

저희학교에서는 자료구조를 구술로 시험을 쳐서 학점을줍니다.
이런 구술 테스트 중 공부한 내용을 잊지 않기 위해 앞으로는 정리하면서 해볼까합니다.
기록은 기억보다 의미있는걸 믿기 때문입니다.
스택
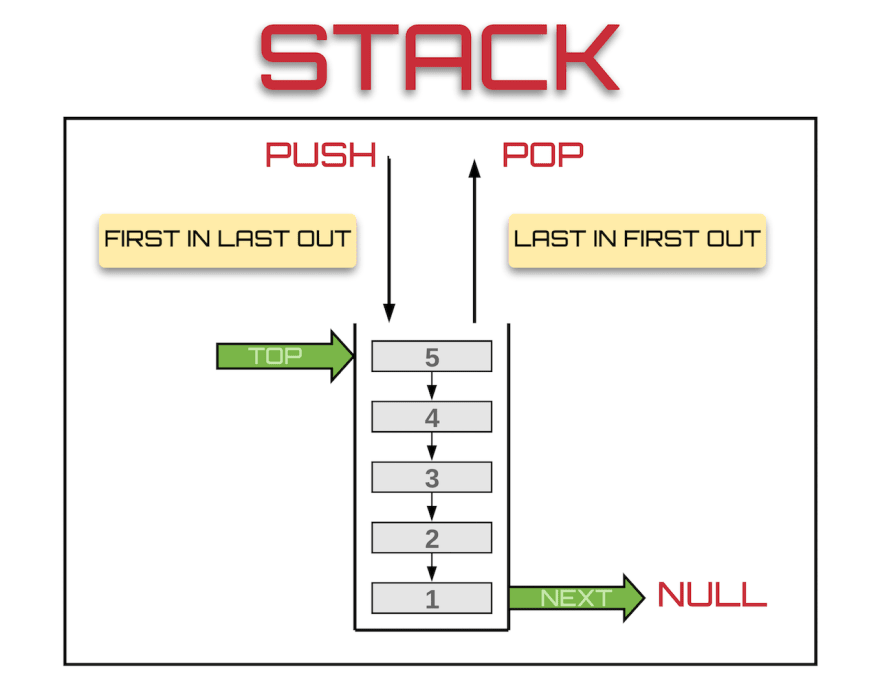
스택은 같은 구조와 크기의 자료를 정해진 방향으로만 입출력 하는 구조입니다.
여기서 정해진 방향이란 top이라 정의된 스택(Stack)의 가장 위 마지막에 삽입한 자료입니다.
 Data Structure in
Data Structure in
https://dev.to/theoutlander/implementing-the-stack-data-structure-in-javascript-4164
위 사진와 같이 스택의 제일 위 마지막 자료를 top이라 정의하며, 스택은 이 top을 통해서만 데이터를 입출력력 합니다. 여기서 가장 중요한 점은 저장이 물리적으로 이루어지는게 아니라는 점입니다.
스택은 선형자료구조의 한쪽 끝(stack)에서만 발생하며 논리적인 구조를 통해 이를 수행합니다.
당연히 Top을 통해서만 입출력이 이루어지기 때문에 우리가 알고있는 LIFO(Last-In-First-Out) 후입선출이라는 특징을 가지게 되죠.
후입선출이라고 어렵게 말하면 잘 이해가 되지 않을텐데, 과거 연탄을 보관할 때를 생각해보면됩니다.
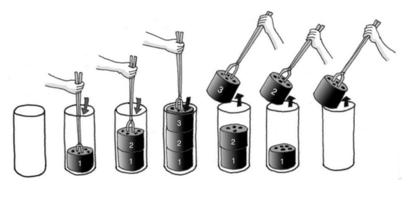
결국 제일 처음 넣은 연탄은 마지막에 사용하게되죠. 왜냐면 위에서만 꺼낼 수 있기 때문입니다. 이처럼 스택은 top을 통해서만 입출력을 진행하게됩니다.
스택의 원소 삽입, 삭제 과정
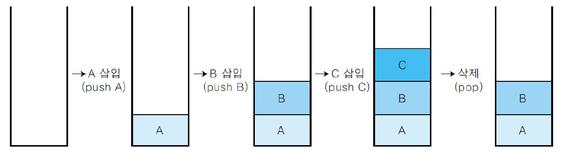
스택의 삽입과 삭제를 나타낸 그림입니다.
스택의 추상 자료형
ADT Stack
Data: 0개 이상의 원소를 가진 유한 선형자료구조
연산 :
S ∈ Stack; item ∈ Element;
createStack(S) ::= 공백 스택 S를 생성하는 연산
push(S, item) ::= 스택 S의 top에 원소(item)를 삽입하는 연산
isEmpty(S) ::= 스택 S가 공백인지를 확인하는 연산
pop(S) ::= 스택 S의 top에 있는 원소를 스택 S 에서 삭제하고 반환하는 연산
delete(S) ::= 스택 S의 top에 있는 원소를 삭제하는 연산
peek(S) ::= 스택 S의 top에 있는 원소를 반환하는 연산
End Stack
By 한빛아카데미(주)
스택은 위와같은 추상 자료형을 가집니다.
중요한점은 push와 pop이 정의되어야한다는 점과 선형자료구조 형태라는 것입니다
스택의 push 알고리즘
push(S,x)
top <- top + 1
if (top stack_SIZE) then
overflow;
else
s(top) <- x;
end push()
스택도 결국 메인메모리에서 구현됩니다. 그리고 메모리의 용량은 한정되어있죠.
스택에서도 용량이 가득차면 오류가 발생하겠죠. 이 오류를 overflow(오버플로우)라고합니다.
스택의 push 알고리즘에서는 먼저 스택의 위치를 한번 증가시켜 스택의 사이즈를 넘었는지, 오버플로가 일어 났는지를 확인해야됩니다. 만약 넘지않았다면 스택에 저장하면 될일이지만, 넘었다면 저장할 곳이 없다는 것을 알려주는 것입니다.
나중에 실제 고급언어로 구현된 스택도 작성해볼 생각이지만 오늘은 개념적으로 정의하는 스택이라는 테마기에 의사코드로 구현하였습니다.
스택의 pop 알고리즘
pop(S)
if(top=-1) then underflow;
else {
return S(top);
top <- top-1;
}
end pop()
pop 연산은 top의 원소를 삭제하고 반환하는 연산입니다.
이런 삭제연산에서 중요 논점은 값이 -로 가게되는 시점입니다.
컴퓨터는 -를 표현하지 못하죠. 저희는 컴퓨터의 -를 표현하기위해 보수법과 같은 기술을 이용합니다.
하지만 스택은 앞에도 언급했듯 논리적인 구조입니다. 그런 스택이 -값을 가지게 되는건 비이상적인 값입니다.
저희는 비이상적인 결과값을 '에러'라고 부르곤하죠.
스택이 0이 아닌 -1이 되는시점. 이 시점을 에러 언더플로로 지정하고 그런 경우에 분기하는 것이 pop 알고리즘의 핵심입니다. delete와 조금 다른 점은 return을 통해 값을 반환하는 것이죠.
스택의 구현
스택은 선형자료구조에서 이용가능한 논리적 구조입니다.
그럼 대표적인 선형자료구조인 순차자료구조(array)와 연결자료구조(linked list)에서도 실제 구현이 가능하겠죠?
순차자료구조를 이용한 스택의 구현
이부분에서는 순차자료구조인 1차원배열(array)를 이용하여 구현한 예를 보여드리겠습니다.
배열은 순차적인 자료구조입니다. 주요 특징은 물리적인구조와 논리적 구조가 같다는 것이있습니다.
이런 배열에서 스택의 크기는 배열의 크기와 같습니다. 논리적인구조(스택)과 물리적인구조(배열)이 같기 때문이죠.
스택에 저장된 원소의 순서는 순차적일 것입니다. 순차자료구조이기 때문에 스택의 원소들은 순서에따라 저장되어있을 것입니다. 여기서 순서는 top을 통해 스택에 저장된 순서겠죠.
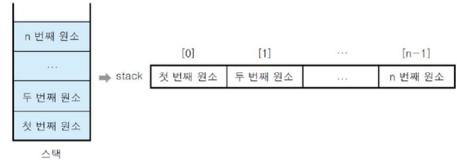
스택, 배열의 첫번째 원소는 0이죠. 그럼 top의 첫번째 요소(값)은 몇일까요? 스택에 아무것도 없다는 가정하에 top = -1입니다. 왜냐면 첫번 째 값이 들어왔을 때 top=0이 되어 값을 가르켜야 되기 때문이죠. 이와 같은 개념으로 스택이 포화상태일 때 값도 n-1입니다. n개의 원소만큼 스택이 증가했기 때문이죠.
순차 자료구조로 구현한 자료구조는 1차원 배열이라는 매우 간단한 구조를 사용해 쉽게 구현할 수 있다는 장점이있습니다. 하지만 배열의 고질적 문제인 물리적으로 고정된 크기로 이니해 스택 크기 변경에 어려움이있고, 고정된 크기 내에서 표현하고 이 크기는 먼저 동적할당되어있기 때문에, 빈 공간의 메모리가 낭비된다는 단점도 있습니다.
연결 자료구조를 이용한 스택의 구현
연결자료구조, Linked List는 노드와 주소값을 통해 배열보다는 자유로운 크기를 가지고있죠.
여기서는 다양한 연결자료구조 중에서 단순연결리스트를 통해 구현해보겠습니다.
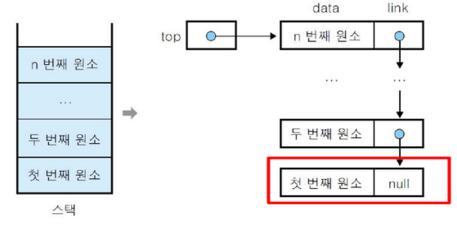
단순 연결리스트 노드와 링크포인터로 이루어져있고,
링크포인터를 통해 다음 원소의 주소를 가르켜 연결됩니다. 마지막 주소에서는 null값이 링크포인터로 들어가게되죠.
스택을 구현하는 단순연결리스트는 첫번 째 주소에서 null값을 가집니다.
그 이유는 스택은 top을 통해 제어되어야 하기 때문이죠.
top은 사진처럼 n번째 요소를 가르키고 이 요소들은 주소를 통해 계쏙 연결되고 마지막에 이르러 첫 번째 원소에서 null을 가르킵니다.
만약 스택에 원소가 한개라면 Top -> 첫번째원소/null이 연결자료구조로 구현된스택의 모습이겠죠.
그리고 두번째 원소가 생긴다면 top은 두번째 원소를 가르키는 것입니다. 스택은 후입선출의 구조를 지녔기에 제일 마지막 원소를 탑이 가르켜야되기때문입니다.
스택의 응용
스택의 후입선출 특징은 다양한 분야에서 응용이 가능합니다.
역순 문자열 만들기
흔히 프로그램 언어에서는 reverse 같은 이름으로 역순 문자열 출력을 지원합니다.
string a = "ABCD"일 때, 이것을 리버스하면 "DCBA"입니다.
보통 이런 역순문자열 출력은 스택에 의해 구현됩니다.
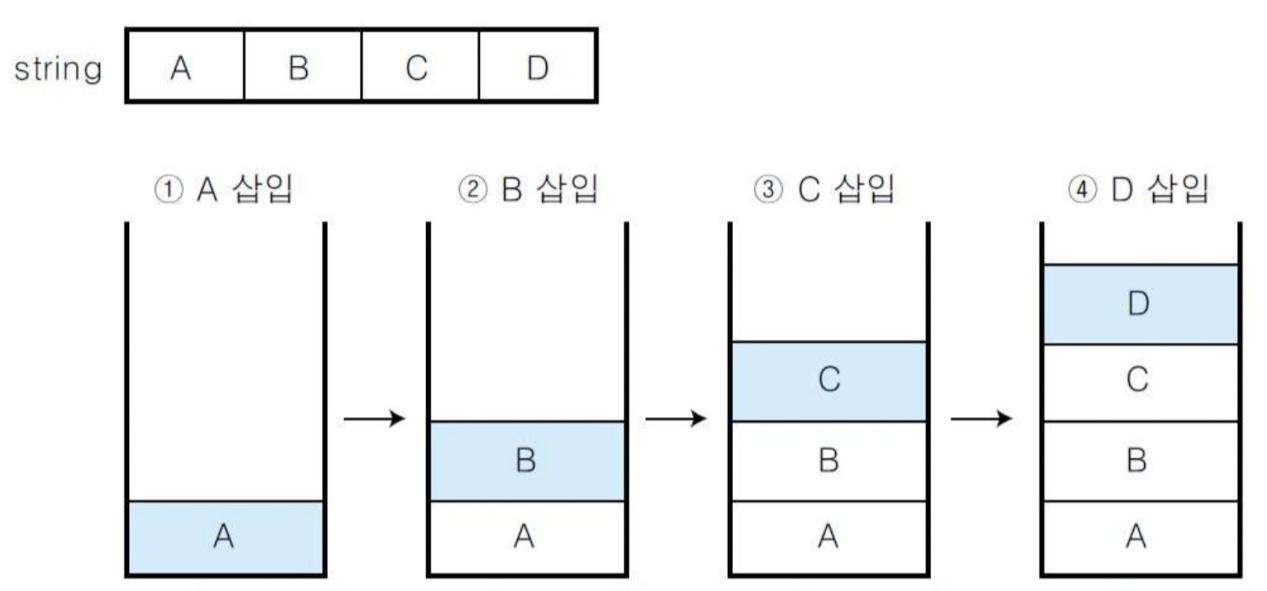
위의 예시처럼 스택에 ABCD를 차례대로 push하면 위와같이 스택에 적제되고 이대로 문자열을 pop하면 DCBA로 출력할 수 있다.
시스템 스택
우리가 만든 프로그램을 실행할 때 주로 함수를 호출합니다. 그런데 호출된 함수는 일련의 과정을 수행하고 다시 return을 실행하죠. 시스템 스택은 이런 함수의 흐름을 제어하는 스택의 일종입니다.
함수의 호출(Jump 명령)이 발생하면 시스템은 함수 수행에 필요한 지역변수, 매개변수, 수행 후 복귀할 주소 등의 정보를 스택프레임(Stack frame)에 저장하여 시스템 스택에 push합니다.
그리고 해당 함수가 종료되면 시스템 스택의 top원소(스택 프레임)를 pop하면서 복귀주소를 얻어 다시 함수가 실행되던 어느 지점으로 돌아갑니다.
C언어로 보는 시스템 스택의 흐름
C언어로 간단하게 설명해보자면.
#include <stdio.h>
int main(void) {
printf("hello world");
return 0;
}
시스템 스택의 개념을 위에 적힌 C프로그램을 따라가며 설명해보겠습니다. 먼저 #include <stdio.h>는 stdio.h라는 헤더파일을 그대로 복사해서 해당 소스파일에 붙여넣겠다는 명령입니다. 여기서 stdio.h는 printf를 위해 정의되었습니다.
그리고 main함수를 만나게 되는데 메인함수를 만나는 시점에서 시스템 스택은 stack_frame을 만들게됩니다.
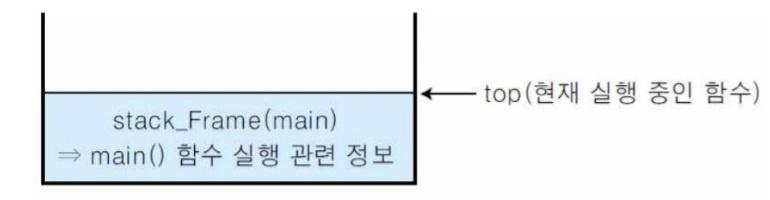
이 스택프레임은 main함수에 정보를 담고있습니다. 그중 가장 중요한 정보는 메인함수의 주소겠죠. 그리고 printf를 만나게되면서 printf의 주소가 위의 사진처럼 스택프레임의 형태로 push됩니다.. 당연히 top은 pirntf의 스택프레임을 가르키겠죠. 그리고 printf의 어느시점에서 return(혹은 어셈블리 복귀명령) 명령이 발생할 껍니다. 그 시점에 stack의 top이 가르키는 printf 스택 프레임은 pop됩니다. 마지막으로 return 0코드를 만나며 main의 스택프레임도 pop되며 시스템 스택은 공백스택이 되는 것이죠.
수식의 괄호검사
파이썬을 제외한 대부분의 프로그램 언어들은 괄호를 사랑합니다.
"[], {}, ()"와 같은 괄호들은 고급언어에서 언제나 등장하곤합니다.
가장 대표적인 예가 if(조건문) { 실행문 } 입니다.
그런데 이런 괄호들을 프로그램들은 어떻게 인식하는걸까요. 이 또한 스택과 관련있습니다.
수식괄호검사가 실행되면 왼쪽괄호 "{"를 만나게되면 스택에 push 오른쪽 괄호 "}"를 만나게되면 pop하여 마지막 괄호와 종류가 같은지를 확인합니다. 마약 pop받은 괄호가 마지막 괄호와 다르면 에러겠죠? 바로 이 방식이 IDE가 우리에게 괄호에러를 알려주는 방식입니다. 자세한건 실제 코드와 함께 다음에 다뤄보도록하겠습니다.
수식의 후위 표기법 변환
정보처리 기사 등을 치게되면 배우는 중위표기식, 전위표기식, 후위표기식은 실제 논리적 수식들을
컴퓨터가 이해하게 바꾸는 방식이죠. 이 또한 스택을 이용합니다. 변환방법은 아래와 같습니다.
중위표기식을 후위 표기식으로 변환
- 왼쪽 괄호를 만나면 무시고 다음 문자를 읽는다
- 피연산자를 만나면 출력한다.
- 연산자를 만나면 스택에 push한다.
- 오른쪽 괄호를 만나면 pop하여 출력한다.
- 수식이 끝나면 스택이 공백이 될 때까지 pop하여 출력한다.
이를 이용해 연산을 할 수 도있지만 이에 대한건 다음에 후위표기식에 대해 자세히 다룰 기회가 있으면 언급하도록 하겠습니다.
미로탐색문제
지금까지 스택에 대해 알아봤습니다. 그런데 이 스택을 배우는 이유는 현실적으로 알고리즘 문제들을 풀기 위해서도 있습니다. 대표적인 알고리즘 문제 중 하나인 미로탐색문제(백 트레킹 알고리즘)은 스택을 이용하는 대표적인 알고리즘입니다. 자세한건 백준 문제풀이를 공부할 때 실제 미로탐색 문제를 만나면 다루겠지만
현재 위치에서 가능한 방향을 스택에 저장했다가 막다른 길을 만나면 스택에서 다음 위치를 꺼내 반복하는 것이 핵심이라 할 수 있습니다.
이처럼 스택은 매우 다양한 분야에서 사용됩니다. 오늘 글을 적으면서 저 자신도 스택에 대해 복습할 수 있었고,
이 글을 미래에 다시 보게된다면 시험에 대한 추억과 함께 스택을 공부할 수 있겠죠. 기록은 기억보다 의미있습니다. 제 기록이 언젠가 타인에게도 도움이 되길. 제가 제일 좋아하는 스티브잡스의 구절로 마무리 하겠습니다.
Stay hungry Stay foolish -Steve Jobs