


피쳐(Feature)
- 피쳐(feature) : '특징', 모델에서 주어지는 데이터, 데이터 테이블 상에서 속성에 해당한다.
- y값 : 종속변수 또는 목적변수
- x값 : 독립변수, 피쳐로 종속변수 y에 영향을 줌.
주어진 데이터 x와 알고리즘을 통해 a와 b의 최적값을 찾아, 예측값 y를 구함.
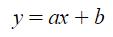

서로 다른 독립변수 13개를 xn으로 하고 가중치 wn을 선형 결합하여 나타냄.
머신러닝에서는 가중치를 의미하는 w를 사용한다.
- 데이터 테이블 : 판다스를 이용한 테이블 형태의 데이터 집합
- 데이터 인스턴스 : 객체에 대한 모든 피쳐를 모아 놓은 데이터 전체, 데이터베이스에서 튜플(tuple)
- 차원의 저주(Curse of Dimensionality) : 차원이 늘어날수록, 피쳐의 개수가 증가할수록 데이터를 표현해야하는 공간이 늘어나 데이터 처리가 어려움. 희박한 벡터로 인해 모델에 대한 정확도를 떨어뜨리거나 데이터 처리 속도와 메모리 공간 문제가 발생
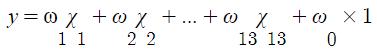
피쳐의 종류
- 연속형 데이터(Continuous Data) : 연속된 값
- 이산형 데이터(Discreate Data) : 연속적인 값이 아닌 분리해서 표현하는 데이터, 라벨로 구분 가능
- 연속형 데이터와 이산형 데이터 차이 : 숫자의 의미가 scale이 있는가 없는가
예시
이산형 데이터 : 만족도 여부 5점 척도, 1점과 2점 간에 스케일이 존재하지 않음
연속형 데이터 : 차량의 속도 20km/40km/60km
이산형 데이터의 분류
- 숫자형 데이터 : 정수나 실수 값으로 정략적으로 측정 가능한 데이터 타입, 단위가 있으면 등간척도형, 데이터와 비율이 있으면 비율척도형
- 명목형 데이터 : 카테고리로 분류가 가능한 데이터 타입, 두 개의 카테고리로 분류되면 이진형 데이터 타입
- 서수형 데이터 : 1학년/2학년/3학년, 소/중/대와 같이 순서가 있는 범주형 데이터 일종의 데이터 타입
데이터를 모델에 적용할 때 고려사항
데이터의 성질이나 존재 하지 않거나 잘못된 데이터들을 고려해서 머신러닝 모델을 만들어야 한다.
연습문제
데이터 과학을 위한 파이썬 머신러닝 2장 연습문제 풀이
참고문헌
최성철, 『데이터 과학을 위한 파이썬 머신러닝』, 초판, 한빛아카데미, 2022