

Apache Iceberg 완벽 가이드: 1장 - 아파치 아이스버그 소개
이 장은 데이터 레이크하우스의 역사적 맥락과 아파치 아이스버그의 핵심 개념을 탐구합니다.
1. 데이터 아키텍처의 발전 과정
1.1. 전통적인 관계형 데이터베이스 관리 시스템 (RDBMS)
관계형 데이터베이스 관리 시스템(RDBMS)은 오랫동안 트랜잭션 데이터 기록을 위한 표준 옵션이었습니다. 예를 들어, PostgreSQL, MySQL, Microsoft SQL Server는 온라인 트랜잭션 처리(OLTP) 워크로드에 최적화되어 있습니다.
이러한 시스템은 한 번에 하나 또는 소수의 데이터 행과 매우 빠르게 상호 작용하도록 설계 및 최적화되어 비즈니스의 일상적인 운영을 지원하는 데 적합합니다. 하지만 데이터 양이 충분히 커지면 대규모 분석 쿼리(OLAP)를 수행할 때 상당한 성능 문제가 발생할 수 있습니다.
1.2. OLAP Workloads
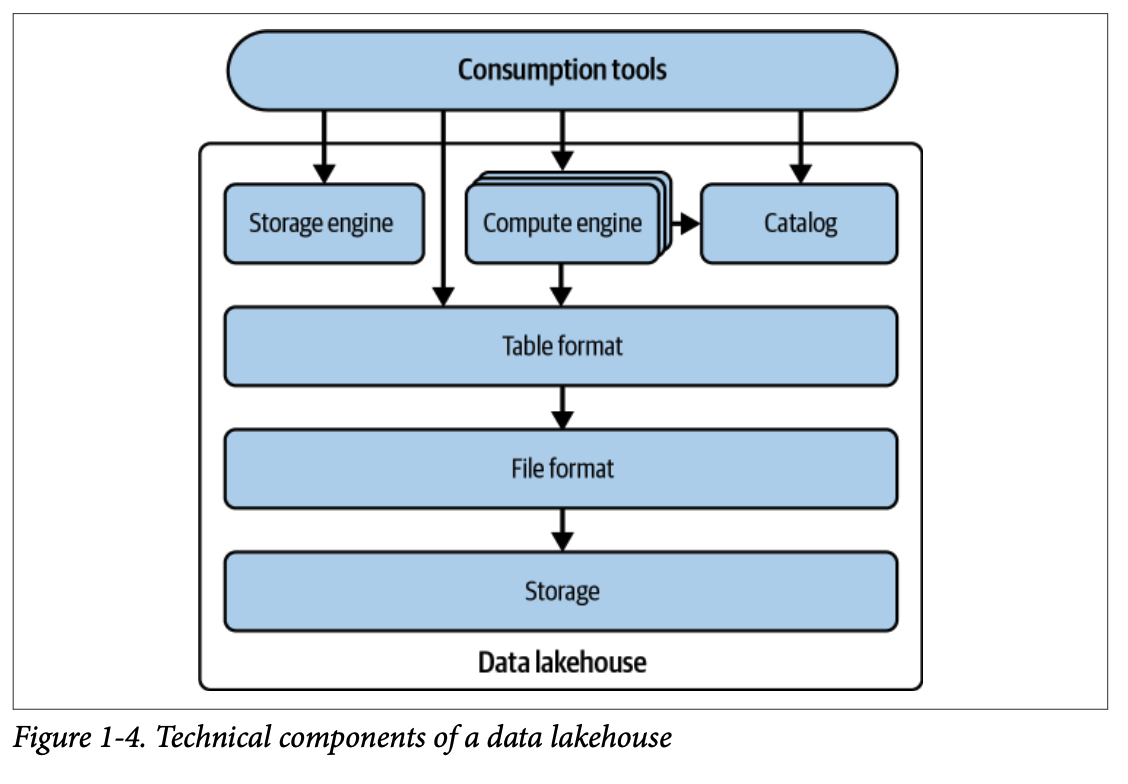
현대적인 분석(OLAP) 워크로드를 지원하기 위해 설계된 시스템은 크게 6가지 핵심 기술 구성 요소로 이루어져 있습니다. 각 요소의 역할과 특징은 다음과 같습니다.
1.2.1. 저장소 (Storage)
대규모 데이터를 저장하기 위한 물리적 계층입니다. 로컬 파일 시스템(DAS), 분산 파일 시스템(HDFS), 또는 클라우드 제공업체의 객체 저장소(Amazon S3 등)가 포함됩니다. 최근에는 방대한 데이터를 다룰 때 효율적인 컬럼 지향(Columnar) 방식이 많이 채택되고 있습니다.
1.2.2. 파일 포맷 (File Format)
로우 데이터가 파일 내에 조직되는 방식으로, 압축 방식과 성능에 영향을 미칩니다. CSV, Avro와 같은 행 지향(Row-oriented) 포맷은 적은 수의 레코드 처리에 유리하며, Parquet, ORC와 같은 열 지향(Column-oriented) 포맷은 대규모 데이터 집계 처리에 더 적합합니다.
1.2.3. 테이블 포맷 (Table Format)
파일 포맷 위의 메타데이터 계층으로, 수많은 데이터 파일을 하나의 통합된 '테이블'로 인식하게 만듭니다. 물리적 데이터 구조의 복잡성을 추상화하여 DML 작업(삽입, 수정, 삭제)과 스키마 변경을 용이하게 하며, 데이터 작업에 대한 원자성과 일관성을 보장합니다.
1.2.4. 스토리지 엔진 (Storage Engine)
테이블 포맷이 지정한 형태대로 데이터를 실제로 배치하고, 파일 및 데이터 구조를 최신 상태로 유지하는 시스템입니다. 데이터의 물리적 최적화, 인덱스 유지 관리, 불필요한 오래된 데이터를 정리하는 핵심 작업을 수행합니다.
1.2.5. 카탈로그 (Catalog)
메타데이터를 활용하여 필요한 데이터셋을 빠르게 찾을 수 있게 돕는 중앙 저장소입니다. 컴퓨팅 엔진과 사용자가 테이블의 이름, 스키마, 저장 위치를 확인할 수 있는 창구 역할을 하며, Hive나 Project Nessie처럼 모든 시스템이 접근 가능한 개방형 카탈로그도 존재합니다.
1.2.6. 컴퓨팅 엔진 (Compute Engine)
저장된 데이터를 처리하기 위해 사용자의 워크로드를 실제로 실행하는 요소입니다. 데이터 양과 연산 부하에 따라 하나 이상의 엔진을 사용할 수 있으며, 대규모 데이터 세트를 위해 분산 처리 방식인 MPP(Massively Parallel Processing) 기반 엔진(Apache Spark, Dremio 등)이 주로 활용됩니다.
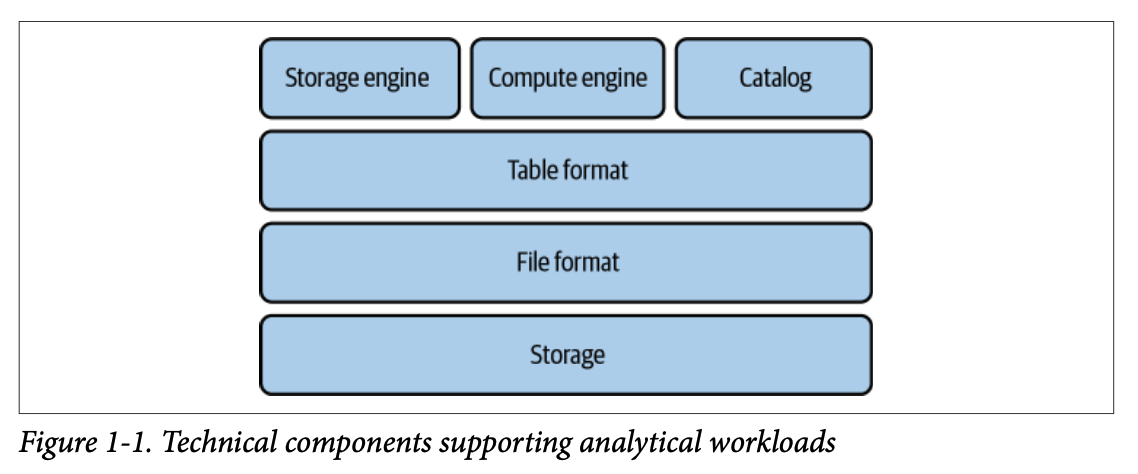
1.3. 데이터 웨어하우스
데이터 웨어하우스 또는 OLAP 데이터베이스는 운영 시스템, 애플리케이션 데이터베이스, 로그 등 다양한 소스에서 수집된 대량의 데이터를 저장할 수 있도록 지원하는 중앙 집중식 저장소입니다.
장점
다양한 소스에서 데이터를 저장하고 쿼리할 수 있어 단일 진실 공급원(single source of truth) 역할을 합니다.
대량의 이력 데이터를 쿼리할 수 있어 분석 워크로드를 빠르게 실행할 수 있습니다.
효과적인 데이터 거버넌스 정책을 제공하여 데이터 가용성, 사용성, 보안 정책 준수를 보장합니다.
데이터 레이아웃을 최적화하여 쿼리에 유리하게 구성합니다.
테이블에 기록된 데이터가 기술 스키마를 따르도록 보장합니다.
단점
데이터가 벤더 고정(vendor-specific system)되어 해당 웨어하우스의 컴퓨팅 엔진만 데이터를 사용할 수 있습니다.
스토리지와 컴퓨팅 모두에서 비용이 비싸고, 워크로드 증가에 따라 비용 관리가 어려워집니다.
주로 정형 데이터만 지원합니다.
머신러닝(ML)과 같은 고급 분석 워크로드를 직접 실행하는 데 제한적입니다.
스토리지와 컴퓨팅 구성 요소가 밀접하게 결합되어 있어 독립적인 확장이 어렵습니다.
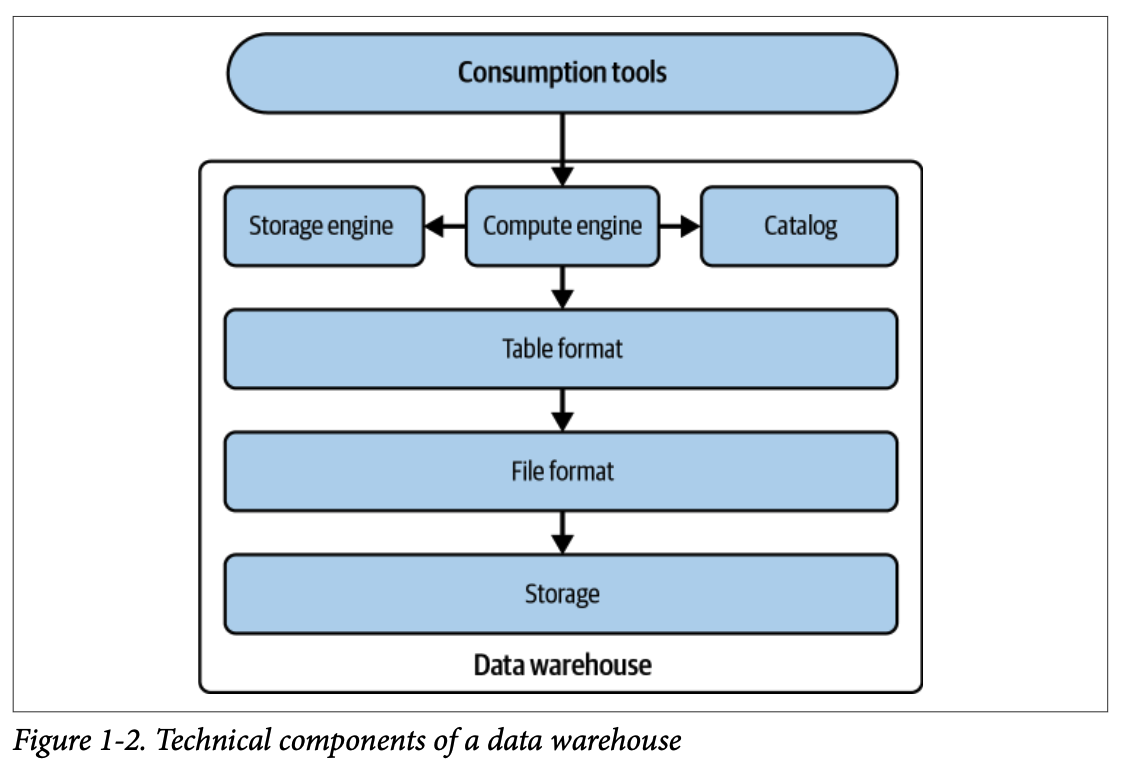
1.4. 데이터 레이크
데이터 레이크는 저렴한 비용으로 대량의 다양한 데이터를 저장하기 위해 등장했습니다.
장점
확장성과 유연성을 제공하여 정형, 반정형, 비정형 데이터를 저장할 수 있습니다.
데이터를 변환하지 않고 원시 형태로 저장하여 유연성을 높입니다.
데이터가 특정 벤더에 고정되지 않습니다.
데이터 웨어하우스에 비해 비용 효율적입니다.
단점
강력한 트랜잭션 무결성(ACID)이 부족하여 금융 시스템과 같은 중요한 애플리케이션에는 적합하지 않았습니다.
파일 수준 변경의 비효율성, 여러 파티션에 대한 원자적 업데이트 불가능, 동시 업데이트 지원 부족, 과도한 파일 목록화로 인한 쿼리 계획 지연과 같은 문제가 있었습니다.
데이터 레이크에는 스토리지 엔진 기능에 대한 서비스를 제공하지 않으며, 데이터는 종종 최적화되지 않은 채로 남습니다.
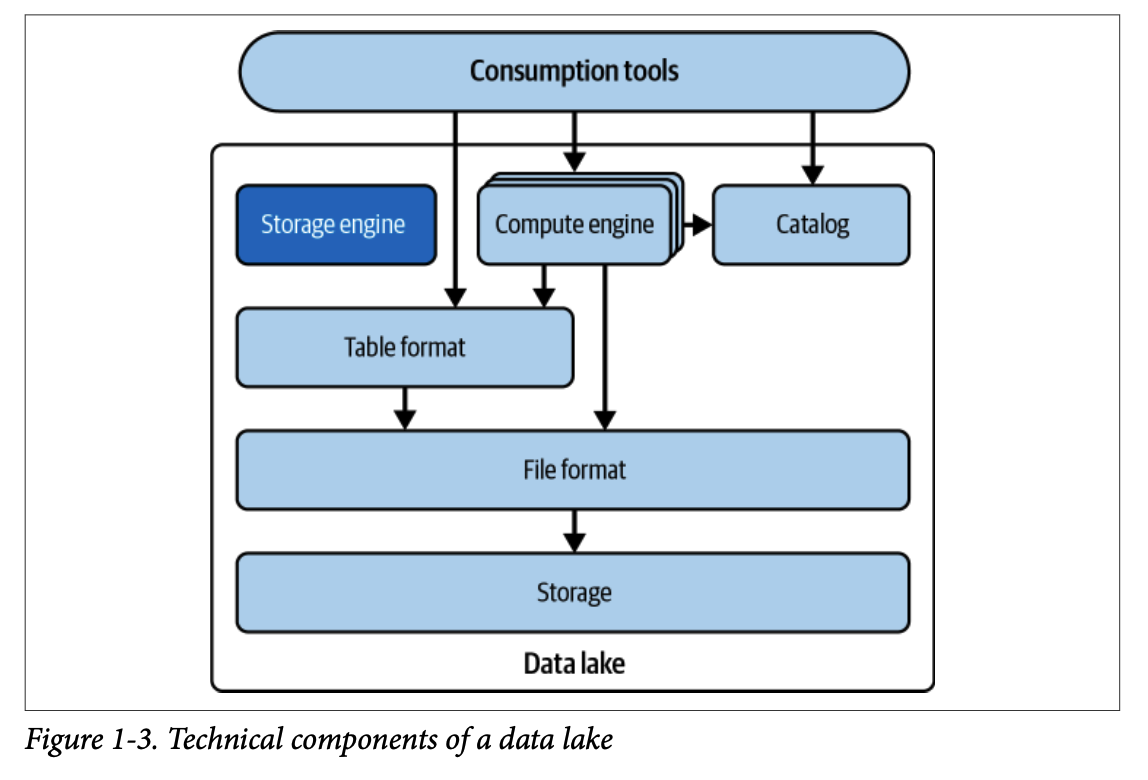
1.5. 데이터 레이크하우스
데이터 레이크하우스 아키텍처는 데이터 웨어하우스와 데이터 레이크의 장점을 결합하여 데이터 레이크의 확장성과 비용 효율성을 유지하면서 ACID 트랜잭션, 성능, 그리고 확장성과 같은 데이터 웨어하우스 기능을 제공합니다. 이는 아파치 아이스버그와 같은 개방형 table format 위에 구축되어 벤더 종속성을 피합니다.
가치 제안
복사본 감소 = 데이터 불일치 감소
ACID 보장 및 향상된 성능으로 인해 일반적으로 데이터 웨어하우스에서 수행하던 업데이트 및 데이터 조작 작업을 데이터 레이크하우스로 옮길 수 있어 비용을 절감하고 데이터 이동을 줄입니다.
이력 데이터 스냅샷 = 실수를 두려워하지 않음
데이터 레이크하우스 Table Format은 이력 데이터 스냅샷을 유지하여 테이블을 이전 스냅샷으로 쿼리하고 복원할 수 있습니다.
저렴한 아키텍처 = 비즈니스 가치
데이터 레이크하우스는 수익 증대뿐만 아니라 비용 절감에도 도움이 됩니다. 데이터 중복을 피하고, 추가 ETL 작업으로 인한 컴퓨팅 비용을 피하며, 기존 데이터 웨어하우스 요율에 비해 스토리지 및 컴퓨팅 비용이 저렴합니다.
개방형 아키텍처 = 안심
아파치 아이스버그와 같은 개방형 형식을 기반으로 구축되어 벤더 고정을 피하고 다양한 도구가 데이터를 읽고 쓸 수 있도록 합니다.
2. Table Format이란?
Table Format은 데이터 세트의 파일을 하나의 통합된 "테이블"로 구성하는 방법입니다. 사용자 관점에서는 "이 테이블에 어떤 데이터가 있는가?"라는 질문에 대한 답으로 정의될 수 있습니다. 주요 목적은 사용자 및 도구가 기본 데이터와 효율적으로 상호 작용할 수 있도록 테이블에 대한 추상화(abstraction)를 제공하는 것입니다.
2.1. 하이브 (Hive): 초기 Table Format
하이브는 2009년 페이스북에서 개발한 프레임워크로, 하둡 데이터 레이크에서 SQL을 작성하여 분석을 쉽게 할 수 있도록 했습니다. 하이브 Table Format은 특정 디렉터리(또는 객체 스토리지의 접두사) 내의 모든 파일을 하나의 테이블로 정의하고, 하이브 메타스토어(Hive Metastore)를 통해 테이블 경로를 추적했습니다.
장점
파티셔닝 및 버킷팅과 같은 기술을 통해 전체 테이블 스캔보다 효율적인 쿼리 패턴을 가능하게 했습니다.
파일 형식에 구애받지 않아(file format agnostic) Apache Parquet와 같은 더 나은 파일 형식을 사용할 수 있었습니다.
하이브 메타스토어에서 나열된 디렉터리의 원자적 스왑을 통해 단일 파티션에 대한 원자적 변경이 가능했습니다.
시간이 지남에 따라 사실상 표준이 되어 대부분의 데이터 도구에서 작동했습니다.
단점
파일 수준 변경이 비효율적이었습니다.
여러 파티션에 걸친 원자적 업데이트를 지원하지 않았습니다.
파티션 열이 다른 열에서 파생되는 경우가 많아 사용자가 파티션 열을 명시적으로 필터링하지 않으면 전체 테이블 스캔으로 이어질 수 있었습니다.
테이블 통계는 비동기식 작업으로 수집되어 최신 정보가 아니거나 아예 없는 경우가 많아 쿼리 엔진이 쿼리를 최적화하기 어려웠습니다.
객체 스토리지에서 동일한 접두사에 대한 요청을 스로틀링하는 경우가 많아, 단일 파티션에 파일이 많은 테이블에서 성능 문제가 발생할 수 있었습니다.
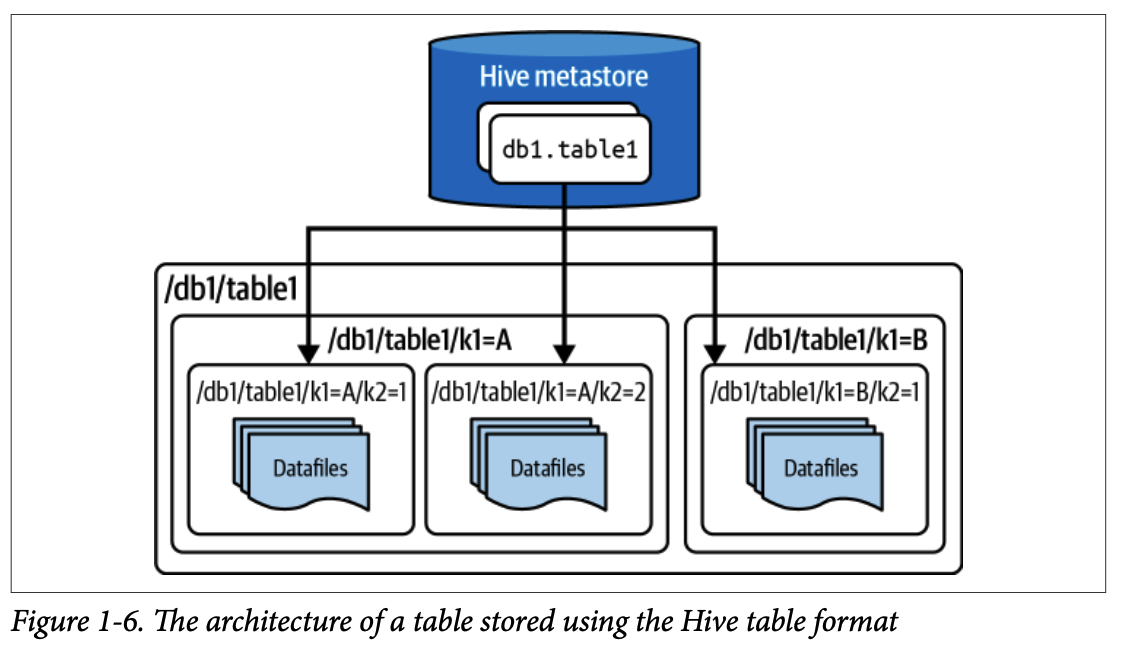
2.2. 현대 데이터 레이크 Table Format
하이브 Table Format의 한계를 해결하기 위해 새로운 세대의 Table Format이 등장했습니다. 아파치 아이스버그, 아파치 후디(Apache Hudi), 델타 레이크(Delta Lake)와 같은 현대 Table Format은 테이블 정의를 디렉터리 내용이 아닌 정규 파일 목록으로 하는 접근 방식을 취했습니다. 이는 ACID 트랜잭션, 타임 트래블(Time Travel)과 같은 기능을 가능하게 했습니다.
핵심 이점
ACID 트랜잭션을 허용합니다.
여러 작성기(multiple writers)에서 안전한 트랜잭션을 가능하게 합니다.
쿼리 엔진이 스캔을 효율적으로 계획할 수 있도록 테이블 통계 및 메타데이터를 더 잘 수집합니다.
3. 아파치 아이스버그 (Apache Iceberg)란?
아파치 아이스버그는 넷플릭스에서 2017년에 개발하고 2018년에 오픈 소스화된 Table Format으로, 하이브의 성능, 일관성 및 기타 문제를 극복하기 위해 만들어졌습니다. 아이스버그는 테이블을 디렉터리 목록이 아닌 정규 파일 목록으로 정의하는 데 중점을 둡니다.
3.1. 핵심 목표
일관성 (Consistency)
다중 파티션에 걸친 업데이트 시에도 최종 사용자가 일관되지 않은 데이터를 경험하지 않도록 보장합니다.
성능 (Performance)
과도한 파일 목록화를 피하고 필요한 파일만 스캔하여 쿼리 계획 및 실행을 가속화합니다.
사용 용이성 (Ease to use)
숨겨진 파티셔닝(hidden partitioning)을 통해 사용자가 테이블의 물리적 구조를 알 필요 없이 파티셔닝의 이점을 누릴 수 있도록 합니다.
진화 가능성 (Evolvability)
스키마 및 파티셔닝 스키마를 안전하게 업데이트할 수 있도록 하여 전체 테이블을 다시 작성할 필요가 없습니다.
확장성 (Scalability)
페타바이트 규모의 데이터에서도 모든 목표를 달성할 수 있도록 설계되었습니다.
4. 아파치 아이스버그 아키텍처 및 주요 기능
아파치 아이스버그는 메타데이터 트리(metadata tree)를 사용하여 테이블의 파티셔닝, 정렬, 스키마 변화 등을 추적하며, 이는 세 가지 구성 요소(매니페스트 파일, 매니페스트 목록, 메타데이터 파일)로 이루어져 있습니다. 카탈로그(Catalog)는 테이블의 최신 메타데이터 파일 위치를 추적하는 중앙 위치입니다.
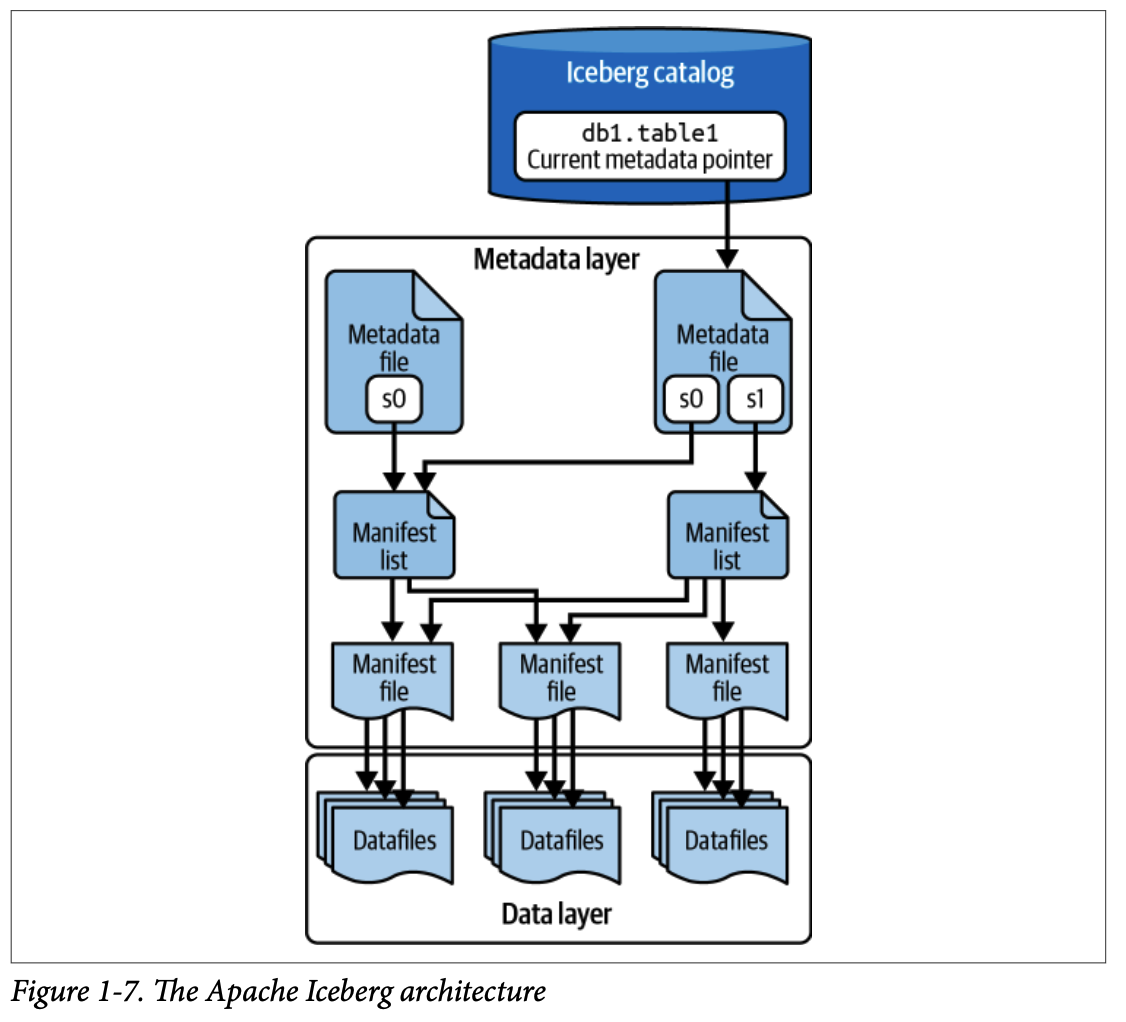
4.1. 주요 기능
4.1.1. ACID 트랜잭션
낙관적 동시성 제어(optimistic concurrency control)를 통해 다중 읽기/쓰기 환경에서도 ACID 보장을 제공합니다.
4.1.2. 파티션 진화 (Partition Evolution)
테이블 전체를 다시 작성할 필요 없이 파티셔닝 방식을 언제든지 업데이트할 수 있습니다.
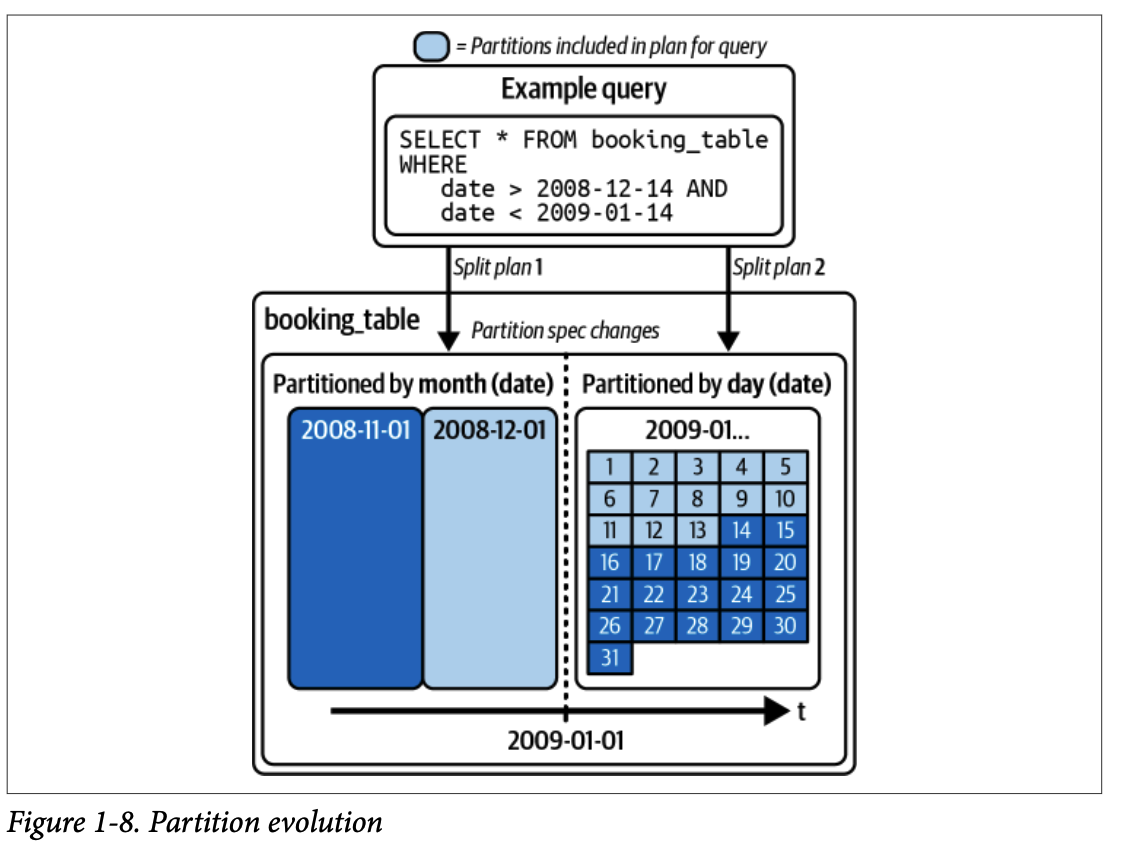
4.1.3. 숨겨진 파티셔닝 (Hidden Partitioning)
사용자가 파티션 열을 명시적으로 필터링할 필요 없이 기본 열에 대한 쿼리에서도 파티셔닝의 이점을 얻을 수 있습니다.
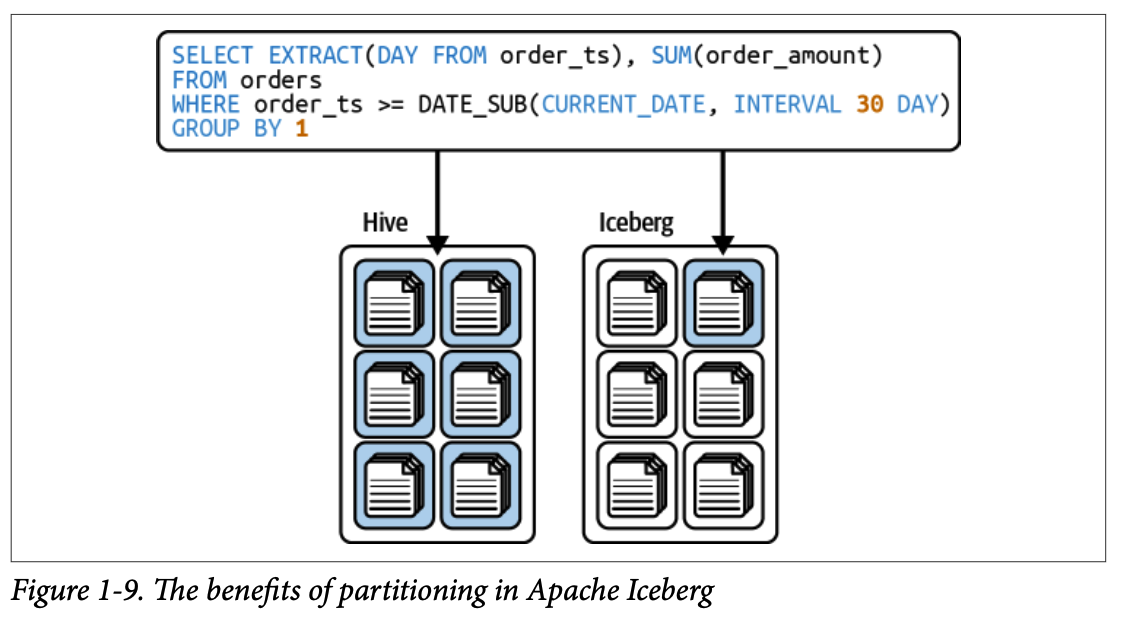
4.1.4. 행 수준 테이블 작업 (Row-level table operations)
Copy-on-Write (COW) 또는 Merge-on-Read (MOR) 방식을 사용하여 행 수준 업데이트 및 삭제 작업을 최적화할 수 있습니다.
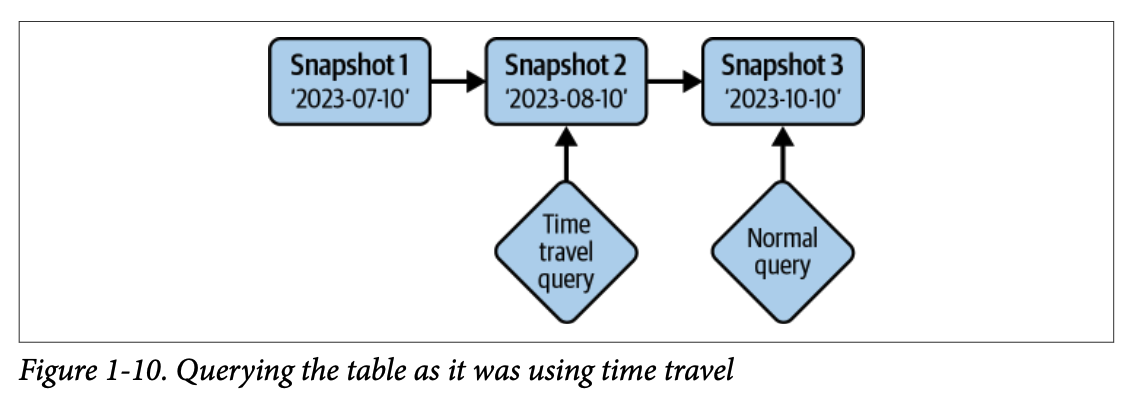
4.1.5. 타임 트래블 (Time Travel)
테이블의 과거 상태에 대한 불변 스냅샷을 제공하여 특정 시점의 데이터를 쿼리할 수 있습니다.
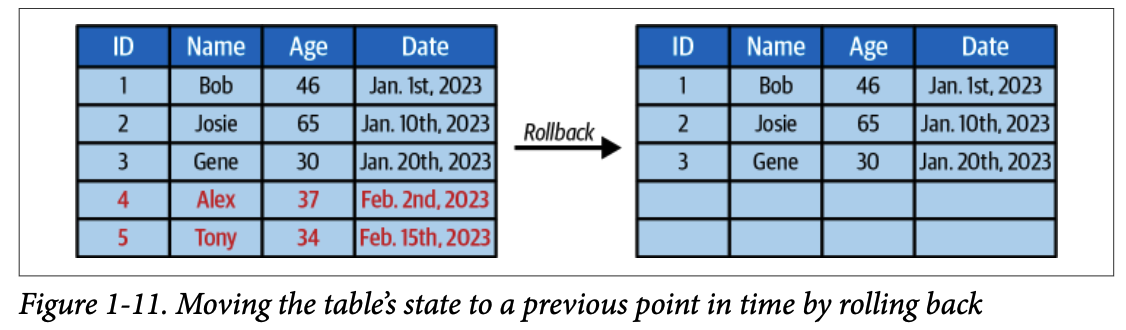
4.1.6. 버전 롤백 (Version Rollback)
테이블의 현재 상태를 이전 스냅샷으로 되돌릴 수 있습니다.
4.1.7. 스키마 진화 (Schema Evolution)
열 추가/제거, 이름 변경, 데이터 타입 변경 등을 안전하게 수행할 수 있습니다.
아파치 아이스버그는 이러한 기능들을 통해 데이터 레이크에서 고성능과 신뢰성을 제공하며 데이터 레이크하우스 아키텍처의 핵심 기술이 됩니다.
99. 참고문헌
https://www.oreilly.com/library/view/apache-iceberg-the/9781098148614/