

작성자의 개인적인 추론이 들어가 있어서 틀린 내용일 수 있습니다. "아~ 이렇게도 생각할 수 있구나." 정도로 넘어가 주시면 감사하겠습니다.😂 혹시 틀린 내용이라면, 댓글로 지도해주시면 감사하겠습니다.
모든 내용은 실험적으로 작성되었습니다. 따라서 예상치 못한 반례가 등장하여 위 가설들을 반박할 수 있습니다. 그러니 위와 비슷한 상황이 고민이신 분들은 여러 가지 반례들을 생각해보면서 실험하고 결론을 내리시길 바랍니다.
그냥, 이 글은 제 의견을 길게 풀어쓴 것임을 고려해주시길 바랍니다.
1. 개요
- 코딩테스트를 보던 중 너무 긴장한 나머지 문자열에 비교 연산자를 사용하는 실수를 저질렀다.
- 가끔 멍때리면서 혹은 귀찮아서 문자열을 정수형으로 강제형변환하지 않고 비교했던 적이 있었다.
- 그때는 잘 작동했는데, 코테에서 써먹었다가 엄청난 양의 에러를 마주했다.
- 그래서, 문자열에 비교 연산자를 돌리면 어떻게 될까? 라는 의문을 해결하기 위해 여러가지 실험을 해봤다.
- 이 글은 실험 과정에 대한 기록이다.
2. 문제 발생
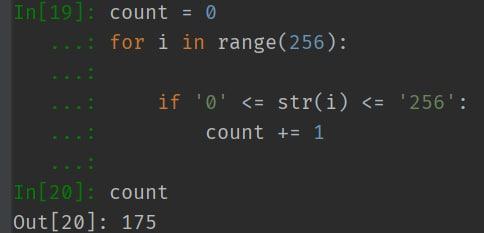
위 사진을 보면 2가지 반응이 예상된다.
- 아니, 문자열에 비교연산자를 돌리는 이유가 뭐야? 그리고 저게 돌아가? 왜?
- 0 이상 256 이하인 문자열이니까, count는 256이 나와야하는거 아니야?
3. 해결 과정
A. 일단 값을 출력해보자.
a. 제안
- count가 어떻게 더해지는지는 모르겠다.
- 그러니, if문에 만족하는 i값을 출력해보자.
b. 결과
0
1
2
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
100
101
102
103
104
105
106
107
...
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
c. 분석
결과를 보면 아래와 같이 분석할 수 있다.
- 한자리 수
- 0, 1, 2까지만 출력된다.
- 3 ~ 9까지는 출력되지 않는다.
- 두자리 수
- 10 ~ 25까지만 출력된다.
- 26 ~ 99까지는 출력되지 않는다.
- 세자리 수
- 100 ~ 255까지만 출력된다.
여기서 문자열을 비교 연산하면 숫자처럼 비교하지 않는것을 유추할 수 있다.
그럼 어떤 기준으로 비교를 진행할까? 아스키코드일까?
B. 아스키 코드를 분석해보자.
a. 제안
- 0부터 9까지는 맵핑되는 아스키 코드가 있는 것을 안다.
- 그럼, 10 이상의 수에 맵핑되는 아스키 코드가 있을까?
- 파이썬에는
ord()함수를 사용하여 인자값을 아스키 코드로 변환할 수 있다.- 파이썬 3.10.0 공식 document에서는 하나의 유니코드 문자를 나타내는 문자열이 주어지면 해당 문자의 유니코드 코드 포인트를 나타내는 정수를 돌려줍니다.[1] 라고 적혀있다.
b. 과정
- 유니코드와 아스키 코드의 차이.
아스키 코드는 7비트(128개)의 고유한 값만 사용한다. 즉, 0 ~ 127에 매핑되는 숫자, 알파벳 대소문자, 특수문자가 있다는 의미이다.
유니코드는 용량을 크게 확장하여 2byte (2의 16승 = 65536)와 매핑되는 문자들을 정의한 것이다.
그러니까,
ord()를 사용하면 아래와 같은 것도 가능하다.In[15]: ord('∮') Out[15]: 8750- ord() 함수에는 인자값으로 문자만 입력할 수 있다.
ord() 함수에 숫자를 집어넣으면 TypeError가 발생한다.
In[16]: ord(1) Traceback (most recent call last): File "C:\python\anaconda3_64\Lib\site-packages\IPython\core\interactiveshell.py", line 3437, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-14-77e5aeef42fb>", line 1, in <module> ord(1) TypeError: ord() expected string of length 1, but int found- 10 이상의 수와 매핑되는 유니코드가 있을까?
우선, 문자
1은 유니코드로 49이다.In[17]: ord('1') Out[17]: 49하지만, 문자 10 은 TypeError가 발생한다.
In[18]: ord('10') Traceback (most recent call last): File "C:\python\anaconda3_64\Lib\site-packages\IPython\core\interactiveshell.py", line 3437, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-18-553c08a2b613>", line 1, in <module> ord('10') TypeError: ord() expected a character, but string of length 2 found
c. 분석
위 결과를 보면, 10 이상의 수(문자)와 매핑되는 유니코드는 없다는 것을 알 수 있다.
그럼, 2 자릿수 이상의 숫자를 문자로 변환하면, 각 자릿수를 유니코드로 변환하여 비교하는걸까? 라는 생각이 들었다.
그런데, 조금만 생각해보면 말이 안된다는 것을 알 수 있다. [3-A] 에서 3이라는 숫자가 출력되지 않았다. 그렇다면, 3이라는 숫자는 256보다 크다는 것을 의미하게 된다. 3이라는 숫자의 유니코드는 51이다. 256의 각 자릿수의 유니코드는 50, 53, 54이다. 어떻게 생각해도 3이라는 숫자가 256보다 크다고 생각할 수 없다.
가만있어보자.. 그럼 문자열의 인덱스를 유니코드로 변환하여 비교해서 이런 결과가 발생하는걸까?
C. 문자열의 인덱스를 비교해보자.
a. 제안
- 숫자를 문자열로 변환하였다. 그리고 문자열에 비교 연산자를 사용하여 문자열의 크고 작음을 판단하였다.
- 가끔 코딩테스트 문제를 풀면, 파이썬에서는 문자열의 대소를 비교를 필요로하는 문제들이 있다.
- 숫자를 문자열로 변환하였으니, 문자열끼리 대소를 비교할 때처럼 비교연산자를 적용하는 게 아닐까?
b. 과정
- 문자열에 비교연산자를 사용했을 때를 생각해보자.
A라는 문자열을 유니코드로 변환하여 비교연산자를 사용한 것이 확실해 보인다.
그럼,
A < AB는 인덱스별로 유니코드로 변환하여 비교연산자를 수행한 것일까? NULL은 값이 없음이니까, A는 A + NULL로, AB는 A + B로 분리하여 비교했다고 생각해야 할까?In[33]: 'A' < 'A' Out[33]: False In[34]: 'A' < 'AB' Out[34]: True In[35]: 'AB' < 'A' Out[35]: False- 본론으로 돌아와서.
위의 추론을 숫자를 문자열로 변환하여 비교연산자를 수행하는 상황에 대입해보자.
문자 25는 256보다 작기 때문에 True가 반환된다. 25는 2 + 5 + NULL이고 256은 2 + 5 + 6이라서 256이 25보다 크다.
그러나, 26은 256보다 크기 때문에 False가 반환된다. 26는 2 + 6 + NULL이고 256은 2 + 5 + 6이라서 256이 26보다 작다.
In[55]: '0' <= '25' <= '256' Out[55]: True In[56]: '0' <= '26' <= '256' Out[56]: False
4. 결론
비교연산자의 피연산자가 문자열이라면, 해당 문자열은 유니코드로 변환하여 같은 인덱스끼리 비교하게 된다.
다만, 2 + 5 + NULL에서 NULL도 엄밀히 따지면, 틀린 표현이다. 그냥 2 + 5로 끝나야 한다. 어차피 세번째 자릿수는 존재하지 않으니, 세번째 자릿수를 비교한다고 해도 존재하지 않는 값은 그 어떤 값보다 클 수 없다.
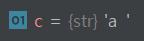
참고로, a + NULL과 a 를 비교한 결과이다. 즉, 위에서는 이해하기 쉽게 NULL이라고 표현했지만, 그냥 없다라고 생각하는게 맞다.
In[68]: c = 'a' + '\0'
In[69]: c
Out[69]: 'a\x00'
In[70]: c < 'a'
Out[70]: False
In[71]: c > 'a'
Out[71]: True
모든 내용은 실험적으로 작성되었습니다. 따라서 예상치 못한 반례가 등장하여 위 가설들을 반박할 수 있습니다. 그러니 위와 비슷한 상황이 고민이신 분들은 여러 가지 반례들을 생각해보면서 실험하고 결론을 내리시길 바랍니다.
그냥, 이 글은 제 의견을 길게 풀어쓴 것임을 고려해주시길 바랍니다.
참고문헌
[1] 내장 함수 — Python 3.10.0 문서. (accessed Oct 27, 2021)