

Apache Iceberg 완벽 가이드: 2장 - 아파치 아이스버그 아키텍처
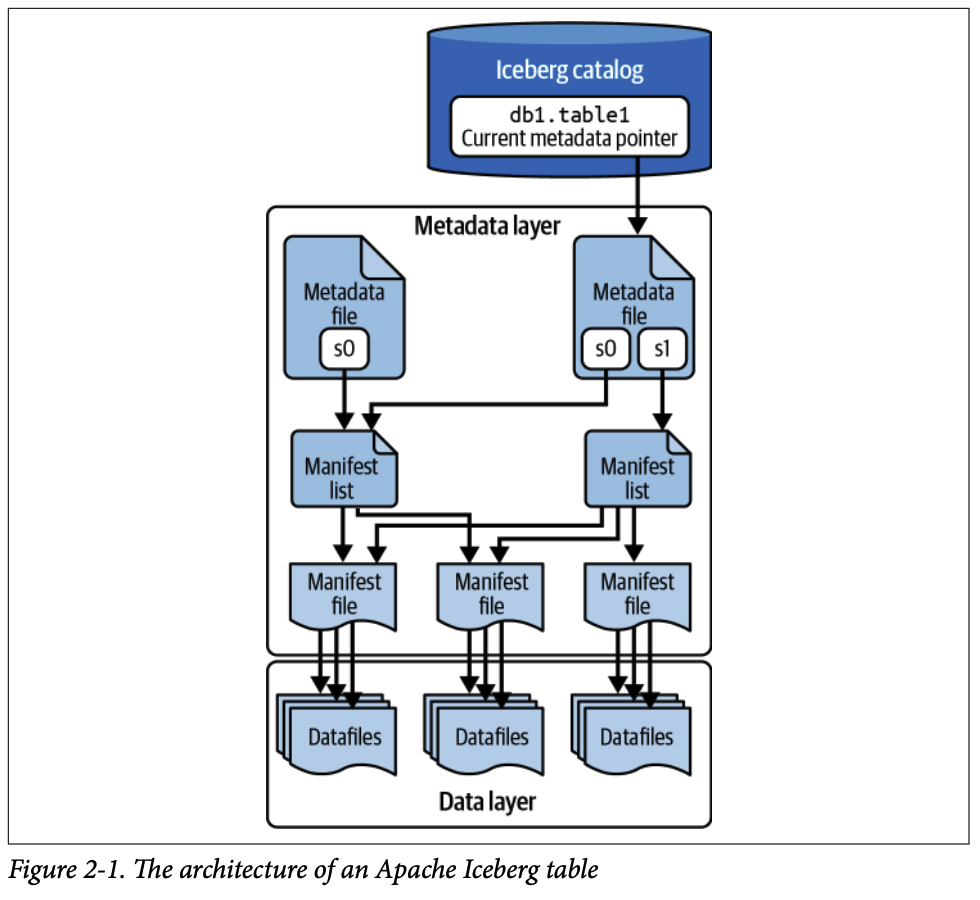
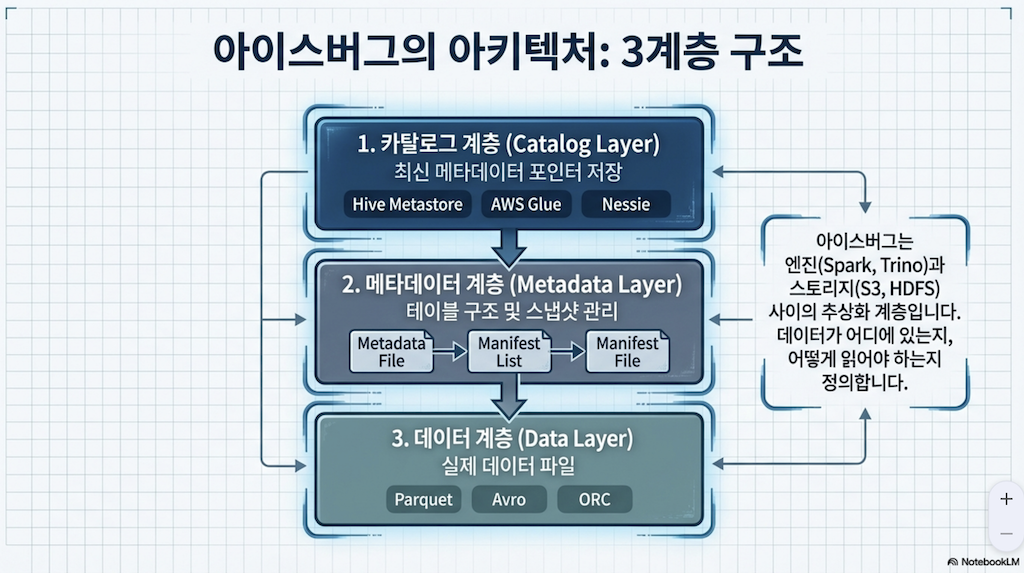
이 장에서는 아파치 아이스버그 테이블의 아키텍처와 사양에 대해 심층적으로 다루며, 하이브(Hive) 테이블 형식의 내재된 문제들을 어떻게 해결하는지 설명합니다. 아이스버그 테이블은 세 가지 계층으로 구성됩니다: 카탈로그 계층, 메타데이터 계층, 그리고 데이터 계층입니다.
1. 데이터 계층 (The Data Layer)
아파치 아이스버그 테이블의 데이터 계층은 실제 데이터를 저장하는 곳이며, 주로 데이터 파일(datafiles)과 삭제 파일(delete files)로 구성됩니다. 이 계층은 사용자 쿼리에 필요한 데이터를 제공하며, 아이스버그 테이블 트리 구조의 리프(leaves)를 이룹니다.
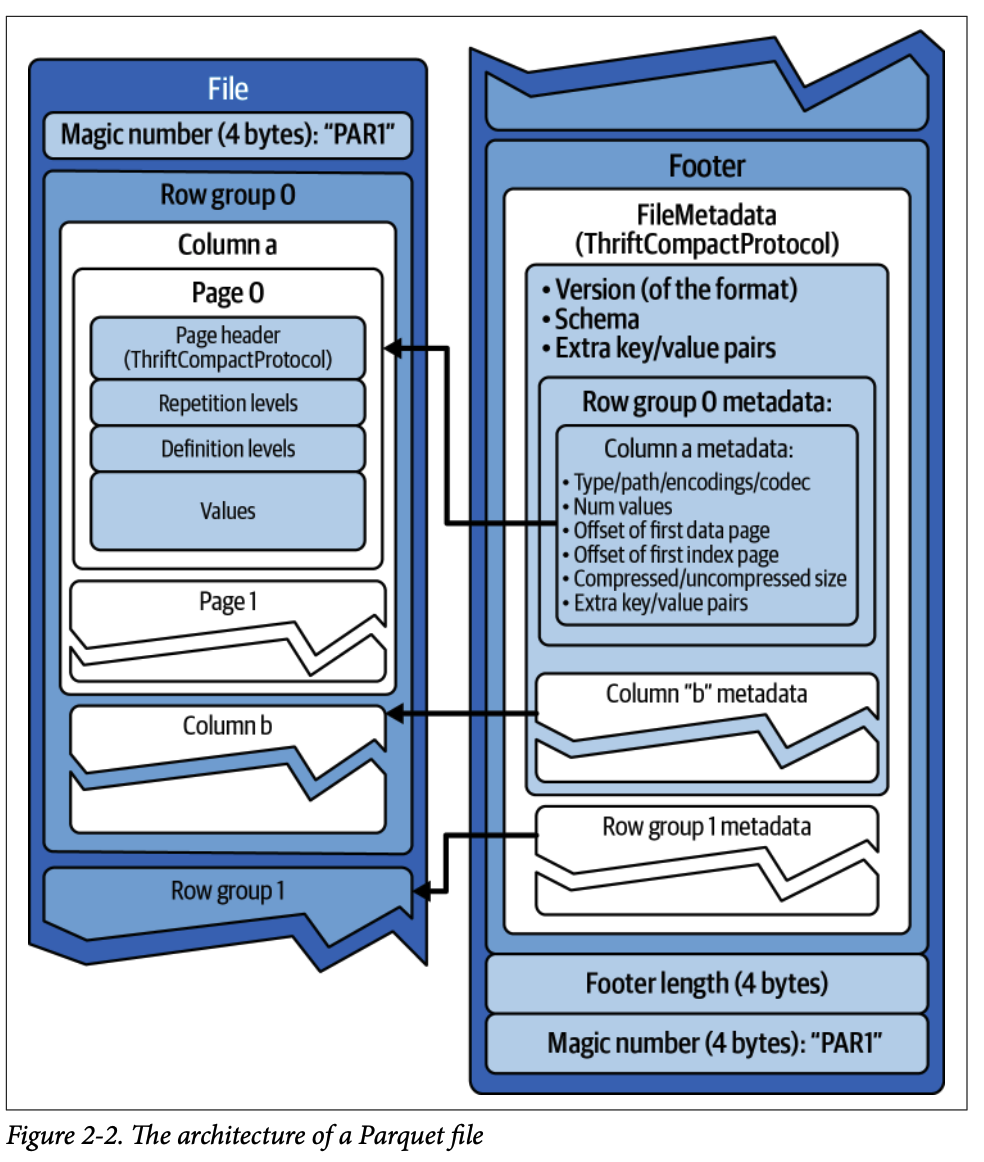
1.1. 데이터 파일 (Datafiles)
주요 포맷:
Apache Parquet, Apache ORC
특징:
데이터는 컬럼 지향(columnar)으로 저장되어 대량의 레코드를 처리하는 쿼리에 효율적입니다.
각 파일은 여러 로우 그룹(row groups)을 가질 수 있으며, 각 로우 그룹은 컬럼별로 페이지(pages)로 나뉘어 저장됩니다.
파일 내 통계 정보(예: 컬럼별 최소/최대 값)를 저장하여 쿼리 엔진이 불필요한 로우 그룹을 건너뛸 수 있도록 돕습니다.
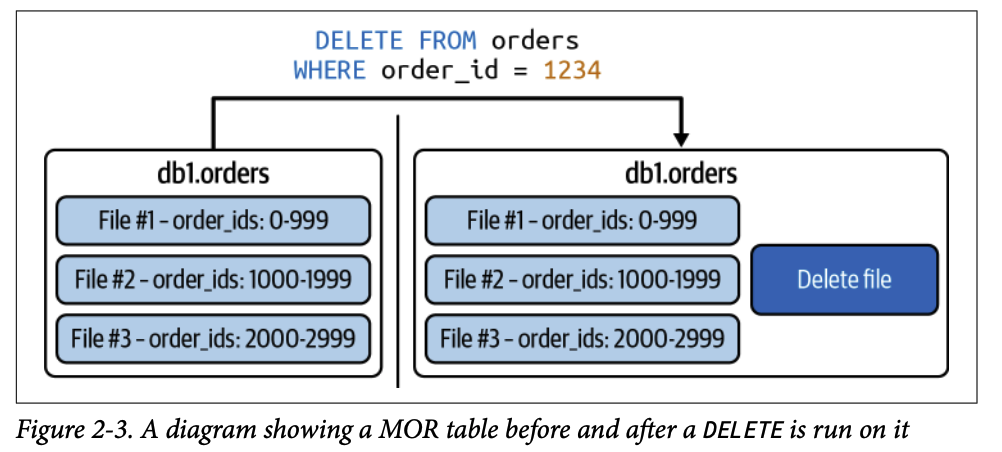
1.2. 삭제 파일 (Delete Files)
주요 역할:
데이터셋에서 논리적으로 삭제된 레코드를 추적합니다.
데이터 레이크 저장소의 불변성(immutability) 원칙을 유지하기 위해, 파일을 직접 업데이트하는 대신 새로운 파일을 작성하는 방식(Copy-on-Write, Merge-on-Read)을 사용합니다.
Merge-on-Read (MOR) 전략을 사용하여 업데이트 및 삭제 작업을 수행할 때 사용됩니다. (Iceberg v2 형식에서만 지원됩니다).
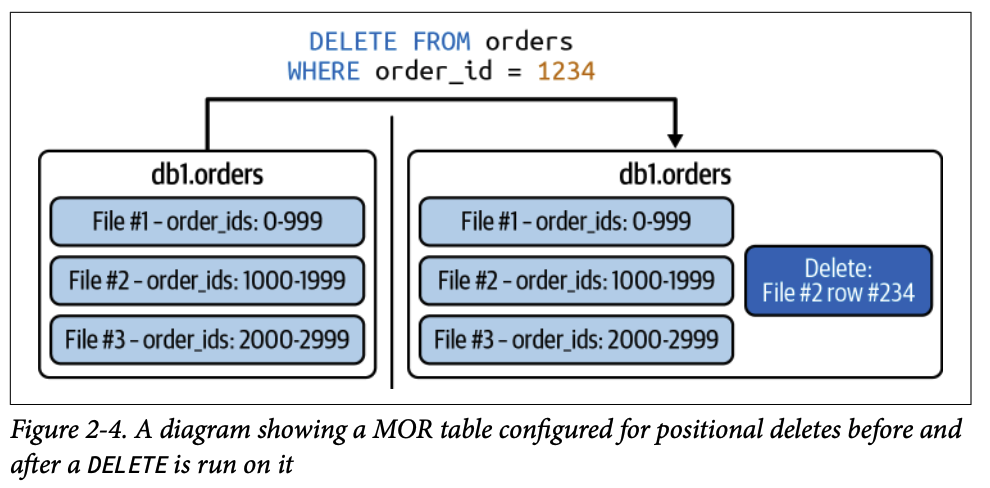
1.2.1. 위치 삭제 파일 (Positional Delete Files)
레코드의 정확한 위치(파일 경로 및 파일 내 레코드 번호)를 식별하여 삭제합니다.
특징:
읽기 시 비용이 적습니다.
쓰기 시 삭제 레코드의 위치를 파악하기 위해 파일을 읽어야 하는 비용이 발생합니다.
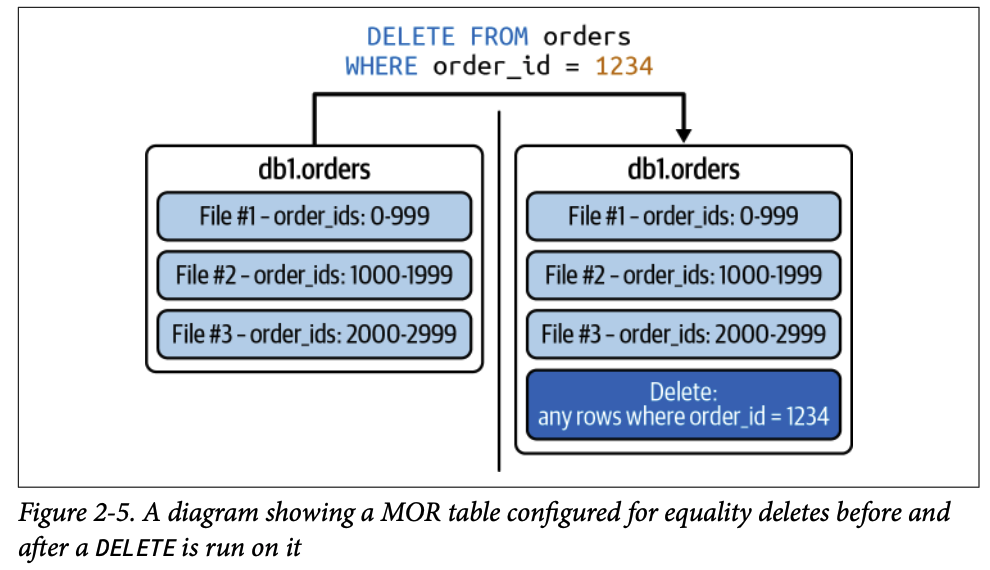
1.2.2. 등가 삭제 파일 (Equality Delete Files)
레코드의 하나 이상의 필드 값으로 레코드를 식별하여 삭제합니다.
특징:
일반적으로 고유 식별자(기본 키)가 있는 경우에 적합합니다.
쓰기 시 비용이 없습니다.
읽기 시 모든 레코드를 비교해야 하므로 읽기 시 비용이 더 큽니다.
1.2.3. 시퀀스 번호 활용
삭제 파일이 적용될 때 시퀀스 번호(sequence numbers)를 사용하여 새로 추가된 레코드가 삭제 목록에 잘못 포함되지 않도록 보장합니다.
2. 메타데이터 계층 (The Metadata Layer)
메타데이터 계층은 아이스버그 테이블 아키텍처의 필수적인 부분으로, 테이블의 데이터 파일 및 관련 작업에 대한 모든 메타데이터 파일을 포함하는 트리 구조입니다. 이 계층은 대규모 데이터셋을 효율적으로 관리하고 시간 여행(time travel) 및 스키마 진화(schema evolution)와 같은 핵심 기능을 가능하게 합니다.
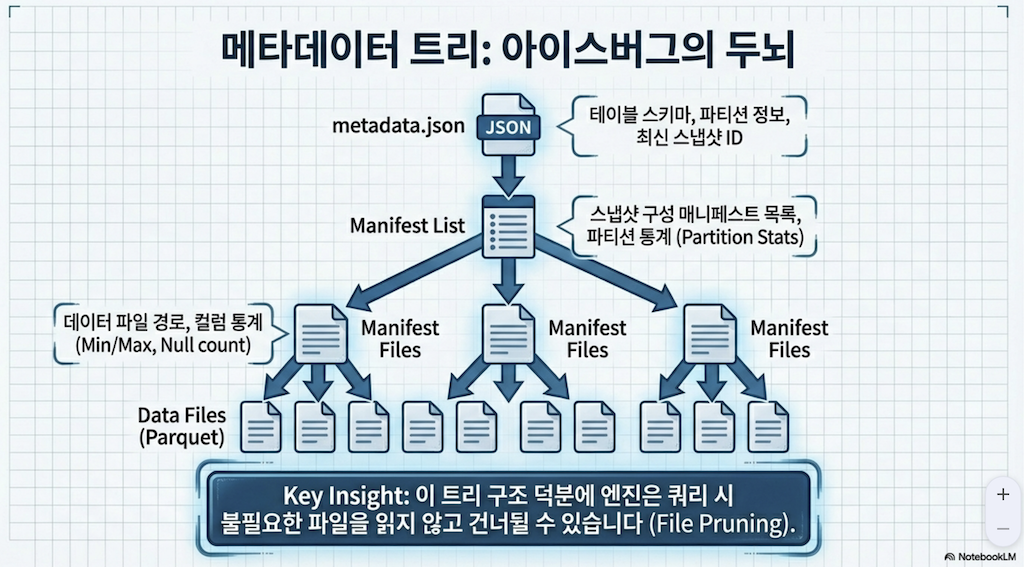
2.1. 매니페스트 파일 (Manifest Files)
주요 역할:
데이터 계층의 파일(데이터 파일 및 삭제 파일)과 각 파일에 대한 추가 세부 정보 및 통계(예: 컬럼의 최소/최대 값)를 추적합니다.
각 파일이 기록될 때 통계가 수집되므로, 하이브(Hive)와 달리 경량화된 통계 수집이 가능하며 쿼리 성능에 더 나은 최신 정보를 제공합니다.
매니페스트 파일은 Avro 형식으로 작성됩니다.
2.2. 매니페스트 목록 (Manifest Lists)
주요 역할:
특정 시점의 아이스버그 테이블의 스냅샷(snapshot)입니다.
해당 시점의 테이블에 대한 모든 매니페스트 파일 목록과 파티션 컬럼의 상한 및 하한과 같은 매니페스트에 대한 통계를 포함합니다.
매니페스트 목록은 Avro 형식으로 작성됩니다.
2.3. 메타데이터 파일 (Metadata Files)
주요 역할:
특정 시점의 아이스버그 테이블에 대한 메타데이터를 저장합니다.
여기에는 테이블의 스키마, 파티션 정보, 스냅샷, 그리고 현재 스냅샷이 무엇인지에 대한 정보가 포함됩니다.
핵심 특징:
아이스버그 테이블에 변경이 있을 때마다 새로운 메타데이터 파일이 생성되고 원자적으로 최신 버전으로 등록됩니다.
이는 테이블 커밋의 선형 기록(linear history)을 보장하고 동시 쓰기(concurrent writes) 시나리오를 지원합니다.
쿼리 엔진은 항상 테이블의 최신 버전을 볼 수 있습니다.
2.4. 퍼핀 파일 (Puffin Files)
주요 역할:
데이터 파일 및 메타데이터 파일에 저장된 통계보다 더 고급 구조를 저장하여 특정 유형의 쿼리 성능을 향상시키는 데 사용됩니다.
구조:
파일에는 임의의 바이트 시퀀스인 블롭(blobs) 세트와 블롭을 분석하는 데 필요한 관련 메타데이터가 포함됩니다.
현재 지원:
현재 Apache DataSketches 라이브러리의 Theta 스케치만 지원하며, 이를 통해 컬럼의 근사 고유값 수를 계산하여 자원을 적게 사용하고 빠르게 연산할 수 있습니다.
3. 카탈로그 계층 (The Catalog)
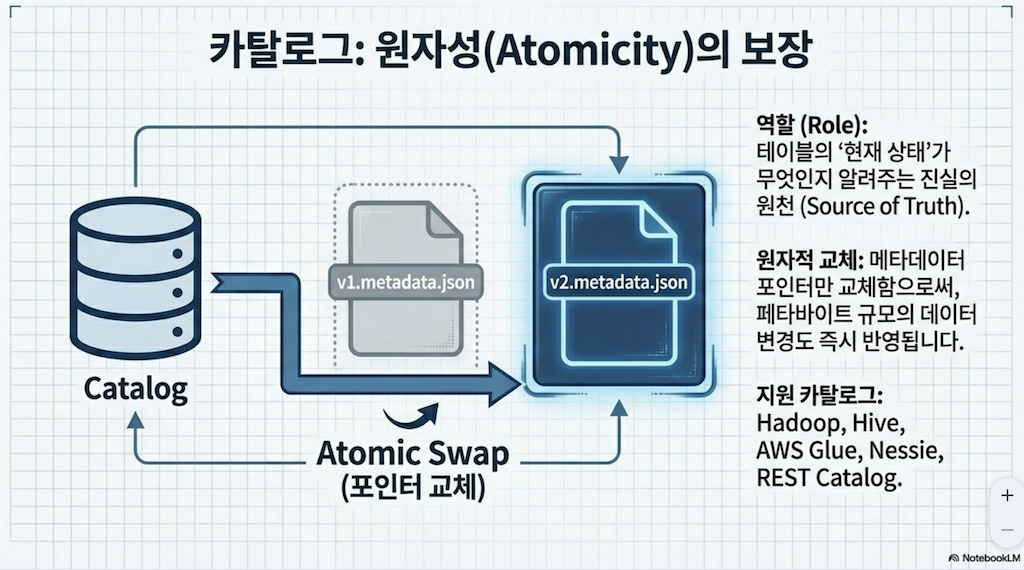
카탈로그는 아이스버그에서 테이블의 최신 메타데이터 파일 위치를 추적하는 중앙 위치입니다. 이는 여러 사용자와 도구가 데이터에 효율적으로 상호 작용할 수 있도록 테이블에 대한 추상화(abstraction)를 제공하는 데 중요한 역할을 합니다.
3.1. 주요 역할
쿼리 엔진이 테이블의 현재 상태를 알기 위해 가장 먼저 상호 작용하는 구성 요소입니다.
3.2. 핵심 요구 사항
현재 메타데이터 포인터를 업데이트하기 위한 원자적(atomic) 작업을 지원해야 합니다. 이는 모든 읽기 및 쓰기 작업이 특정 시점에 테이블의 동일한 상태를 보도록 보장하기 위함입니다.
3.3. 다양한 백엔드 지원
Hadoop 카탈로그(예: Amazon S3), Hive Metastore, AWS Glue, Project Nessie, REST, JDBC 등 다양한 시스템이 아이스버그 카탈로그로 사용될 수 있습니다.
3.4. 저장 방식 차이
각 카탈로그 구현은 현재 메타데이터 포인터를 다르게 저장합니다.
예시:
파일 시스템 기반 카탈로그:
version-hint.txt파일에 현재 메타데이터 파일의 버전 번호를 저장Hive Metastore: 테이블 속성
location에 현재 메타데이터 파일의 위치를 저장
아파치 아이스버그 아키텍처의 이러한 계층과 구성 요소는 하이브 테이블 형식의 문제점을 해결하고 데이터 레이크에서 ACID 트랜잭션, 시간 여행, 스키마 진화와 같은 고급 기능을 제공할 수 있게 합니다.
99. 참고문헌
https://www.oreilly.com/library/view/apache-iceberg-the/9781098148614/