취소 시 권한을 부여받았던 사용자가 다른 사용자에게 부여한 권한도 연쇄적으로 취소함
- GRANT OPTION FOR
COMMIT
- 트랜젝션이 성공적으로 끝나면 데이터베이스가 새로운 일관성 상태를 가지기 위해
변경된 모든 내용을 데이터 베이스에 반영 - Auto Commit
- COMMIT 명령을 실행하지 않아도 DML문이 성공적으로 완료되면 자동으로 COMMIT되고, DML이 실패하면 자동으로 ROLLBACK되는 기능
ROLLBACK
- 아직
COMMIT되지 않은 변경된 모든 내용들을 취소하고 데이터베이스를 이전 상태로 되돌리는명령어
SAVEPOINT
- 트랜잭션 내에
ROLLBACK 할 위치인 저장점을 지정하는 명령어
3. DML (데이터 조작어)
INSERT INTO ~
- 기본 테이블에 새로운 튜플을
삽입
INSERT INTO (테이블명[속성명1, 속성명2...]) VALUES (데이터1, 데이터2 ...);
DELETE FROM ~
- 기본 테이블에 있는 튜플들 중에서 특정 튜플(행)을
삭제
DELETE FROM (테이블명) [WHERE 조건];
- 모든 레코드를 삭제하더라도 테이블 구조는 남아 있다
UPDATE ~ SET ~
- 기본 테이블에 있는 튜플들 중에서
특정 튜플의 내용을 변경
UPDATE (테이블명) SET (속성명 = 데이터[, 속성명=데이터, ...]) [WHERE 조건];
SELECT ~ FROM ~ WHERE ~
검색
SELECT [PREDICATE] (속성명) [AS 별칭] [WINDOW함수 OVER(PARTITION BY (속성명1, 속성명2,..) ORDER BY (속성명3, 속성명4...) [AS 별칭]]
FROM (테이블명) [, 테이블명2]
[WHERE 조건]
[GROUP BY 속성명, 속성명2..]
[HAVING 조건]
[ORDER BY 속성명 [ASC | DESC]];
- PREDICATE
- 불러올 튜플의 수를 제한
- ALL
- 모든 튜플을 검색
- DISTINCT
- 중복된 튜플이 있으면 그 중 첫 번째 한 개만 검색
- DISTINCTROW
- 중복된 튜플을 제거하고 한 개만 검색, 선택된 속성의 값이 아닌, 튜플 전체를 대상으로 함
- ALL
- 불러올 튜플의 수를 제한
- AS
- 속성 및 연산의 이름을 다른 제목으로 표시하기 위해 사용
- WINDOW 함수
- PARTITION BY
- WINDOW 함수가 적용될 범위로 사용할 속성을 지정
- ORDER BY
- PARTITION 안에서 정렬 기준으로 사용할 속성을 지정
- PARTITION BY
- GROUP BY
- 특정 속성을 기준으로 그룹화하여 검색
- 그룹 함수와 함께 사용된다.
- HAVING
- GROUP BY와 함께 사용
- 그룹에 대한 조건을 지정
- WHERE
- BETWEEN #01/01/69# AND #12/31/22#
- #01/01/69# 과 #12/31/22# 사이의 튜플 검색
날짜 데이터는 숫자로 취급하지만 '' 또는 #으로 묶어준다
- IS
- =
- NOT IN
- 포함되지 않은 데이터를 의미
- EXISTS
- IN과 비슷한 역할
- 먼저 겉 테이블에 접근하여 하나의 레코드를 가져오고 그 레코드에 대해서 EXISTS 이하의 서브쿼리를 실행하고 서브쿼리에 대한 결과가 존재하는지 확인
- IN
- IN 이하의 서브쿼리를 먼저 실행해서 그에 대한 요소를 가져오는 것
- BETWEEN #01/01/69# AND #12/31/22#
- ORDER BY
- 특정 속성을 기준으로 정렬하여 검색
- ASC
- 오름차순
- DESC
- 내림차순
- ASC
- 특정 속성을 기준으로 정렬하여 검색
JOIN
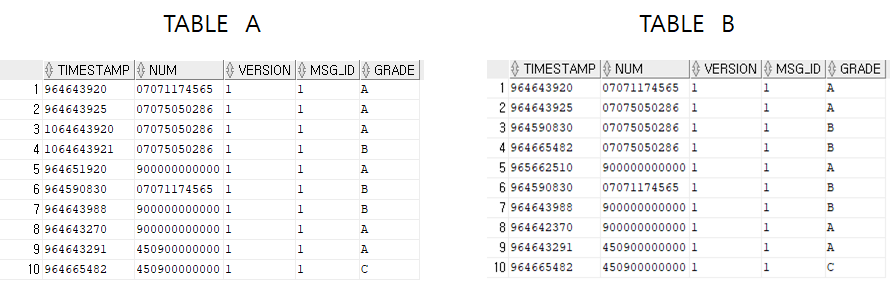
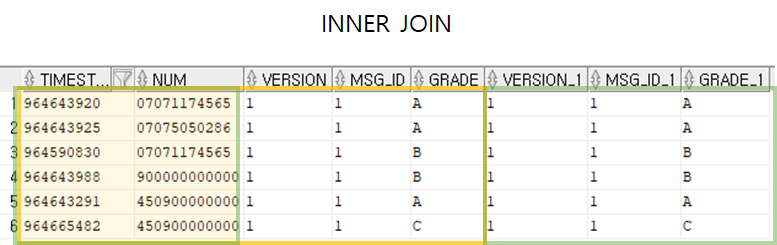
INNER JOIN
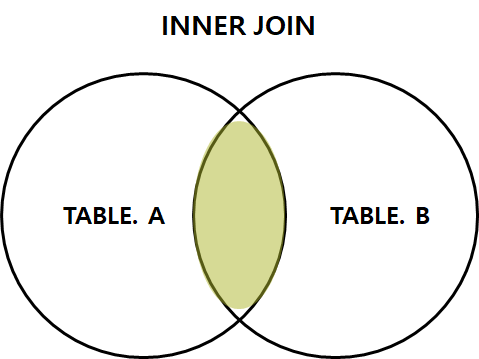
EQUI JOIN
- 연결 고리가 되는 공통 속성을 JOIN 속성이라고 함
- 공통 속성을 기준으로
=비교에 의해 같은 값을 가지는 행을 연결하여 결과를 생성
SELECT (속성명) FROM (테이블명1, 테이블명2) WHERE (테이블명1.속성명 = 테이블명2.속성명);- NATURAL JOIN
- 중복된 속성을 제거하여 같은 속성을 한 번만 표기하는 방법
SELECT (속성명) FROM (테이블명1) NATURAL JOIN (테이블명2); - JOIN ~ USING
SELECT (속성명) FROM (테이블명1) JOIN (테이블명2) USING (속성명);
NON-EQUI JOIN
- JOIN 조건에
= 조건이 아닌나머지 비교 연산자 (>, <, <>, ≥, ≤) 연산자를 사용하는 JOIN 방법
SELECT (속성명) FROM (테이블명1, 테이블명2) WHERE (NON-EQUI JOIN 조건);

- JOIN 조건에
OUTER JOIN
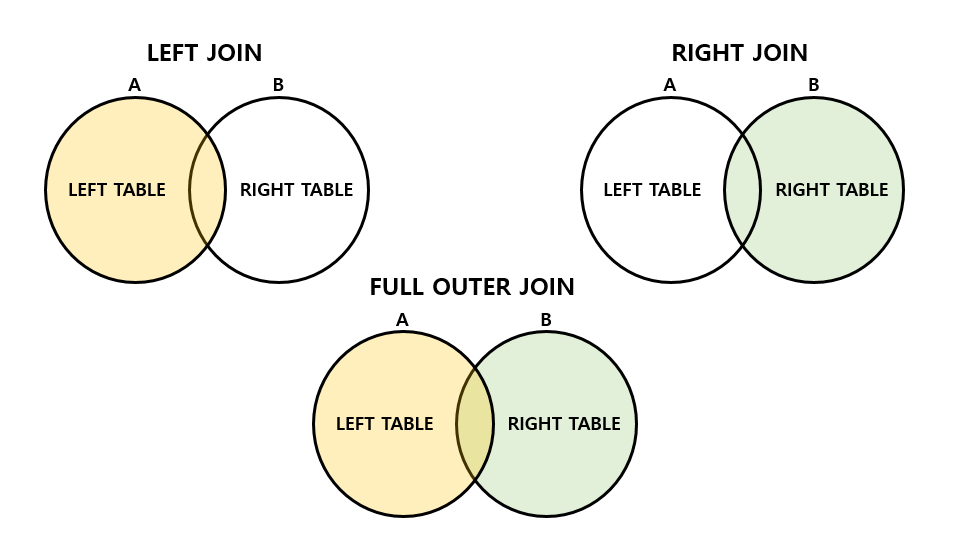
- JOIN 조건에 만족하지 않는 튜플도 결과로 출력하기 위한 JOIN 방법
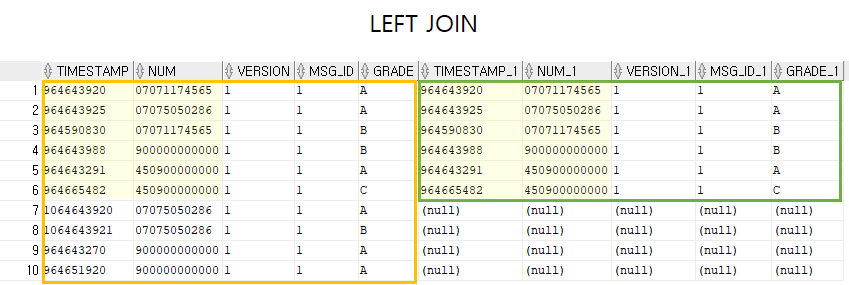
- LEFT OUTER JOIN
- INNER JOIN의 결과를 구한 후, 우측 항 릴레이션의 어떤 튜플과도 맞지 않는
좌측 항의 릴레이션에 있는 튜플들에 NULL 값을 붙여서 INNER JOIN의 결과에 추가한다
SELECT (속성명) FROM (테이블명1) LEFT OUTER JOIN (테이블명2) ON (테이블명1.속성명=테이블명2.속성명);SELECT (속성명) FROM (테이블명1, 테이블명2) WHERE (테이블명1.속성명=테이블명2.속성명(+)); - INNER JOIN의 결과를 구한 후, 우측 항 릴레이션의 어떤 튜플과도 맞지 않는
- LEFT OUTER JOIN
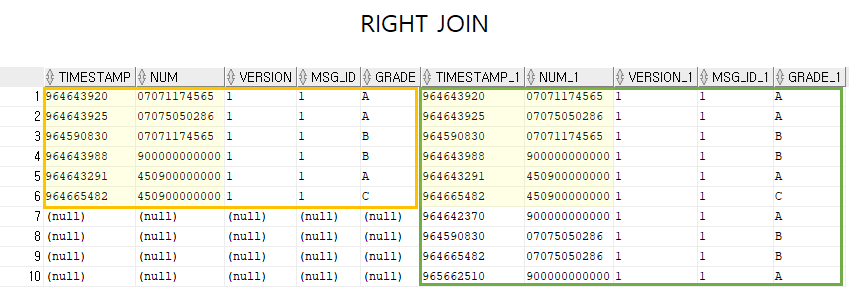
- RIGHT OUTER JOIN
- INNER JOIN의 결과 후, 좌측 항 릴레이션의 어떤 튜플과도 맞지 않는 `우측 항의 릴레이션에 있는 튜플들에 NULL 값`을 붙여서 INNER JOIN의 결과에 추가한다
```
SELECT (속성명)
FROM (테이블명1) RIGHT OUTER JOIN (테이블명2)
ON (테이블명1.속성명=테이블명2.속성명);
```
```
SELECT (속성명)
FROM (테이블명1, 테이블명2)
WHERE (테이블명1.속성명(+)=테이블명2.속성명);
```
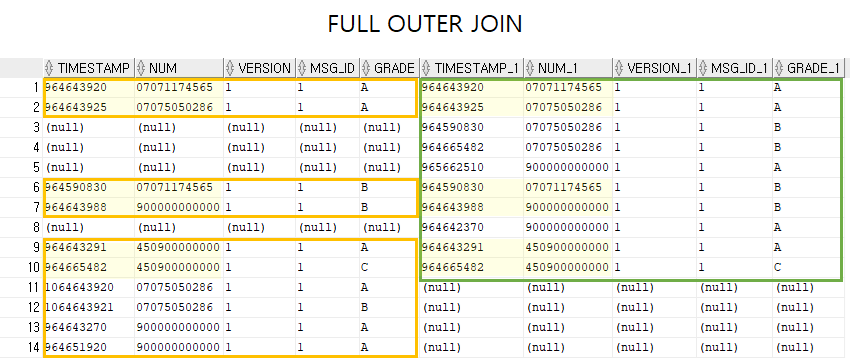
- FULL OUTER JOIN
- LEFT OUTER JOIN과 RIGHT OUTER JOIN을 합쳐 놓은 것
```
SELECT (속성명)
FROM (테이블명1) FULL OUTER JOIN (테이블명2)
ON (테이블명1.속성명=테이블명2.속성명);
```
- SELF JOIN
같은 테이블에서 2개의 속성을 연결하여 EQUI JOIN을 하는 JOIN 방법
SELECT (속성명) FROM (테이블명1) [AS] (별칭1) JOIN (테이블명1) [AS] (별칭2) ON (별칭1.속성명=별칭2.속성명);SELECT (속성명) FROM (테이블명1) [AS] (별칭1), (테이블명1) [AS] (별칭2) WHERE (별칭1.속성명=별칭2.속성명);



조건 연산자
- 비교 연산자
- =, <>, >, <, ≥, ≤
- 논리 연산자
- NOT, AND, OR
- LIKE 연산자
- 대표 문자를 이용해 지정된 속성의 값이 문자 패턴과 일치하는 튜플을 검색하기 위해 사용
- %
- 모든 문자를 대표
- 김%
- 김씨 성을 가진 모두
- _
- 문자 하나를 대표
- 김_진
- 김으로 시작해서 진으로 끝나는 사람
- #
- 숫자 하나를 대표
- %
- 대표 문자를 이용해 지정된 속성의 값이 문자 패턴과 일치하는 튜플을 검색하기 위해 사용
연산자 우선순위
- 산술 연산자
- x, /, +, -
- 왼쪽에서 오른쪽으로 갈수록 낮아진다
- x, /, +, -
- 관계 연산자
- =, <>, >, ≥, <, ≤
- 모두 같다
- =, <>, >, ≥, <, ≤
- 논리 연산자
- NOT, AND, OR
- 왼쪽에서 오른쪽으로 갈수록 낮아진다
- NOT, AND, OR
- 산술 > 관계 > 논리 순으로 연산자 우선순위가 결정됨
그룹 함수
- COUNT(속성명)
- 그룹별 튜플 수를 구하는 함수
- SUM(속성명)
- 그룹별 합계를 구하는 함수
- AVG(속성명)
- 그룹별 평균을 구하는 함수
- MAX(속성명)
- 그룹별 최대값을 구하는 함수
- MIN(속성명)
- 그룹별 최소값을 구하는 함수
- STDDEV(속성명)
- 그룹별 표준편차를 구하는 함수
- VARIANC(속성명)
- 그룹별 분산을 구하는 함수
- ROLLUP(속성명, 속성명, ...)
- 인수로 주어진 속성을 대상으로 그룹별 소계를 구하는 함수
- 속성의 개수가 n개이면 n+1 레벨까지, 하위 레벨에서 상위 레벨 순으로 데이터가 집계
- CUBE(속성명, 속성명...)
- ROLLUP과 유사한 형태이나 CUBE는 인수로 주어진 속성을 대상으로 모든 조합의 그룹별 소계를 구한다
- 속성의 개수가 n개이면, $2^n$레벨까지, 상위 레벨에서 하위 레벨 순으로 데이터가 집계된다.
WINDOW 함수
- GROUP BY절을 이용하지 않고 함수의 인수로 지정한 속성을 범위로 하여 속성의 값을 집계한다
- 함수의 인수로 지정한 속성이 대상 레코드의 범위가 된다
- 이를 윈도우라 한다
- WINDOW 함수
- ROW_NUMBER()
- 윈도우별 각 레코드에 대한 일련 번호를 반환
- RANK()
- 윈도우별로 순위를 반환하며, 공동 순위를 반영
- DENSE_RANK()
- 윈도우별로 순위를 반환, 공동 순위를 무시하고 순위를 부여
- ROW_NUMBER()
4. 정규화(Normalization)
이상(Anomaly)의 개념 및 종류
- 데이터들이 불필요하게 중복되어 릴레이션 조작 시 예기치 못한 곤란한 현상이 발생하는 것
삽입 이상(Insertion Anomaly)
- 릴레이션에 데이터를 삽입할 때 의도와는 상관없이 원하지 않는 값들도 함께 삽입되는 현상
삭제 이상(Deletion Anomaly)
- 릴레이션에서 한 튜플을 삭제할 때 의도와는 상관없는 값들도 함께 삭제되는 연쇄가 일어나는 현상
갱신 이상(Update Anomaly)
- 릴레이션에서 튜플에 있는 속성값을 갱신할 때 일부 튜플의 정보만 갱신되어 정보에 모순이 생기는 현상
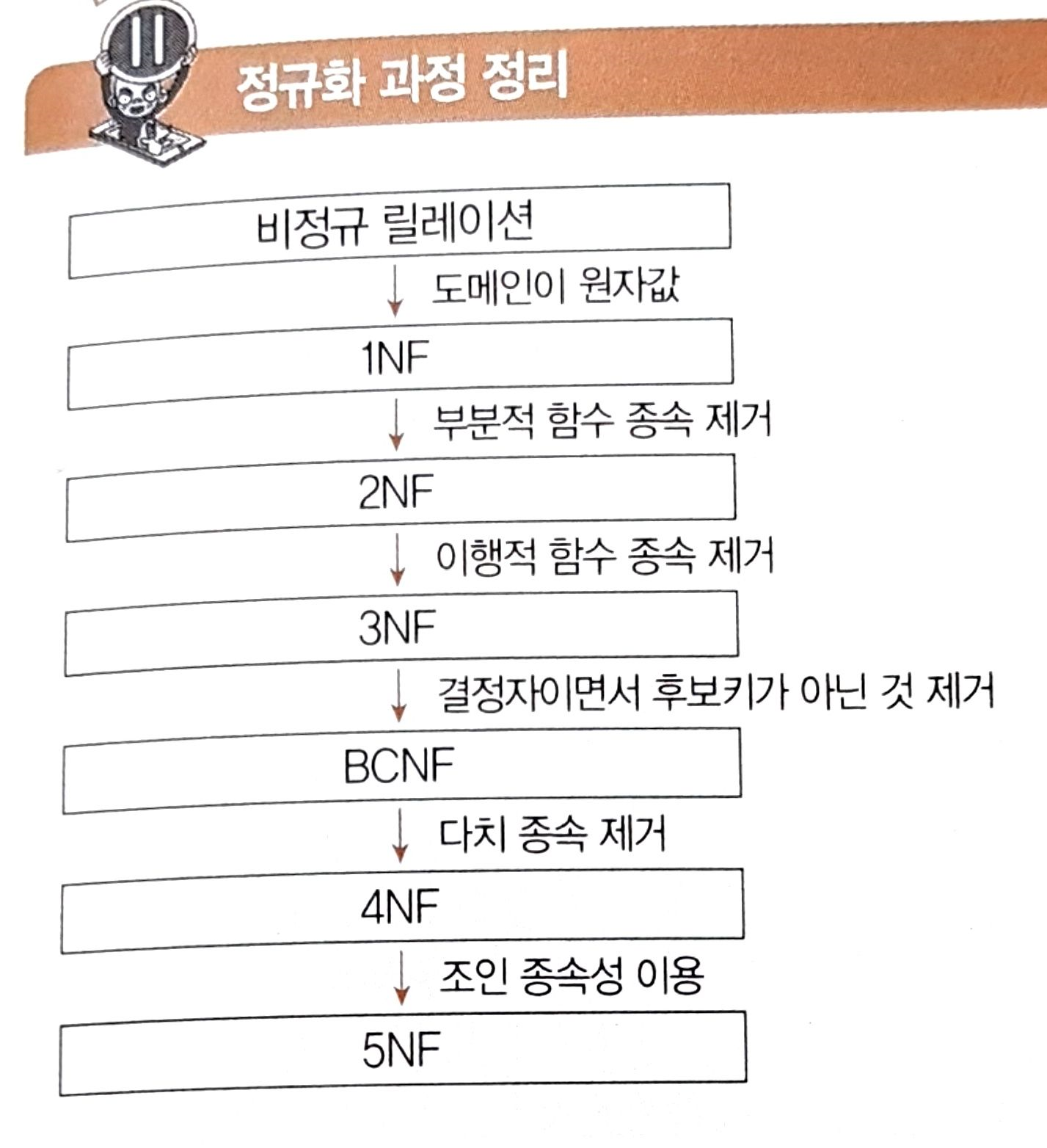
정규화 과정
두부이걸다줘 = 도부이결다조
- 도메인이 원자값
- 부분적 함수 종속 제거
- 이행적 함수 종속 제거
- 결정자이면서 후보키가 아닌 것 제거
- 다치 종속 제거
- 조인 종속성 이용

1NF(제1정규형)
- 릴레이션에 속한 모든 도메인(Domain)이 원자값(Automic Value)만으로 되어 있는 정규형
- 릴레이션이 모든 속성 값이 원자 값으로만 되어 있는 정규형
2NF(제2정규형)
- 릴레이션 R이 1NF
- 기본키가 아닌 모든 속성이 기본키에 대하여 완전 함수적 종속을 만족하는 정규형
3NF(제3정규형)
- 릴레이션 R이 2NF
- 기본키가 아닌 모든 속성이 기본키에 대해 이행적 종속을 만족하지 않는 정규형
이행적 종속(Transitive Dependency)관계
- A→B이고 B→C일 때 A→C를 만족하는 관계
BCNF(Boyce-Codd 정규형)
- 릴레이션 R에서 결정자가 모두 후보키인 정규형
- 강한 제3정규형
BCNF의 제약 조건
- 키가 아닌 모든 속성은 각 키에 대하여 완전 종속해야한다
- 키가 아닌 모든 속성은 그 자신이 부분적으로 들어가 있지 않은 모든 키에 대하여 완전 종속해야 한다
- 어떤 속성도 키가 아닌 속성에 대해서는 완전 종속할 수 없다
결정자(Determinant)
- 속성 간의 종속성을 규명할 때 기준이 되는 값
종속자(Dependent)
- 결정자의 값에 의해 정해지는 값
4NF(제4정규형)
- 릴레이션 R에 다치 종속 ->>가 성립하는 경우 R의 모든 속성이 A에 함수적 종속 관계를 만족하는 정규형
다치 종속(Multi Valued Dependency, 다가 종속)
- 어떤 복합 속성(A, C)에 대응하는 B값의 집합이 A값에만 종속되고 C값에는 무관하면 B는 A에 다치 종속
- A->>B로 표기
5NF(제5정규형, PJ/NF)
- 릴레이션 R의 모든 조인 종속이 R의 후보키를 통해서만 성립되는 정규형
조인 종속(Join Dependency)
- 릴레이션 R이 자신의 프로젝션(projection) (A,B,C..)을 모두 조인한 결과가 자신과 동일한 경우 릴레이션 R은 조인 종속(A,B,C...)을 만족한다고 한다
5. 반정규화(Denormalization)
- 정규화된 데이터 모델을 통합, 중복, 분리하는 과정
테이블 통합
두 개의 테이블이 조인(Join)되는 경우가 많아 하나의 테이블로 합쳐 사용하는 것이 성능 향상에 도움이 될 경우 수행

테이블 통합의 종류
- 1:1 관계 테이블 통합, 1:N 관계 테이블 통합, 슈퍼타입/서브타입 테이블 통합

테이블 분할
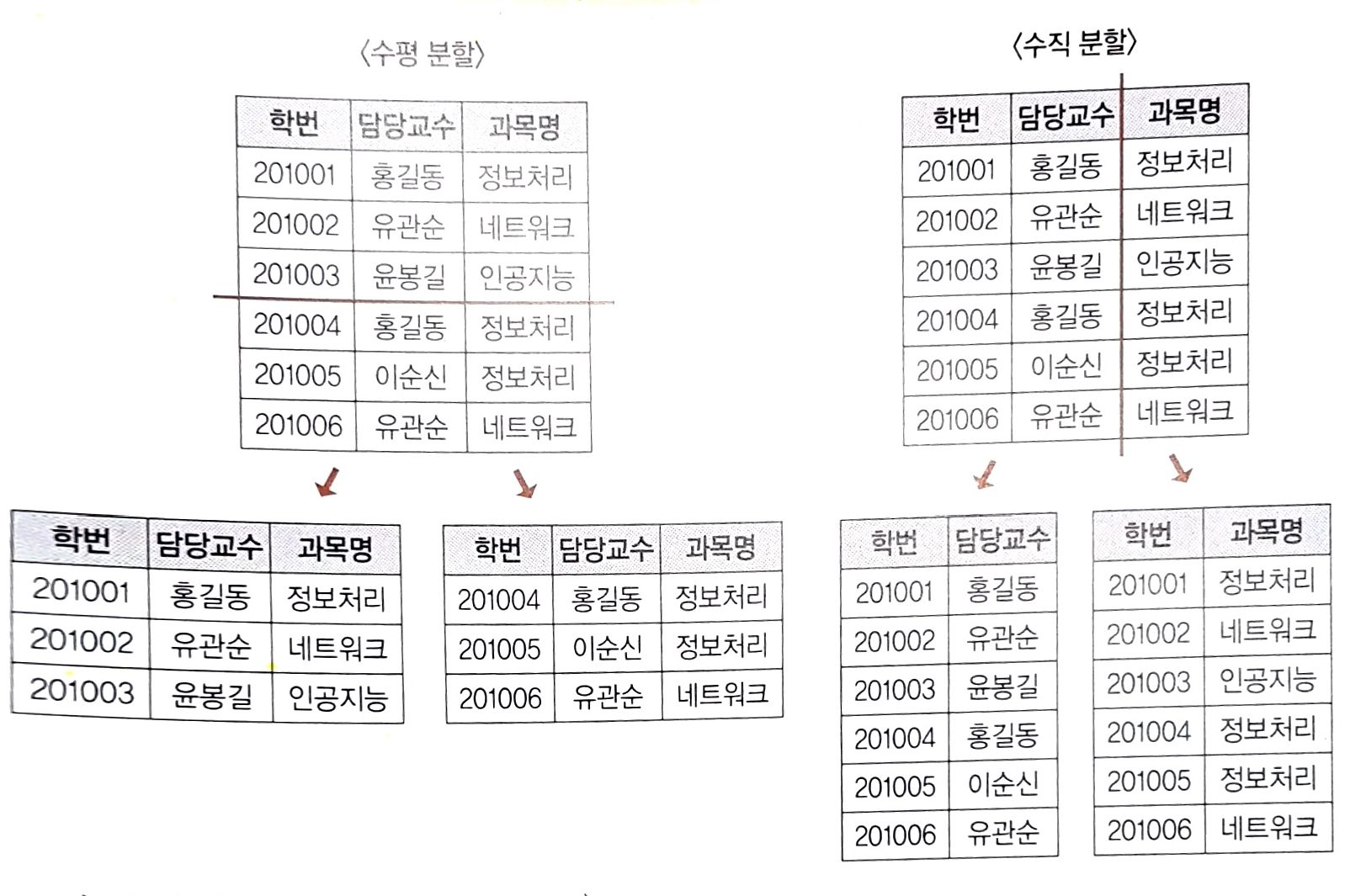
테이블을 수직 또는 수평으로 분할하는 것

수평 분할(Horizontal Partitioning)
- 레코드(Record)를 기준으로 테이블을 분할하는 것
- 레코드별로 사용 빈도의 차이가 큰 경우 사용 빈도에 따라 테이블을 분할한다
수직 분할(Vertical Partitioning)
- 하나의 테이블에 속성이 너무 많을 경우 속성을 기준으로 테이블을 분할하는 것
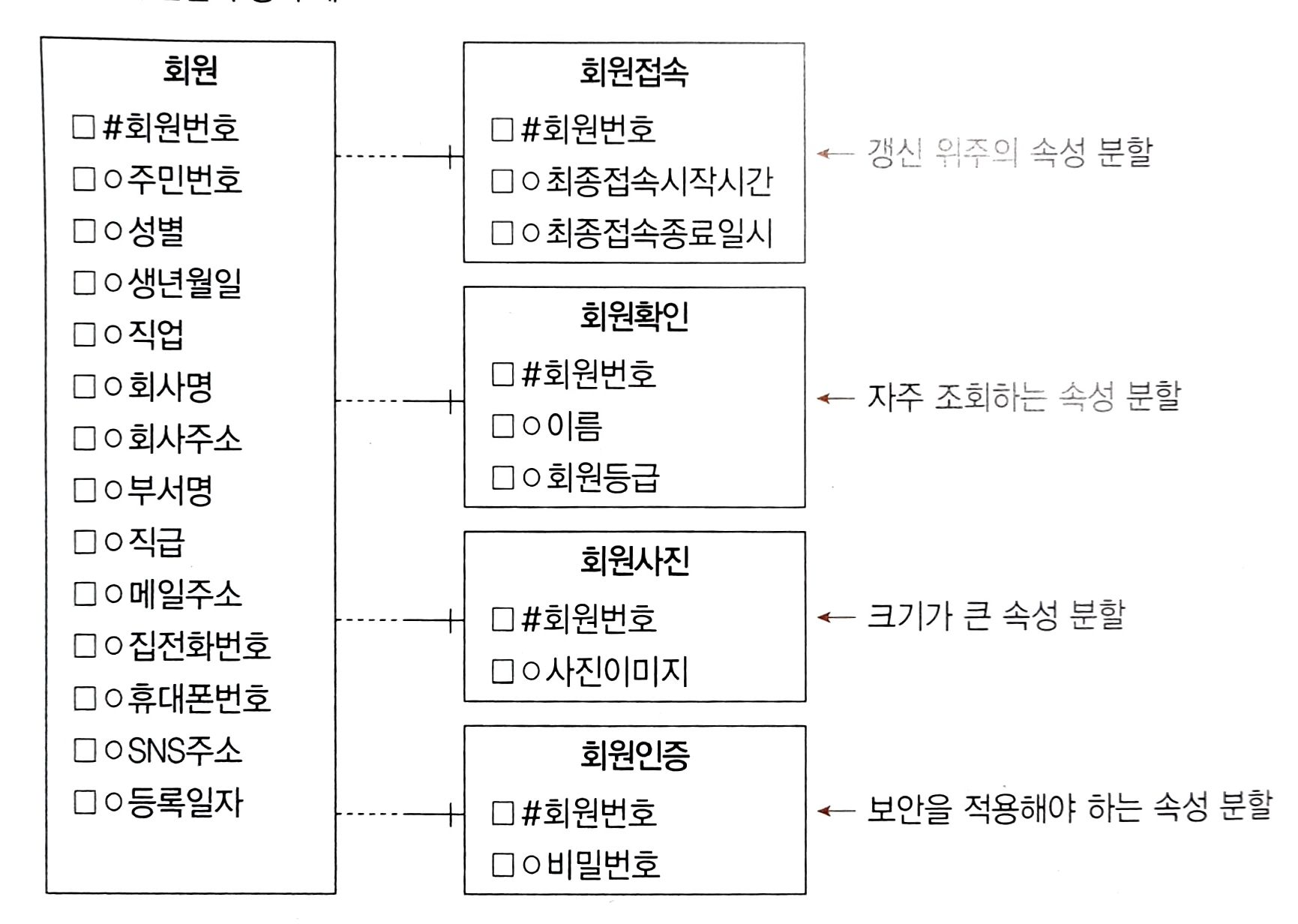
갱신 위주의 속성 분할
- 데이터 갱신 시 레코드 잠금으로 인해 다른 작업을 수행할 수 없으므로 갱신이 자주 일어나는 속성들을 수직 분할하여 사용한다
자주 조회되는 속성 분할
- 테이블에서 자주 조회되는 속성이 극히 일부일 경우 자주 사용되는 속성들을 수직 분할하여 사용한다
크기가 큰 속성 분할
- 이미지나 2GB 이상 저장될 수 있는 텍스트 형식 등으로 된 속성들을 수직 분할하여 사용한다.
보안을 적용해야 하는 속성 분할
- 테이블 내의 특성 속성에 대해 보안을 적용할 수 없으므로 보안을 적용해야 하는 속성들을 수직 분할하여 사용
중복 테이블 추가
여러 테이블에서 데이터를 추출해서 사용하거나 다른 서버에 저장된 테이블을 이용해야 하는 경우 중복 테이블을 추가하여 작업의 효율성을 향상시킨다
중복 테이블을 추가하는 방법
집계 테이블의 추가
- 집계 데이터를 위한 테이블을 생성하고, 각 원본 테이블에 트리거(Trigger)를 설정하여 사용하는 것
- 트리거의 오버헤드(Overhead)에 유의해야 한다
진행 테이블의 추가
- 이력 관리 등의 목적으로 추가하는 테이블
- 적절한 데이터 양의 유지와 활용도를 높이기 위해 기본키를 적절히 설정한다.
특정 부분만을 포함하는 테이블의 추가
- 데이터가 많은 테이블의 특정 부분만을 사용하는 경우 해당 부분만으로 새로운 테이블을 생성
중복 속성 추가
- 조인해서 데이터를 처리할 때 데이터를 조회하는 경로를 단축하기 위해 자주 사용하는 속성을 하나 더 추가하는 것
6. RDB의 제약 조건
무결성
데이터베이스에 저장된 데이터 값과 그것이 표현하는 현실 세계의 실제 값이 일치하는 정확성을 의미
개체 무결성(Entity Integrity, 실체 무결성)
- 기본 테이블의 기본키를 구성하는 어떤 속성도 Null 값이나 중복값을 가질 수 없다는 규정
도메인 무결성(Domain Integrity, 영역 무결성)
- 주어진 속성 값이 정의된 도메인에 속한 값이어야 한다는 규정
참조 무결성(Referential Integrity)
- 외래키값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 한다
사용자 정의 무결성(User-Defined Integrity)
- 속성 값들이 사용자가 정의한 제약 조건에 만족해야 한다는 규정
7. 데이터베이스 설계
설계 순서
요구 조건 분석 → 개념적 설계 → 논리적 설계 → 물리적 설계 → 구현
요구 조건 분석
데이터베이스를 사용할 사람들로부터 필요한 용도를 파악하는 것
- 수행 업무, 필요한 데이터의 종류, 용도, 처리 형태, 흐름, 제약 조건 등을 수집
개념적 설계(정보 모델링, 개념화)
현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
- 개념 스키마 모델링과 트랜잭션 모델링을 병행 수행
- 요구 조건 명세를 DBMS에 독립적인 E-R 다이어그램으로 작성
- DBMS에 독립적인 개념 스키마를 설계
논리적 설계(데이터 모델링)
현실 세계에서 발생하는 자료를 컴퓨터가 이해하고 처리할 수 있는 물리적 저장장치에 저장할 수 있도록 변환하기 위해 특정 DBMS가 지원하는 논리적 자료 구조로 변환시키는 장치
- 필드로 기술된 데이터 타입과 이 데이터 타입들 간의 관계로 표현되는 논리적 구조의 데이터로 모델화
- 논리적 데이터베이스 구조로 매핑(mapping)
- 개념 스키마를 평가 및 정제
- DBMS에 따라 서로 다른 논리적 스키마를 설계하는 단계
트랜잭션의 인터페이스를 설계- 관계형 데이터베이스라면 테이블을 설계하는 단계
물리적 설계(데이터 구조화)
논리적 구조로 표현된 데이터를 디스크 등의 물리적 저장장치에 저장할 수 있는 물리적 구조의 데이터로 변환하는 과정
- 다양한 데이터베이스 응용에 대해 처리 성능을 얻기 위해 데이터베이스 파일의 저장 구조 및 액세스 경로를 결정한다
- 저장 레코드의 형식, 순서, 접근 경로와 같은 정보를 사용하여 데이터가 컴퓨터에 저장되는 방법을 묘사
- 레코드 집중의 분석 및 설계
데이터베이스 구현
논리적 설계 단계와 물리적 설계 단계에서 도출된 데이터 베이스 스키마를 파일로 생성하는 과정
- DDL을 이용하여 데이터베이스 스키마를 기술한 후 컴파일하여 빈 데이터베이스 파일을 생성한다
- 빈 데이터베이스 파일에 데이터를 입력한다
- 응용 프로그램을 위한 트랜잭션을 작성한다
- 데이터베이스 접근을 위한 응용 프로그램을 작성한다.
8. 트랜잭션
트랜잭션 특성
- Atomicity (원자성)
- 트랜잭션 내의 모든 명령은 반드시 완벽히 수행되어야 하며, 어느 하나라도 오류가 발생하면 트랜잭션 전부가 취소되어야 한다
Commit(완료)되거나Rollback(복구)되어야 한다
- Consistency (일관성)
- 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다
- Isolation (독립성, 격리성, 순차성)
- 수행중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다
- Durability (영속성, 지속성)
- 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
9. 스키마
- 데이터베이스의 구조와 제약조건에 관해 전반적인 명세를 기술한 것
속성(Attribute),개체(Entity),관계(Relation)에 대한 정의와 이를 유지해야 할제약조건들을 기술한 것- DB내에 어떤 구조로 데이터가 저장되는가를 나타내는 데이터베이스 구조
외부 스키마
- 실세계에 존재하는 데이터들을 어떤 형식, 구조, 배치 화면을 통해 사용자에게 보여줄 것인가
내부 스키마
- 물리적인 저장장치 입장에서 DB가 저장되는 방법을 기술한 것
- 내부 스키마에 의해 DB의 실행속도가 결정적으로 영향을 받기 때문에 DB의 구축목적에 따라 내부 스키마를 결정해야 한다
개념 스키마
- 조직 전체를 관장하는 입장에서 DB를 정의한 것
- DB 전체를 기술한 것이기 때문에 한 개만 존재한다.
10. 키 (key)
후보키 (Candidate Key)
릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별하기 위해 사용하는 속성들의 부분집합
기본키로 사용할 수 있는 속성들
후보키는 릴레이션에 있는 모든 튜플에 대해서 유일성과 최소성을 만족시켜야한다
유일성(Unique)
- 하나의 키 값으로 하나의 튜플만을 유일하게 식별할 수 있어야 함
최소성(Minimality)
- 모든 레코드들을 유일하게 식별하는 데 꼭 필요한 속성으로만 구성되어야 한다.
기본키 (Primary Key)
- 후보키 중에서 특별히 선정된 주키(Main Key)
- 중복된 값을 가질 수 없다
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
- 기본키는 후보키의 성질을 갖는다.
- 유일성, 최소성, 튜플을 식별하기 위해 반드시 필요한 키
- 기본키는 NULL 값을 가질 수 없다
대체키 (Alternate Key)
- 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키를 의미
- 보조키
슈퍼키 (Super Key)
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
- 모든 튜플에 대해 유일성은 만족시키지만, 최소성은 만족시키지 못한다
왜래키 (Foreign Key)
- 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합
- 참조되는 릴레이션의 기본키와 대응되어 릴레이션 간에 참조 관계를 표현하는 중요한 도구
- 외래키로 지정되면 참조 릴레이션의 기본키에 없는 값은 입력할 수 없다.
11. 데이터 모델
- 현실 세계의 정보들을 컴퓨터에 표현하기 위해서 단순화, 추상화하여 체계적으로 표현한 개념적 모델
데이터 모델의 구성 요소
- 개체 (Entity)
- 데이터베이스에 표현하려는 것
- 현실 세계의 대상체
- 속성 (Attribute)
- 파일 구조상의 데이터 항목 또는 데이터 필드에 해당
- 관계 (Relationship)
- 개체 간의 관계 또는 속성 간의 논리적인 연결
태이터 모델의 종류
- 개념적 데이터 모델
- 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
- 현실 세계에 존재하는 개체를 인간이 이해할 수 있는 정보 구조로 표현하기 때문에
정보 모델이라고도 함 - E-R 모델
- 논리적 데이터 모델
- 개념적 모델링 과정에서 얻은 개념적 구조를 컴퓨터가 이해하고 처리할 수 있는 컴퓨터 세계의 환경에 맞도록 변환하는 과정
- 필드로 기술된 데이터 타입과 이 데이터 타입들 간의 관계를 이용하여 현실 세계를 표현한다
- 물리적 데이터 모델
데이터 모델에 표시할 요소
- 구조 (Structure)
- 개체 타입들 간의 관계
- 데이터 구조 및 정적 성질을 표현
- 연산 (Operation)
- 실제 데이터를 처리하는 작업에 대한 명세
- 데이터베이스를 조작하는 기본 도구
- 제약 조건 (Constraint)
- 실제 데이터의 논리적인 제약 조건
12. 관계형 데이터베이스의 구조
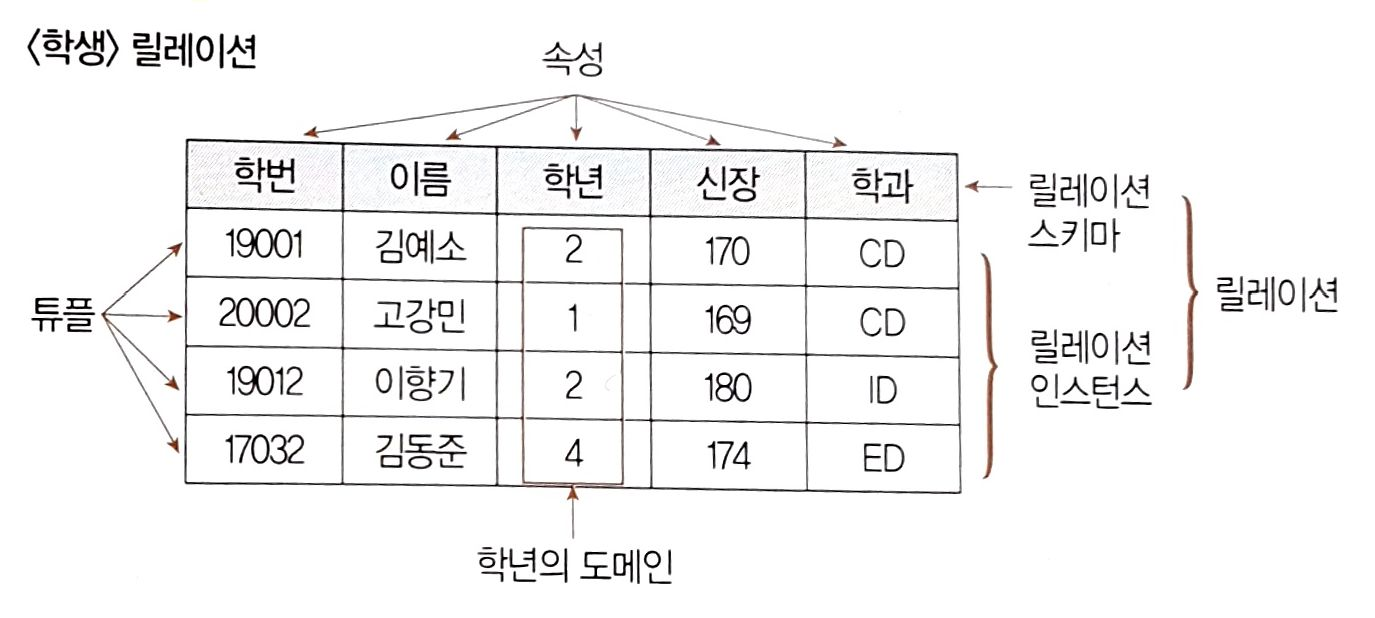
- 릴레이션은 데이터들을 표(Table)의 형태로 표현한 것으로 구조를 나타내는
릴레이션 스키마와 실제 값들인릴레이션 인스턴스로 구성
튜플(Turple)
- 릴레이션을 구성하는 각각의 행
- 튜플의 수를 카디널리티(Cardinality), 기수, 대응수라고 함
속성(Attribute)
- 데이터베이스를 구성하는 가장 작은 논리적 단위
- 개체의 특성을 기술
- 속성의 수를 디그리(Degree), 차수라고 함
릴레이션 인스턴스
- 데이터 개체를 구성하고 있는 속성들에 데이터 타입이 정의되어 구체적인 데이터 값을 갖고 있는 것
도메인 (Domain)
- 하나의 애트리뷰트가 취할 수 있는 같은 타입의 원자(Atomic)값들의 집합
- 실제 애트리뷰트 값이 나타날 때 그 값의 합법 여부를 시스템이 검사하는데에도 이용된다.
13. 데이터웨어하우스
OLAP (On-Line Analytical Processing)
데이터웨어하우스 활용 수단의 통칭인 BI (Business Intelligence)의 한 분야
최종 사용자가 정보에 직접 접근해 대화식으로 정보를 분석하고 의사결정에 활용하는 과정
연산
- Roll-up
- 분석할 항목에 대해 한 차원의 계층 구조를 따라 단계적으로 구체적인 내용의 상세 데이터로부터 요약된 형태의 데이터로 접근하는 기능
- Drill-down
- 분석할 항목에 대해 한 차원의 계층 구조를 따라 단계적으로 요약된 형태의 데이터로부터 구체적인 내용의 상세 데이터로 접근하는 기능
- Pivoting
- 보고서의 행, 열, 페이지 차원을 바꾸어 볼 수 있는 기능
- Slicing
- 다차원 데이터 항목들을 다양한 각도에서 조회하고 자유롭게 비교하는 기능
- Dicing
- 위와 동일하지만 slicing을 더 쪼개는 형태
종류
- ROLAP (Relational-OLAP)
- 관계형 데이터베이스와 관계형 질의어를 사용하여 다차원 데이터를 저장하고 분석함
- MOLAP (Multi-dimension OLAP)
- 다차원 데이터를 저장하기 위해 특수한 구조의 다차원 데이터베이스를 사용하고 데이터 검색 속도를 향상시키기 위해 큐브캐시(Cube Cache)라고 하는 주기억장치 속에 데이터 큐브를 보관함
- HOLAP (Hybrid OLAP)
- ROLAP와 MOLAP의 특성을 모두 가지고 있으며, 빠른 검색이 필요한 경우에는 요약을 메모리에 저장하고 기본 데이터나 다른 요약들은 관계형 데이터베이스에 저장함
- Roll-up
OLTP (On-Line Transaction Processing)
- 효율적인 기업 운영을 지원하기 위해 트랜잭션(처리 정보)을 수집하고 분류, 저장, 유지보수, 갱신, 검색하는 기능을 수행하는 실시간 거래 처리 시스템
- 기업의 본연 업무를 지원하는 기간 시스템
14. DBMS의 4대 목표
위치 투명성 (Location Trasparency)
- 데이터베이스의 실제 위치를 알 필요없이 단지 데이터베이스의 논리적인 명칭만으로 엑세스할 수 있음
중복 투명성 (Replication Transparency)
- 데이터가 여러 곳에 중복되어 있더라도 사용자는 마치 하나의 데이터만 존재하는 것처럼 사용 가능, 시스템은 자동으로 여러 자료에 대한 작업 수행
병행 투명성 (Concurrency Transparency)
- 다수의 트랜잭션이 동시에 실현되더라도 그 결과는 영향을 받지 않음
장애 투명성 (Failure Transparency)
- 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 트랜잭션을 정확히 처리함
15. TKPROF
추적 결과로 파악 할 수 있는 분석 정보 내용
- Parse
- Execute
- Fetch 수
- CPU 시간/경과된 시간
- 물리적/논리적 Reads
- 처리된 튜플(행) 수
- 라이브러리 캐시 Misses
- 파싱이 발생할 때의 사용자
- 커밋(Commit) / 롤백(Rollback)
16. 뷰(view)
- 하나이상의 테이블로부터 유도되는 가상테이블 이며 논리적 독립성이 제공된다
- 실제 테이블처럼 권한을 나눌 수 있다
- 특정 사용자가 볼 필요가 없는 다른 열들을 배제하고 뷰를 만든 후 해당 사용자에게 뷰에 대한 권한을 할당하면 테이블 전체에 대한 권한을 부여하지 않아도 된다
뷰는 자체적으로 인덱스를 가지지 않는다- 삽입 삭제 수정이 제한적이다.
17. 회복 (Recovery)
- 트랜잭션 도중에 손상된 데이터베이스를 이전 상태로 복귀하는 작업
- 트랜잭션의 연산을 수행할 때 데이터 베이스를 변경하기 전에 로그 데이터를 생성한다
- 취소(Undo) 연산으로 이미 데이터베이스에 쓰여진 것도 수정할 수 있다
장애의 유형
- 트랜잭션 장애
- 시스템 장애
- 미디어 장애
즉각 갱신 기법 (Immediate Update)
- 트랜잭션의 연산을 수행하여 데이터를 갱신할 때 실제 데이터 베이스에 반영하는 기법
- 갱신한 모든 내용을 로그(Log)에 보관
- 회복 작업을 위해 취소(Undo)와 재시도(Redo) 모두 사용 가능
연기 갱신 기법 (Deffered Update)
- 트랜잭션을 완료할 때까지 데이터베이스에 갱신을 연기하는 기법
- 트랜잭션 수행으로 갱신할 내용은 로그(Log)에 보관한다
- 트랜잭션이 부분 완료 시점에 Log의 기록을 실제 데이터 베이스에 반영한다
- 트랜잭션 수행 중에 장애가 발생하여 Rollback하여도 취소(Undo)할 필요가 없다
- 재시도(Redo) 작업을 통해 최근의 정상적인 데이터베이스로 회복한 후에 트랜잭션을 재실행 할 수 있다
검사점 기법 (Check Point)
- 트랜잭션 중간에 검사점을 로그에 보관하여 트랜잭션 전체를 취소하지 않고 검사점까지 취소할 수 있는 기법
그림자 페이지 대체 기법 (Shadow Paging)
- 트랜잭션의 연산으로 갱신할 필요가 있을 때 복사본인 그림자 페이지를 보관하는 기법
- 트랜잭션을 취소할 때 그림자 페이지를 이용하여 회복
- 로그(Log), 취소(Undo), 재시도(Redo)할 필요가 없다
18. NDBMS
- 그래프 형태
- 데이터의 종속성 문제를 해결하지 못한다
19. RDBMS
- 관계 DBMS
- 시스템의 부하가 커 수행 속도가 느리다.
20. 절차형 SQL
필수 요소
- DECLARE
- 대상이 되는 프로시저, 사용자 정의 함수 등을 정의
- BEGIN
- 프로시저, 사용자 정의 함수가 실행되는 시작점
- END
- 프로시저, 사용자 정의 함수가 실행되는 종료점
프로시저의 구성 요소
- DECLARE
- 변수 및 상수, 타입 선언
- BEGIN
- 시작
- 실행 및 서브루틴 생성
- CONTROL
- 단위 블록별 실행흐름을 제어
- SQL
- 데이터 관리를 위한 조회, 추가, 수정, 삭제
- EXCEPTION
- 실행중 발생가능한 예외상황 수행
- TRANSACTION
- 해당 기점만큼 DBMS에 반영 또는 복구
- END
- 종료
21. 데이터베이스의 정의
1. 통합된 데이터 (Integrated Data)
- 자료의 중복을 배제한 데이터의 모임
2. 저장된 데이터 (Stored Data)
- 컴퓨터가 접근할 수 있는 저장 매체에 저장된 자료
3. 운영 데이터 (Operational Data)
- 조직의 고유한 업무를 수행하는 데 존재 가치가 확실하고 없어서는 안 될 반드시 필요한 자료
4. 공용 데이터 (Shared Data)
- 여러 응용 시스템들이 공동으로 소유하고 유지하는 자료.
22. 결함 관리 프로세스
결함 관리 계획
- 전체 프로세스에 대한 결함 관리 일정, 인력, 업무 프로세스 등을 확보하여 계획을 수립
결함 기록
- 발견된 결함을 결함 관리 DB에 등록
결함 검토
- 등록된 결함을 검토하고 수정할 개발자에게 전달
결함 수정
- 개발자가 결함 수정
결함 재확인
- 개발자가 수정한 내용을 확인하고 다시 테스트를 수행
결함 상태 추적 및 모니터링 활동
- 결함 관리 상태를 한눈에 확인할 수 있도록 대시보드나 게시판 형태로 제공
최종 결함 분석 및 보고서 작성
- 발견된 결함에 대한 정보와 이해관계자들의 의견이 반영된 보고서를 작성하고 결함 관리를 종료
23. 데이터베이스의 보안
- 데이터베이스 영역에서 사용되는 암호화 방식에는 DES, RSA 등
24. 관계대수
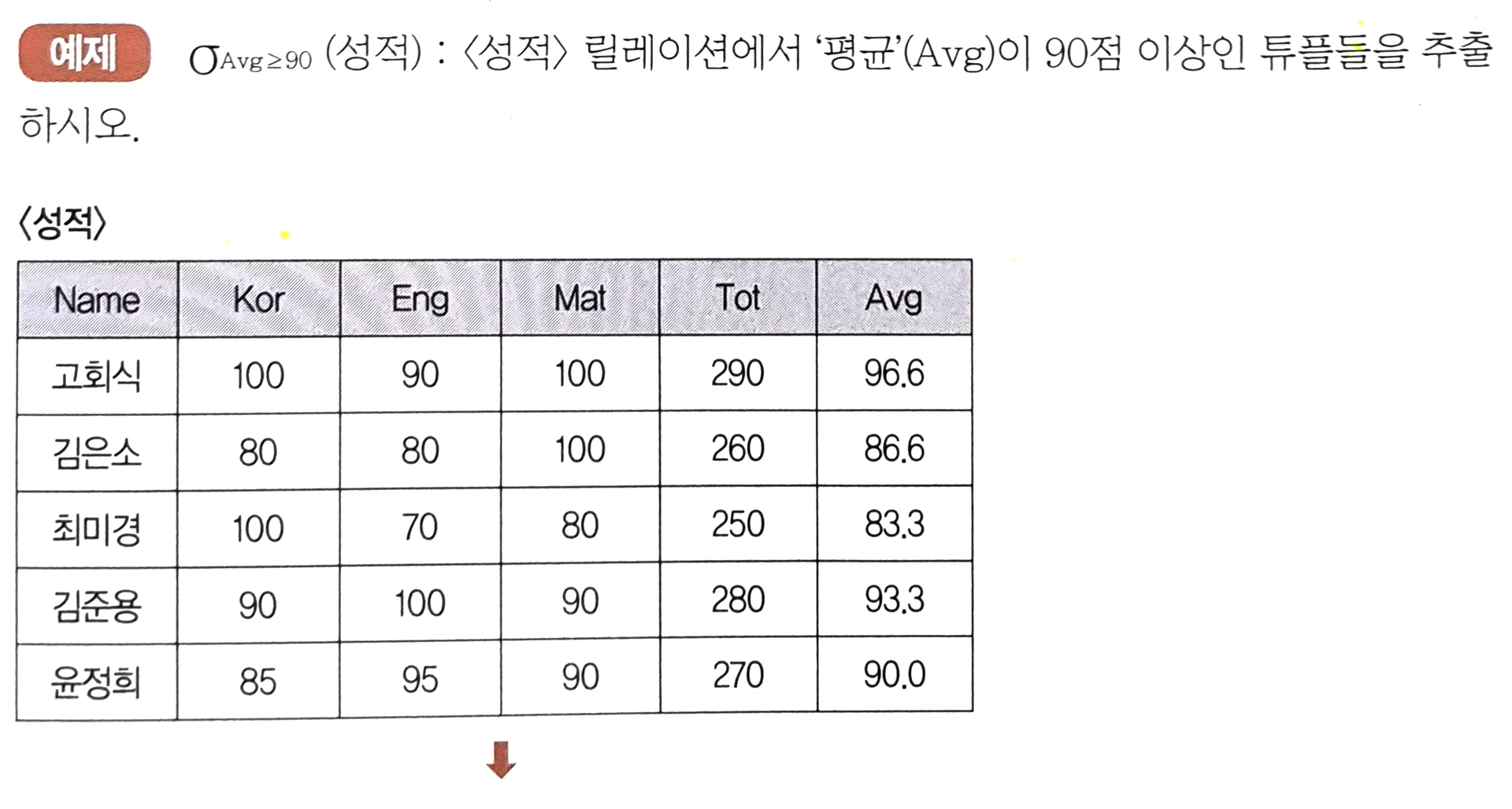
1. Select
- 릴레이션의 행에 해당하는 튜플을 구하는 것
- 수평 연산
표기 형식
- $\sigma_{<조건>}(R)$
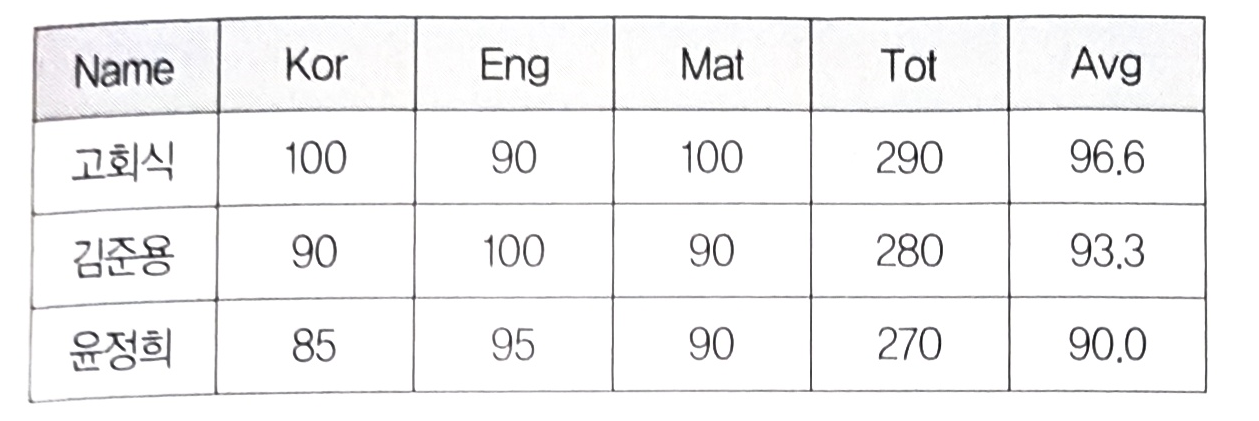
2. Project
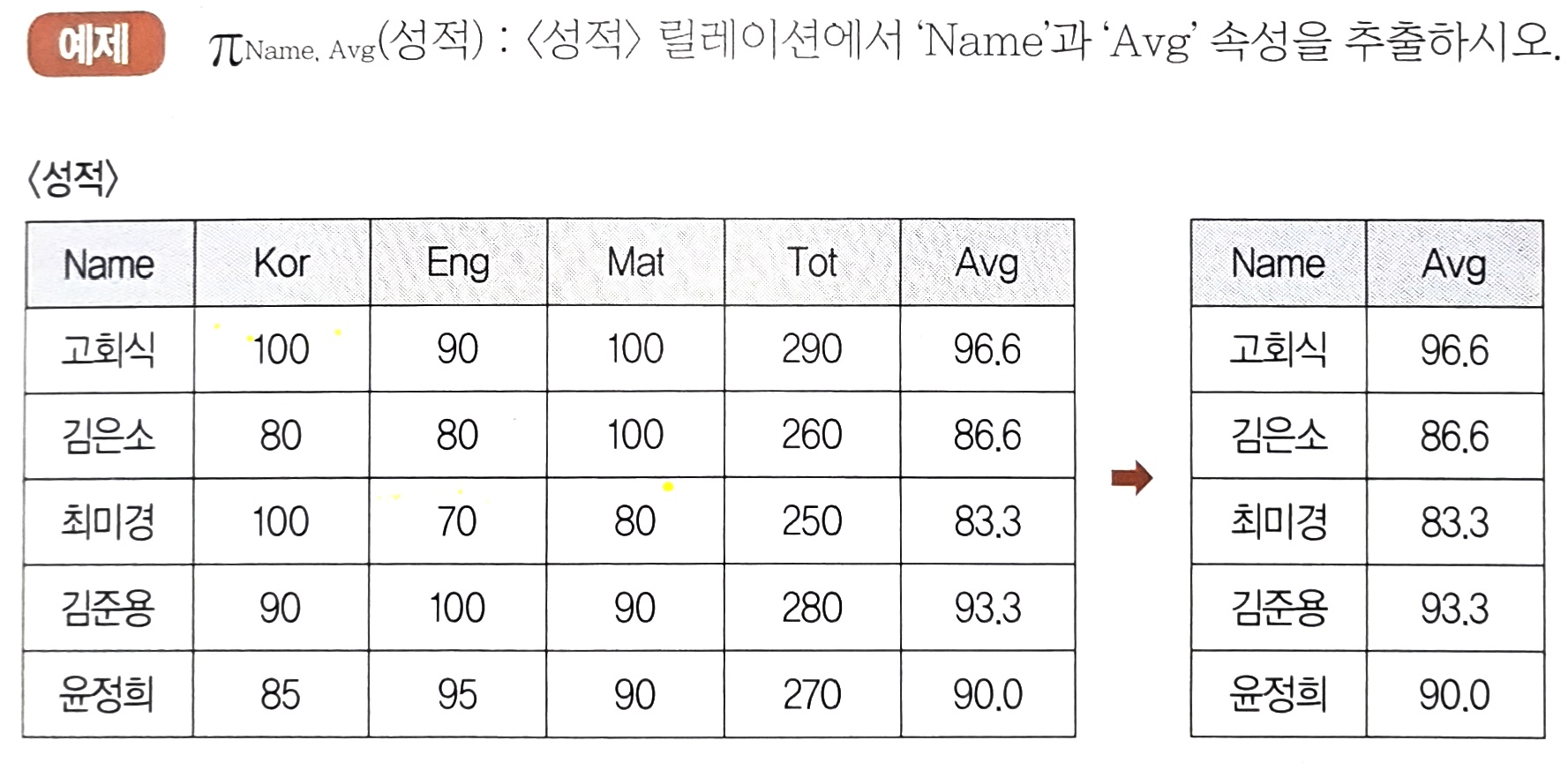
- 릴레이션의 열에 해당하는 Attribute를 추출하는 것
- 수직 연산자
표기 형식
- $\pi_{<속성리스트>}(R)$
3. Join
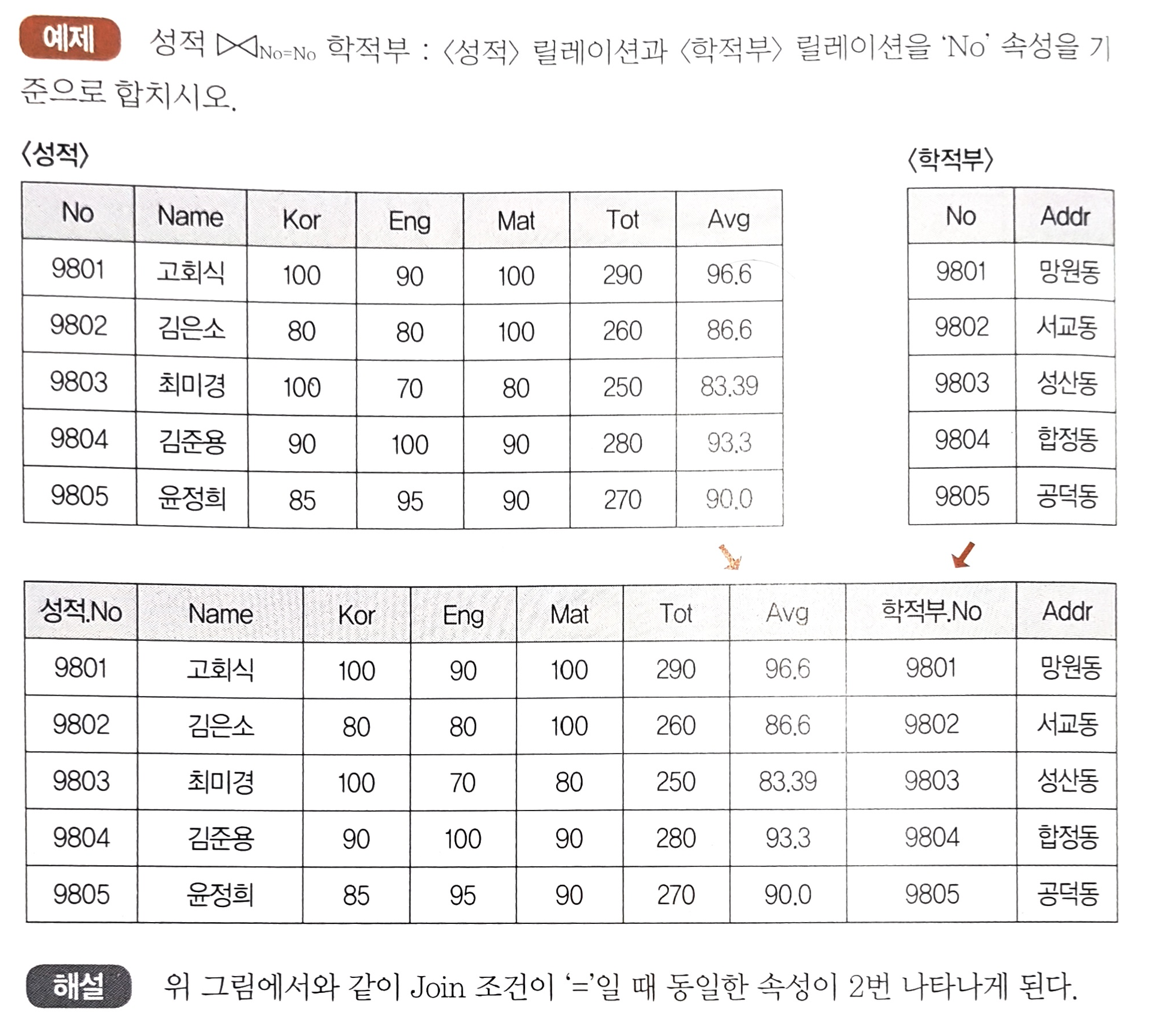
- 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산
- 만들어진 릴레이션의 차수는 조인된 두 릴레이션의 차수를 합한 것과 같다
- Cartesian Product교차곱)을 수행한 다음 Select를 수행한 것과 같다
표기 형식
- $R_{⋈키속성r=키속성s}S$
4. Division
- X⊃Y인 두 개의 릴레이션 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산
표기 형식
- $R[속성r/속성s]S$
- 속성r과 속성s는 동일 속성값을 가지는 속성

5. 일반 집합 연산자
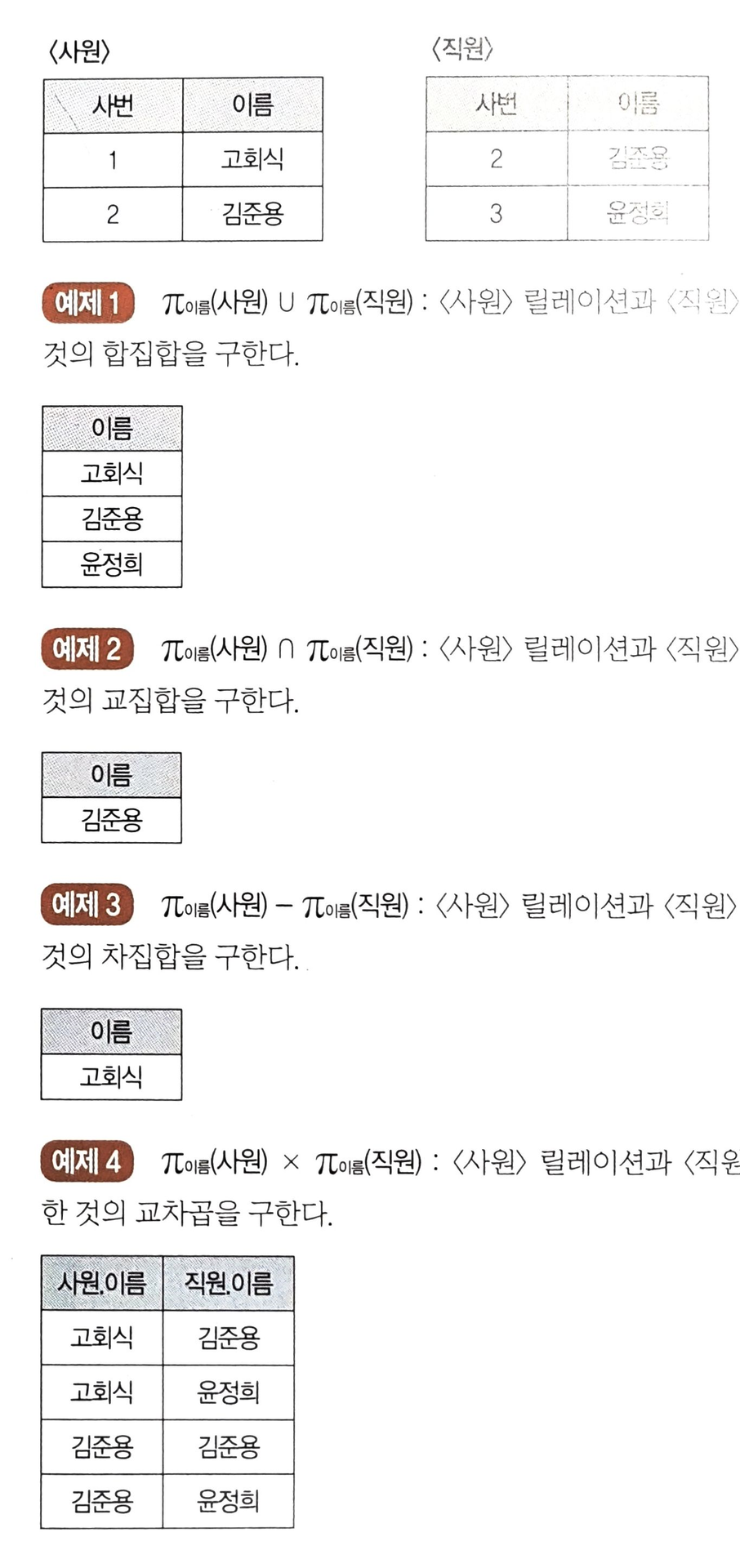
합집합 (UNION) ∪
- 두 릴레이션에 존재하는 튜플의 합집합을 구하되, 결과로 생성된 릴레이션에서 중복되는 튜플은 제거한다
교집합 (INTERSECTION) ∩
- 두 릴레이션에 존재하는 튜플의 교집합을 구하는 연산
차집합 (DIFFERENCE) -
- 두 릴레이션에 존재하는 튜플의 차집합을 구하는 연산
교차곱 (CARTESIAN PRODUCT) ×
- 두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산
25. 인덱스(Index)
- <키 값과 포인터> 쌍으로 구성되는 데이터구조로, 인덱스 설계 시에는 인덱스가 가리키는 데이터와는 별개로 추가적인 저장 공간이 필요하다는 것을 염두에 두어야 한다
인덱스 설계 시 고려사항
- 새로 추가되는 인덱스는 기존 액세스 경로에 영향을 미칠 수 있다.
- 인덱스를 지나치게 많이 만들면 오버헤드가 발생한다
- 넓은 범위를 인덱스로 처리하면 많은 오버헤드가 발생한다.
- 인덱스를 만들면 추가적인 저장 공간이 필요하다
- 인덱스와 테이블 데이터의 저장 공간이 분리되도록 설계한다.
26. 파티션의 종류
범위 분할 (Range Partitioning)
- 지정한 열의 값을 기준으로 분할한다
- 예) 일별, 월별, 분기별 등
해시 분할 (Hash Partitioning)
- 해시 함수를 적용한 결과 값에 따라 데이터를 분할한다.
- 특정 파티션에 데이터가 집중되는 범위 분할의 단점을 보완한 것으로, 데이터를 고르게 분산할 때 유용하다
- 특정 데이터가 어디에 있는지 판단할 수 없다.
- 고객번호, 주민번호 등과 같이 데이터가 고른 컬럼에 효과적이다
조합 분할 (Composite Partitioning)
- 조합 분할로 분할한 다음 해시 함수를 적용하여 다시 분할하는 방식이다.
- 범위 분할한 파티션이 너무 커서 관리가 어려울 때 유용하다.
26. E-R 다이어그램

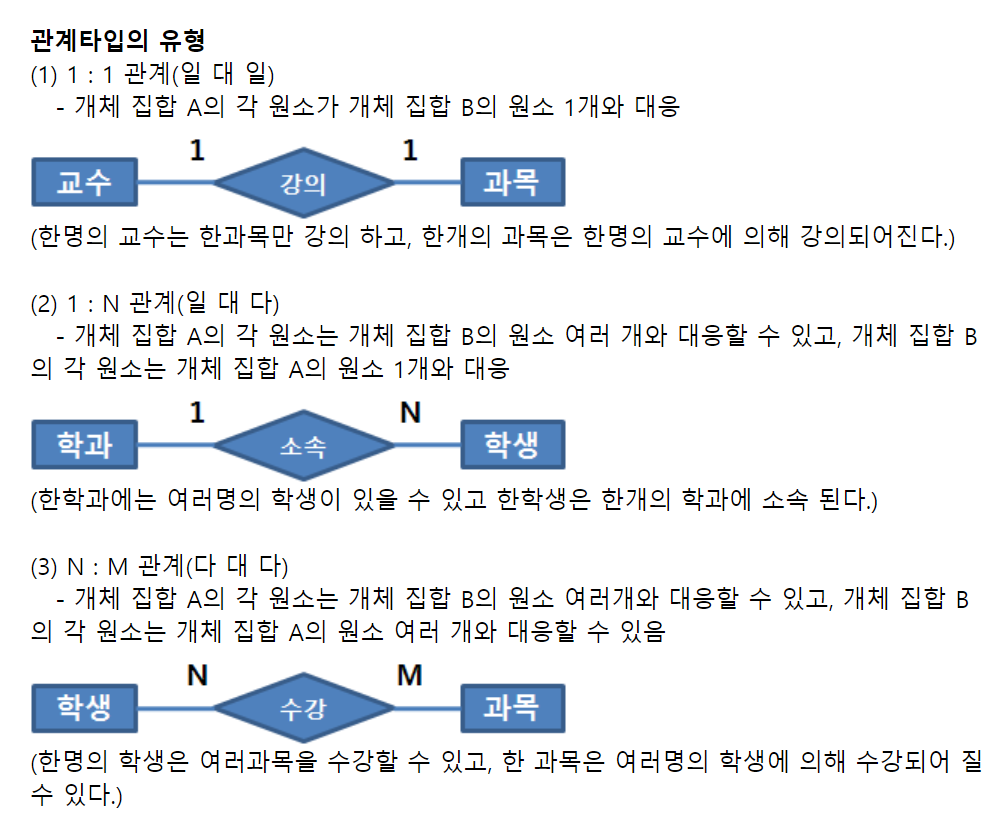
27. DBMS
1. JDBC (Java DataBase Connectivity)
- Java 언어로 다양한 종류의 데이터베이스에 접속하고 SQL문을 수행할 때 사용되는 표준 API
2. ODBC (Open DataBase Connectivity)
- 데이터베이스에 접근하기 위한 표준 개방형 API로, 개발 언어에 관계없이 사용할 수 있음
3. MyBatis
- JDBC 코드를 단순화하여 사용할 수 있는 SQL Mapping 기반 오픈 소스 접속 프레임워크
4. ORM (Object-Relational Mapping)
- 객체지향 프로그래밍의 객체(Object)와 관계형 데이터베이스(Relational Database)의 데이터를 연결(Mapping)하는 기술
28. 데이터 전환
- 운영 중인 기존 정보 시스템에 축적되어 있는 데이터를 추출(Extraction)하여 새로 개발할 정보 시스템에서 운영 가능하도록 변환(Transformation)한 후, 적재(Loading)하는 일련의 과정
- 데이터 전환을 ETL(Extraction, Transformation, Load), 즉 추출, 변환, 적재 과정이라고 한다
- 데이터 전환을 데이터 이행(Data Migration) 또는 데이터 이관이라고도 한다.
- 데이터 전환을 성공적으로 수행하기 위해 데이터 전환이 필요한 대상을 분석하여 데이터 전환 작업에 필요한 모든 계획을 기록하는 데이터 전환 계획서를 작성하고 이를 토대로 진행한다.
데이터 전환 계획서의 주요 항목
데이터 전환 개요
- 데이터 전환 목표, 주요 성공 요인, 전제조건 및 제약조건
데이터 전환 대상 및 범위
데이터 전환 환경 구성
- 원천 시스템 구성도, 목적 시스템 구성도, 전환 단계별 DISK 사용량
데이터 전환 조직 및 역할
- 데이터 전환 조직도, 조직별 역할
데이터 전환 일정
데이터 전환 방안
- 데이터 전환 규칙, 데이터 전환 절차, 데이터 전환 방법, 데이터 전환 설계 등
데이터 정비 방안
- 데이터 정비 대상 및 방법, 데이터 정비 일정 및 조직
비상 계획
- 종합상황실 및 의사소통 체계
데이터 복구 대책
- 백업 및 복구 방안
29. 관계의 종류
종속 관계(Depndent Relationship)
- 두 개체 사이의 주,종 관계를 표현한 것으로, 식별 관계와 비식별 관계가 있음
중복 관계(Rdundant Relationship)
- 두 개체 사이에 2번 이상이 종속 관계가 발생하는 관계임
재귀 관계(Recursivee Relationship)
- 개체가 자기 자신과 관계를 갖는 것으로, 순환 관계(Recursive Relationship)라고도 함
배타 관계(Exclusive Relationship)
- 개체의 속성이나 구분자를 기준으로 개체의 특성을 분할하는 관계로, 배타 AND 관계와 배타 OR 관계로 구분한다
- 배타 AND 관계는 하위 개체들 중 속성이나 구분자 조건에 따라 하나의 개체만을 선택할 수 있고, 배타 OR 관계는 하나 이상의 개체를 선택할 수 있다.
30. 주 식별자
특징
유일성
- 주 식별자에 의해 개체 내에 모든 인스턴스들이 유일하게 구분되어야 함
최소성
- 주 식별자를 구성하는 속성의 수는 유일성을 만족하는 최소 수가 되어야 함
불변성
- 주 식별자가 한 번 특정 개체에 지정되면 그 식별자는 변하지 않아야 함
존재성
- 주 식별자가 지정되면 식별자 속성에 반드시 데이터 값이 존재해야 함
31. 스토리지(Storage)의 종류
DAS(Direct Attached Storage)
- 서버와 저장장치를 전용 케이블로 직접 연결하는 방식
- 일반 가정에서 컴퓨터에 외장하드를 연결하는 것이 여기에 해당됨
NAS(Network Attached Storage)
- 서버와 저장장치를 네트워크를 통해 연결하는 방식
SAN(Storage Area Network)
- DAS의 빠른 처리와 NAS의 파일 공유 장점을 혼합한 방식
- 서버와 저장 장치를 연결하는 전용 네트워크를 별도로 구성하는 방식
32. 클러스터드 인덱스(Clustered Index)
- 인덱스 키의 순서에 따라 데이터가 정렬되어 저장되는 방식
- 실제 데이터가 순서대로 저장되어 있어 인덱스를 검색하지 않아도 원하는 데이터를 빠르게 찾을 수 있다
- 데이터 삽입, 삭제 발생 시 순서를 유지하기 위해 데이터를 재정렬해야 한다
- 한 개의 릴레이션에 하나의 인덱스만 생성할 수 있다.
33. 넌클러스터드 인덱스(Non-Clustered Index)
- 인덱스의 키 값만 정렬되어 있을 뿐 실제 데이터는 정렬되지 않는 방식이다.
- 데이터를 검색하기 위해서는 먼저 인덱스를 검색하여 실제 데이터의 위치를 확인해야 하므로 클러스터드 인덱스에 비해 검색 속도가 떨어진다
- 한 개의 릴레이션에 여러 개의 인덱스를 만들 수 있다.
34. 병행수행의 문제점
갱신 분실(Lost Update)
- 두 개 이상의 트랜잭션이 같은 자료를 공유하여 갱신할 때 갱신 결과의 일부가 없어지는 현상
비완료 의존성(Uncommitted Dependency)
- 하나의 트랜잭션 수행이 실패한 후 회복되기 전에 다른 트랜잭션이 실패한 갱신 결과를 참조하는 현상
모순성(Inconsistency)
- 두 개의 트랜잭션이 병행 수행될 때 원치 않는 자료를 이용함으로써 발생하는 문제
연쇄 복귀(Cascading Rollback)
- 병행수행되던 트랜잭션들 중 어느 하나에 문제가 생겨 Rollback하는 경우 다른 트랜잭션도 함께 Rollback되는 현상
35. SQL
A. 동적 SQL
- 개발 언어에 삽입되는 SQL 코드를 문자열 변수에 넣어 처리하는 것
- 조건에 따라 SQL 구문을 동적으로 변경하여 처리할 수 있다
- 동적 SQL은 사용자로부터 SQL문의 일부 또는 전부를 입력받아 실행할 수 있다
- 동적 SQL은 값이 입력되지 않을 경우 사용하는 NVL 함수를 사용할 필요가 없다
- 동적 SQL은 응용 프로그램 수행 시 SQL이 변형될 수 있으므로 프리컴파일 할 때 구문 분석, 접근 권한 확인 등을 할 수 없다
- 동적 SQL은 정적 SQL에 비해 속도가 느리지만, 상황에 따라 다양한 조건을 첨가하는 등 유연한 개발이 가능하다.
B. 정적 SQL
- SQL 구성 시 커서(Cursor)를 통해 처리한다
Notion
https://www.notion.so/mildsalmon/2-e275981e1f4b4626b23976c9e5ae4d1f