Apache Iceberg 쿼리 생명주기 완벽 가이드
1. 아이스버그의 3계층과 쿼리 엔진의 상호작용
쿼리 엔진은 읽기/쓰기 작업 시 아이스버그의 세 계층과 다음과 같이 상호작용합니다
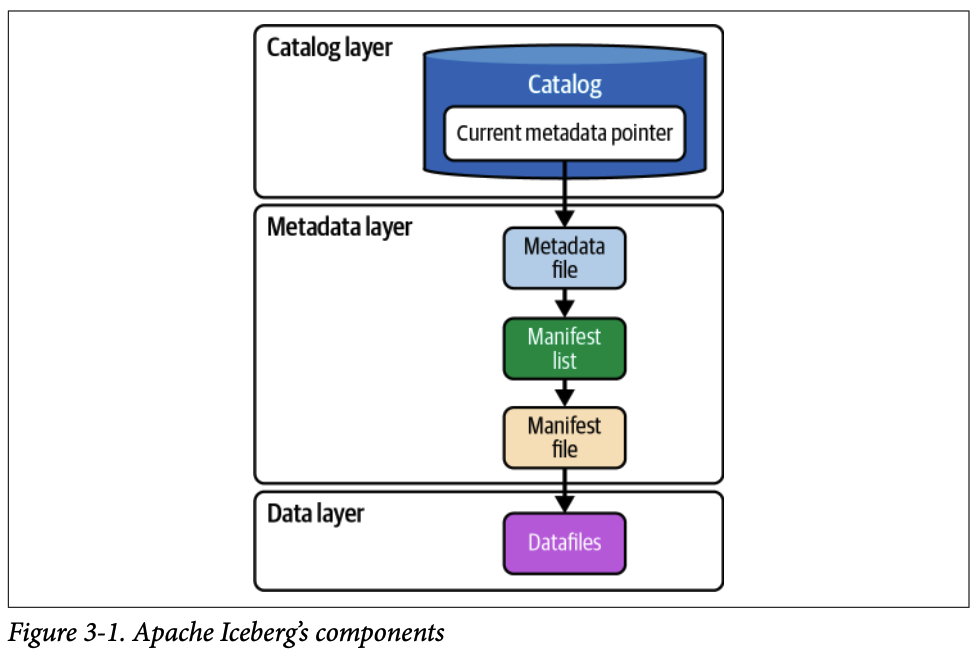
1.1. 카탈로그 계층 (Catalog Layer)
모든 쿼리의 시작점입니다.
읽기: 엔진은 카탈로그를 통해 테이블의 현재 상태, 즉 최신 메타데이터 파일의 위치를 파악합니다.
쓰기: 엔진은 카탈로그를 조회하여 테이블의 스키마와 파티셔닝 전략을 확인하고, 작업 완료 후 새 메타데이터 파일의 위치를 원자적으로(atomically) 업데이트하여 커밋을 완료합니다.
1.2. 메타데이터 계층 (Metadata Layer)
성능 최적화의 핵심입니다.
계층적 필터링: 이 계층은 메타데이터 파일(metadata file), 매니페스트 리스트(manifest list), 매니페스트 파일(manifest file)로 구성됩니다. 각 단계는 다음 단계에서 스캔할 파일의 범위를 좁히기 위한 통계 정보를 담고 있습니다.
File Pruning:
엔진은 먼저 매니페스트 리스트의 파티션 경계값 통계를 이용해 관련 없는 매니페스트 파일들을 건너뜁니다.
그다음, 남은 매니페스트 파일을 열어 개별 데이터 파일의 컬럼별 통계(최대/최소값, null 개수 등)를 확인하고, 쿼리 조건에 맞지 않는 데이터 파일들을 건너뜁니다. 이 과정을 통해 불필요한 I/O를 최소화합니다.
1.3. 데이터 계층 (Data Layer)
실제 데이터가 저장되는 곳입니다.
읽기: 엔진은 메타데이터 계층에서 필터링된 데이터 파일들만 스캔하여 결과를 반환합니다.
쓰기: 새로운 데이터 파일이 파일 스토리지에 생성되고, 이와 관련된 메타데이터 파일들이 업데이트됩니다.
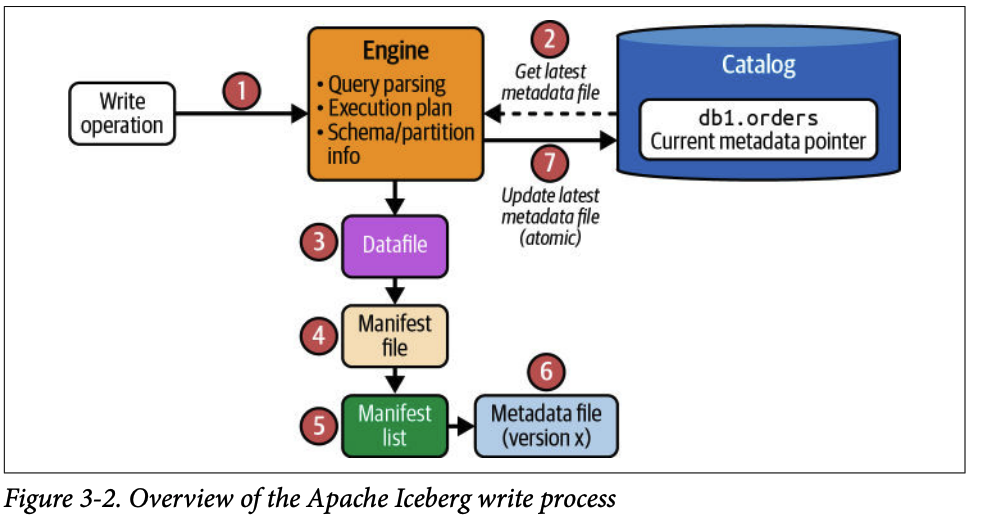
2. 쓰기 쿼리의 생명주기 (Writing Queries in Apache Iceberg)
쓰기 프로세스는 여러 단계에 걸쳐 데이터 파일과 메타데이터 파일을 생성하고, 마지막에 카탈로그를 원자적으로 업데이트하여 트랜잭션을 완료합니다.
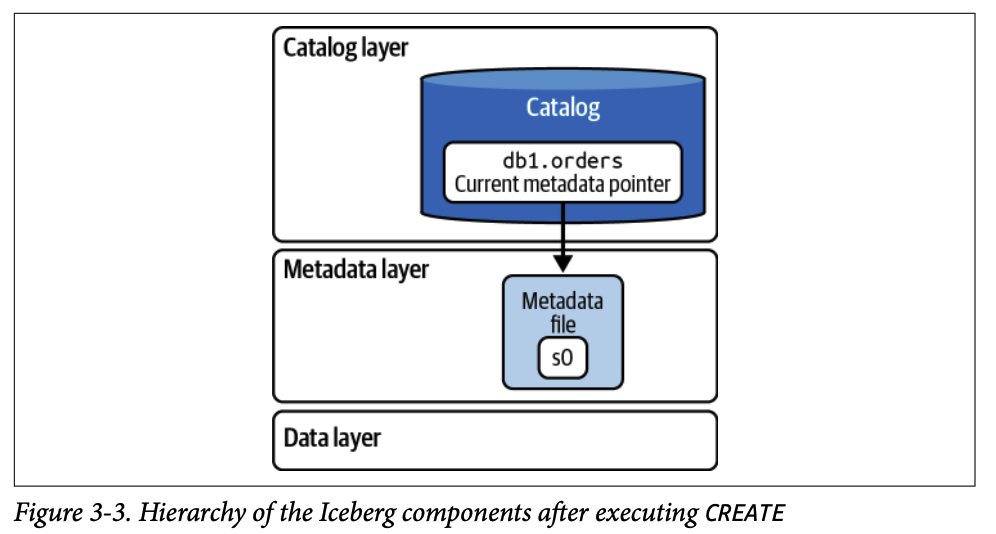
2.1. 테이블 생성 (CREATE TABLE)
# Spark SQL
CREATE TABLE orders (
order_id BIGINT,
customer_id BIGINT,
order_amount DECIMAL(10, 2),
order_ts TIMESTAMP
)
USING iceberg
PARTITIONED BY (HOUR(order_ts))2.1.1. 1단계 (쿼리를 엔진으로 전송)
쿼리 엔진이 CREATE TABLE 문을 파싱합니다.
2.1.2. 2단계 (메타데이터 파일 생성)
엔진은 테이블 스키마, 파티션 명세, 고유 식별자(table-uuid) 등의 정보를 담은 첫 번째 메타데이터 파일(v1.metadata.json)을 데이터 레이크 파일 시스템에 생성합니다. 이 시점에는 데이터가 없으므로 데이터 파일이나 매니페스트 파일은 생성되지 않습니다.
2.1.3. 3단계 (카탈로그 업데이트)
카탈로그의 현재 메타데이터 포인터가 v1.metadata.json을 가리키도록 업데이트하여 커밋을 완료합니다.
2.2. 데이터 삽입 (INSERT INTO)
# Spark SQL
INSERT INTO orders VALUES (
123,
456,
36.17,
'2023-03-07 08:10:23'
)2.2.1. 1단계 (쿼리를 엔진으로 전송)
INSERT문이므로 query planning을 시작하기 위해 스키마 등의 테이블 정보가 필요합니다.
2.2.2. 2단계 (카탈로그 조회)
엔진은 카탈로그에서 현재 메타데이터 파일(v1.metadata.json)의 위치를 확인하여 테이블 스키마와 파티셔닝 구성을 파악합니다.
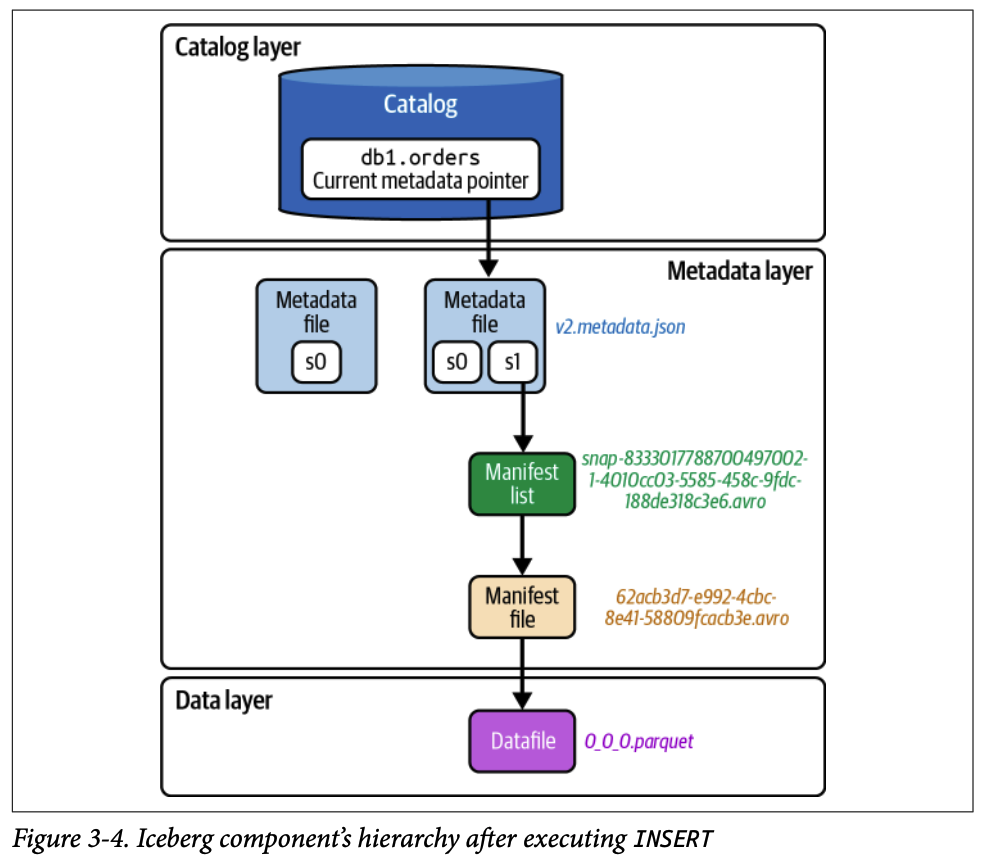
2.2.3. 3단계 (데이터 파일과 메타데이터 파일 생성)
파티셔닝 전략에 따라 데이터를 Parquet 파일로 저장합니다. 정렬 순서가 정의되어 있으면 데이터 파일에 쓰기 전에 레코드 정렬합니다.
새 데이터 파일의 경로와 컬럼별 통계 정보(최대/최소값 등)를 포함하는 매니페스트 파일을 생성합니다.
생성된 매니페스트 파일을 추적하는 매니페스트 리스트 파일을 만듭니다.
이전 메타데이터 파일(v1)을 기반으로 새로운 스냅샷 정보를 추가한 새 메타데이터 파일(v2.metadata.json)을 생성합니다.
2.2.4. 4단계 (원자적 커밋)
엔진은 카탈로그에 다시 접근하여 다른 쓰기 작업과의 충돌이 없는지 확인한 후, 메타데이터 포인터를 v2.metadata.json으로 원자적으로 업데이트합니다. 이를 통해 트랜잭션의 일관성을 보장합니다.
2.3. 데이터 병합 (MERGE INTO)
MERGE INTO는 조건에 따라 기존 행을 업데이트하거나 새 행을 삽입하는 작업입니다.
# Spark SQL
MERGE INTO orders o
USING (SELECT * FROM orders_staging) s
ON o.order_id = s.order_id
WHEN MATCHED THEN UPDATE SET order_amount = s.order_amount
WHEN NOT MATCHED THEN INSERT *;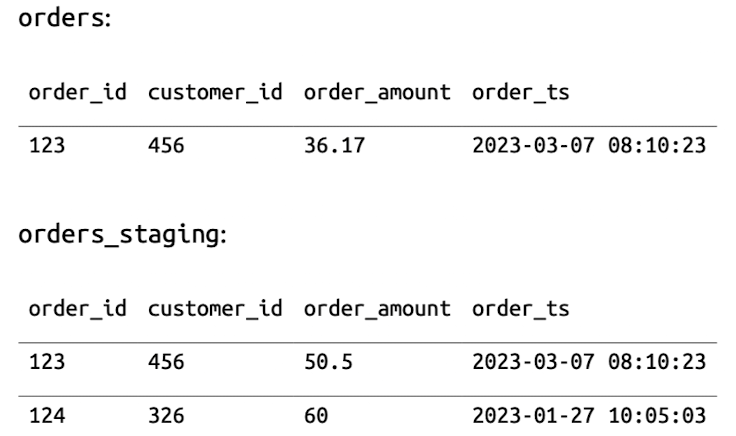
2.3.1. 1단계 (쿼리를 엔진으로 전송)
query planning을 위해 두 테이블의 데이터가 필요합니다.
2.3.2. 2단계 (카탈로그 조회)
현재 메타데이터 파일(v2.metadata.json)의 위치를 확인하여 테이블 스키마와 파티셔닝 구성을 파악합니다.
2.3.3. 3단계 (데이터 파일과 메타데이터 파일 생성)
엔진은 소스 테이블과 대상 테이블의 데이터를 메모리에 로드하여 일치하는 레코드를 찾습니다.
쓰기 전략 (Copy-on-Write (COW), Merge-on-Read (MOR)):
COW: 테이블 업데이트 시 관련 데이터 파일을 새 데이터 파일로 재작성
MOR: 데이터 파일을 재작성하지 않고 새로운 Delete File을 생성하여 변경사항 추적
COW 전략 예시:
매칭되는 데이터가 있는 경우:
../order_ts_hour=2023-03-07-08/0_0_0.parquet파일을 메모리로 읽음메모리에서 order_amount 업데이트
수정된 데이터를 새 parquet 파일(
../order_ts_hour=2023-03-07-08/0_0_0_1.parquet)로 작성
매칭되지 않는 데이터가 있는 경우:
매칭되지 않은 레코드는 일반 INSERT로 처리
다른 파티션에 새 데이터 파일(
../order_ts_hour=2023-01-27-10/0_0_0.parquet)로 작성
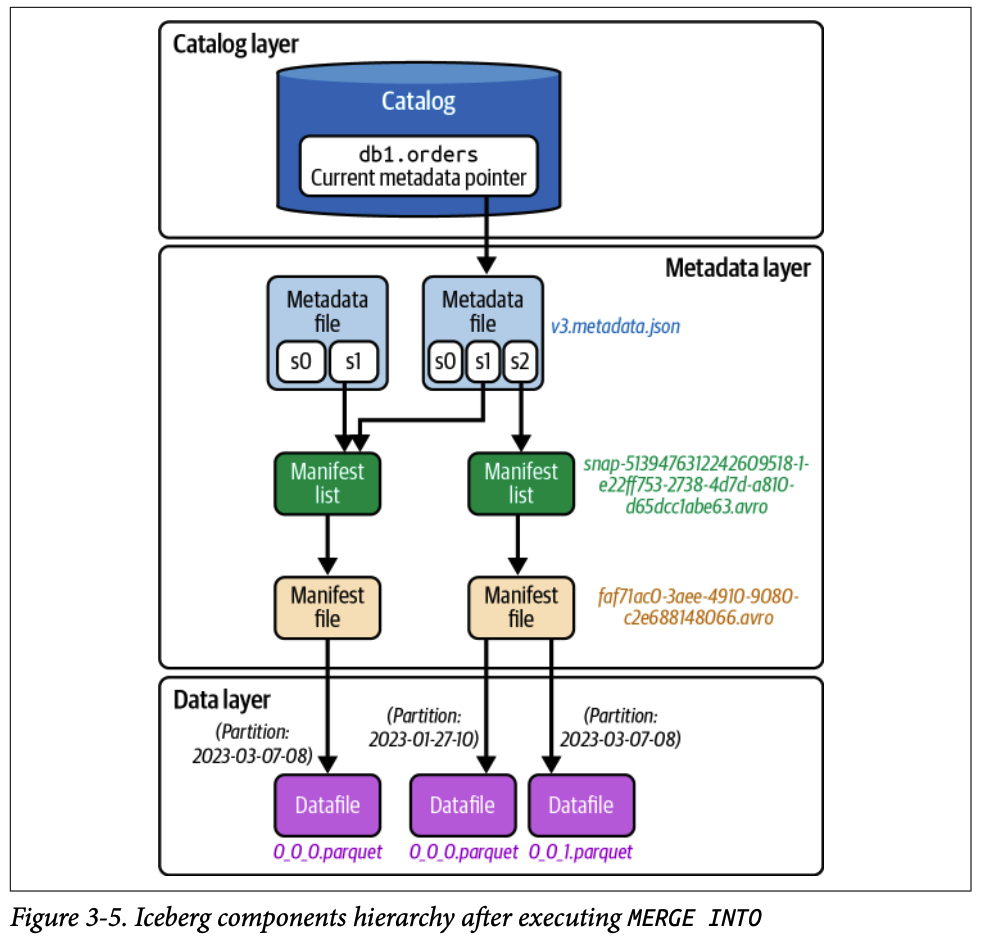
2.3.4. 4단계 (카탈로그 파일 업데이트)
INSERT와 동일하게 새 매니페스트 파일, 매니페스트 리스트, 새 메타데이터 파일(v3.metadata.json)을 순차적으로 생성한 후 카탈로그 포인터를 원자적으로 업데이트하여 작업을 완료합니다.
2.4. 동시성 제어와 원자적 커밋
앞서 살펴본 쓰기 쿼리들(CREATE, INSERT, MERGE)에서 공통적으로 마지막 단계는 "카탈로그 파일을 업데이트하여 변경사항 커밋"이었습니다. 이 과정이 단순해 보일 수 있지만, 실제로는 Apache Iceberg의 가장 핵심적인 메커니즘인 원자적 커밋과 동시성 제어가 작동하는 중요한 순간입니다.
실제 운영 환경에서는 여러 사용자나 프로세스가 동시에 같은 테이블에 데이터를 쓰려고 할 수 있습니다. Apache Iceberg는 이러한 동시 쓰기 상황에서도 데이터 무결성을 보장하고 모든 변경사항이 손실 없이 반영되도록 낙관적 동시성 제어(Optimistic Concurrency Control, OCC) 메커니즘을 사용합니다.
2.4.1. 낙관적 동시성 제어(Optimistic Concurrency Control)란?
낙관적 동시성 제어는 "기본적으로 트랜잭션들이 서로 충돌하지 않을 것"이라고 가정하고 작업을 진행합니다. 각 쓰기 작업은 다른 작업의 간섭 없이 독립적으로 진행되며, 마지막 커밋 단계에서만 충돌이 있었는지 검사합니다. 충돌이 감지되면 해당 작업은 실패하고 재시도됩니다.
이는 비관적 동시성 제어(Pessimistic Concurrency Control)와 대비됩니다. 비관적 방식은 작업 시작 전에 락(lock)을 획득하여 다른 작업이 접근하지 못하도록 막지만, 낙관적 방식은 락 없이 진행하다가 커밋 시점에만 검증합니다.
장점:
락을 획득하고 유지하는 오버헤드가 없어 대부분의 경우 더 빠름
읽기 작업이 쓰기 작업에 의해 블로킹되지 않음
충돌이 드문 환경에서 특히 효율적
단점:
충돌이 발생하면 재시도해야 하므로 충돌이 빈번한 경우 비효율적일 수 있음
2.4.2. 동시 쓰기 시나리오: 실제 예제
두 개의 MERGE 쿼리가 거의 동시에 같은 테이블에 실행되는 상황을 단계별로 살펴보겠습니다.
초기 상태:
테이블의 현재 메타데이터:
v3.metadata.json쓰기 작업 A: 고객 456의 주문 금액을 업데이트
쓰기 작업 B: 고객 789의 새로운 주문 삽입
2.4.3. 1단계: 현재 메타데이터 확인
쓰기 A:
카탈로그 확인 → 현재 메타데이터: v3.metadata.json
기준 버전: v3쓰기 B:
카탈로그 확인 → 현재 메타데이터: v3.metadata.json
기준 버전: v3두 작업 모두 v3를 기준으로 작업을 시작합니다. 이 시점에는 서로의 존재를 모릅니다.
2.4.4. 2단계: 데이터 및 메타데이터 파일 생성 (낙관적 작업)
쓰기 A:
1. 데이터 파일 작성: 0_0_5.parquet (고객 456 업데이트)
2. 매니페스트 파일 생성: manifest-A.avro
3. 매니페스트 리스트 생성: snap-A.avro
4. 새 메타데이터 파일 생성: v4_A.metadata.json (v3 기반)쓰기 B:
1. 데이터 파일 작성: 0_0_6.parquet (고객 789 신규)
2. 매니페스트 파일 생성: manifest-B.avro
3. 매니페스트 리스트 생성: snap-B.avro
4. 새 메타데이터 파일 생성: v4_B.metadata.json (v3 기반)중요: 이 단계에서는 파일들이 파일 시스템에 작성되었을 뿐, 아직 테이블에 공식적으로 반영되지 않았습니다. 두 작업 모두 v3를 기준으로 자신만의 메타데이터를 생성했지만, 카탈로그는 여전히 v3를 가리키고 있습니다.
2.4.5. 3단계: 커밋 시도 - 쓰기 A 성공
쓰기 A가 먼저 카탈로그에 커밋을 시도합니다.
Compare-And-Swap (CAS) 연산:
조건: 현재 메타데이터가 v3.metadata.json인가?
→ 예 (v3가 맞음)
→ 포인터를 v4_A.metadata.json으로 변경
→ 커밋 성공!결과:
테이블의 현재 메타데이터:
v3.metadata.json→v4_A.metadata.json쓰기 A의 변경사항이 공식적으로 테이블에 반영됨
2.4.6. 4단계: 커밋 시도 - 쓰기 B 실패
직후에 쓰기 B가 카탈로그에 커밋을 시도합니다.
Compare-And-Swap (CAS) 연산:
조건: 현재 메타데이터가 v3.metadata.json인가?
→ 아니오 (현재는 v4_A.metadata.json)
→ 조건 불일치!
→ 커밋 실패실패 이유: 쓰기 B가 작업을 시작했을 때는 메타데이터가 v3였지만, 커밋을 시도하는 시점에는 이미 쓰기 A가 v4_A로 변경했습니다. 이는 쓰기 B가 작업한 기준 상태가 더 이상 최신이 아니라는 뜻입니다.
2.4.7. 5단계: 쓰기 B 재시도
쓰기 B의 재시도 과정:
1. 카탈로그 재확인 → 현재 메타데이터: v4_A.metadata.json
2. 새로운 기준 버전: v4_A
3. v4_A를 기반으로 작업 재수행:
- 쓰기 A의 변경사항 포함된 상태에서 MERGE 로직 재실행
- 새 데이터 파일: 0_0_7.parquet (필요시)
- 새 매니페스트 파일 및 리스트 생성
- 새 메타데이터 파일 생성: v5.metadata.json (v4_A 기반)
4. 커밋 재시도:
조건: 현재 메타데이터가 v4_A.metadata.json인가?
→ 예 (v4_A가 맞음)
→ 포인터를 v5.metadata.json으로 변경
→ 커밋 성공!최종 결과:
테이블의 현재 메타데이터:
v5.metadata.json쓰기 A와 쓰기 B의 변경사항이 모두 선형적 이력으로 반영됨
메타데이터 이력:
v3→v4_A(쓰기 A) →v5(쓰기 B)
2.4.8. Compare-And-Swap (CAS) 연산의 원자성
CAS 연산은 다음 두 단계를 원자적으로(atomically) 수행합니다:
Compare (비교): 현재 값이 예상한 값(expected value)과 같은지 확인
Swap (교체): 같다면 새로운 값으로 교체
이 두 단계 사이에 다른 작업이 끼어들 수 없기 때문에, 여러 작업이 동시에 커밋을 시도해도 정확히 하나만 성공하고 나머지는 실패합니다.
카탈로그별 CAS 구현:
Hadoop Catalog: 파일 시스템의 원자적 rename 연산 활용
Hive Metastore: Hive의 트랜잭션 메커니즘 활용
AWS Glue: Glue의 optimistic locking 기능 활용
Nessie/REST Catalog: 버전 관리 시스템의 commit 메커니즘 활용
각 카탈로그 구현체는 자신의 저장소가 제공하는 원자적 연산을 활용하여 CAS를 보장합니다.
2.4.9. 왜 낙관적 동시성 제어를 사용하는가?
1. 성능 최적화
락(lock)을 획득하고 유지할 필요가 없어 대부분의 경우 더 빠름
쓰기 작업이 서로를 블로킹하지 않음
2. 읽기 성능 보장
읽기 작업은 쓰기 락의 영향을 받지 않음
읽기와 쓰기가 서로 방해하지 않음
3. 분산 환경 적합성
데이터 레이크는 분산 스토리지 환경
중앙 집중식 락 관리가 어렵고 비효율적
낙관적 방식이 분산 환경에 더 적합
4. 충돌이 드문 실제 환경
실무에서 정확히 같은 시점에 같은 테이블에 쓰기가 발생하는 경우는 드묾
대부분의 경우 재시도 없이 한 번에 성공
2.4.10. 선형 이력(Linear History)의 중요성
낙관적 동시성 제어 덕분에 아이스버그는 모든 변경사항이 선형적인 이력으로 기록됩니다.
선형 이력이 보장하는 것:
추적 가능성: 모든 변경사항의 순서를 정확히 파악 가능
Time Travel: 특정 시점의 데이터 상태로 정확히 되돌아갈 수 있음
감사(Audit): 누가, 언제, 무엇을 변경했는지 추적 가능
디버깅: 문제 발생 시 변경 이력을 따라가며 원인 파악 가능
선형 이력 예시:
v1.metadata.json (CREATE TABLE)
↓
v2.metadata.json (INSERT - 사용자 A)
↓
v3.metadata.json (MERGE - 사용자 B)
↓
v4.metadata.json (UPDATE - 사용자 A)
↓
v5.metadata.json (DELETE - 사용자 C)각 메타데이터 파일은 이전 상태(parent)를 참조하므로, 전체 이력을 재구성할 수 있습니다.
2.4.11. 요약
Apache Iceberg의 낙관적 동시성 제어는 다음과 같이 작동합니다:
낙관적 작업: 각 쓰기 작업은 현재 메타데이터를 기준으로 독립적으로 새 파일들을 생성
원자적 검증: 커밋 시점에 Compare-And-Swap 연산으로 메타데이터 버전 확인
충돌 처리: 버전이 변경되었다면 커밋 실패 후 최신 버전 기준으로 재시도
선형 이력 보장: 모든 변경사항이 순차적으로 기록되어 데이터 무결성 유지
이러한 메커니즘 덕분에 여러 쓰기 작업이 동시에 발생하더라도 데이터 손실이나 덮어쓰기 없이 모든 변경사항이 안전하게 반영됩니다. 이것이 바로 Apache Iceberg가 데이터 레이크에서 ACID 트랜잭션을 보장하는 핵심 원리입니다.
3. 읽기 쿼리의 생명주기 (Reading Queries in Apache Iceberg)
읽기 쿼리는 계층적 메타데이터를 활용하여 스캔해야 할 데이터 파일의 수를 최소화함으로써 높은 성능을 달성합니다.
3.1. 일반 조회 (SELECT)
# Spark SQL/Dremio Sonar
SELECT *
FROM orders
WHERE order_ts BETWEEN '2023-01-01' AND '2023-01-31'3.1.1. 1단계: 쿼리를 엔진으로 전송
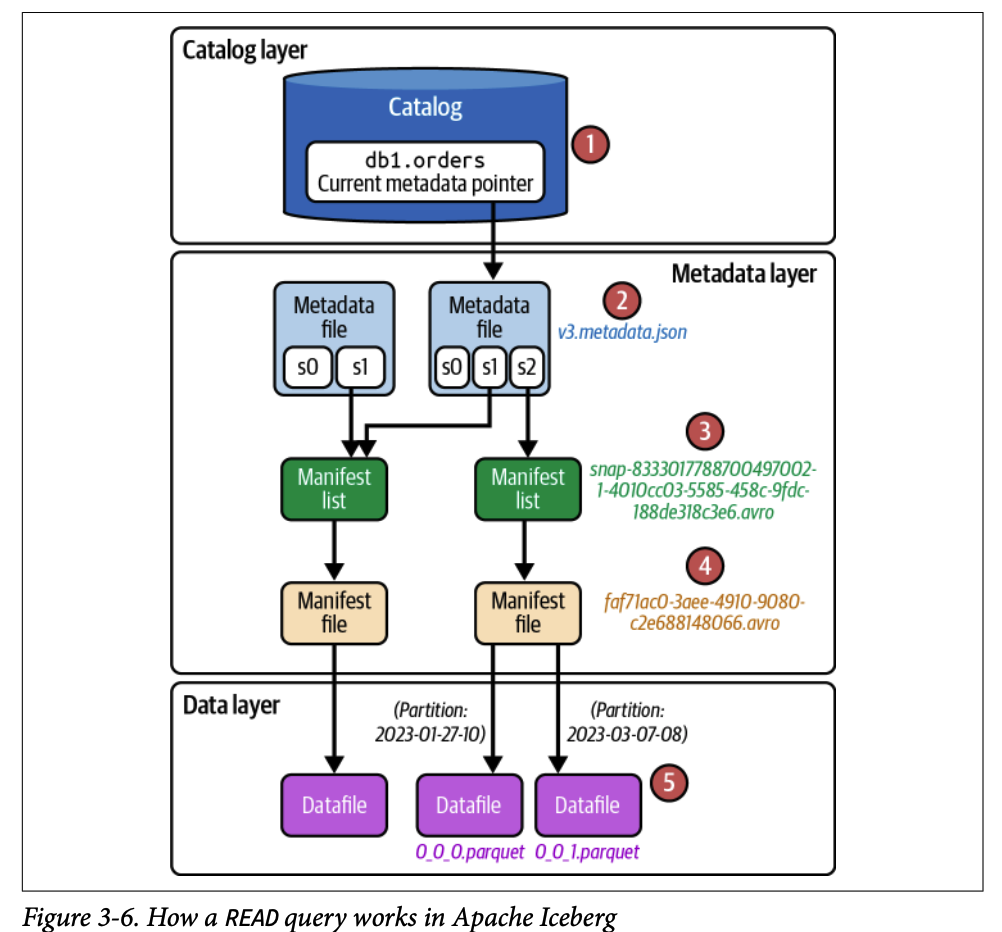
엔진이 메타데이터 파일을 기반으로 쿼리 계획을 시작합니다.
3.1.2. 2단계: 카탈로그 조회
현재 메타데이터 파일 경로를 요청합니다.
현재 메타데이터 파일: /orders/metadata/v3.metadata.json
3.1.3. 3단계: 메타데이터 파일 로드
테이블 스키마 확인 (내부 메모리 구조 준비)
파티셔닝 방식 확인 (데이터 구성 방식 이해)
current-snapshot-id 확인 (테이블의 현재 상태)
현재 스냅샷 기준으로 매니페스트 리스트 파일 경로 찾기
3.1.4. 4단계: 매니페스트 리스트에서 정보 가져오기
snap-*.avro파일 읽기중요 정보:
실제 데이터 파일 참조를 포함하는 매니페스트 파일 경로
추가/삭제된 데이터 파일 수, 파티션 통계 정보
partition-spec-id: 특정 스냅샷 작성에 사용된 파티션 방식
파티션별 통계: 매니페스트의 파티션 컬럼 상한/하한값
파일 프루닝을 위해 어떤 매니페스트 파일을 건너뛸지 결정
3.1.5. 5단계: 매니페스트 파일에서 정보 가져오기
프루닝되지 않은(쿼리와 관련된) 매니페스트 파일 열기
각 항목은 이 매니페스트 파일이 추적하는 데이터 파일을 나타냄
각 데이터 파일의 파티션 값을 쿼리 필터 값과 비교
파티션 값이 필터 값 범위와 일치하지 않으면 무시
통계 정보 수집: 각 컬럼의 상한/하한값, null 값 개수 등
관련없는 파일 건너뛰기
3.1.6. 6단계: 최종 결과 반환
파티셔닝 및 메트릭 기반 필터링(컬럼의 상한/하한값) 같은 최적화 기법으로 전체 테이블 스캔 방지
필요한 데이터 파일 읽기
사용자에게 레코드 반환
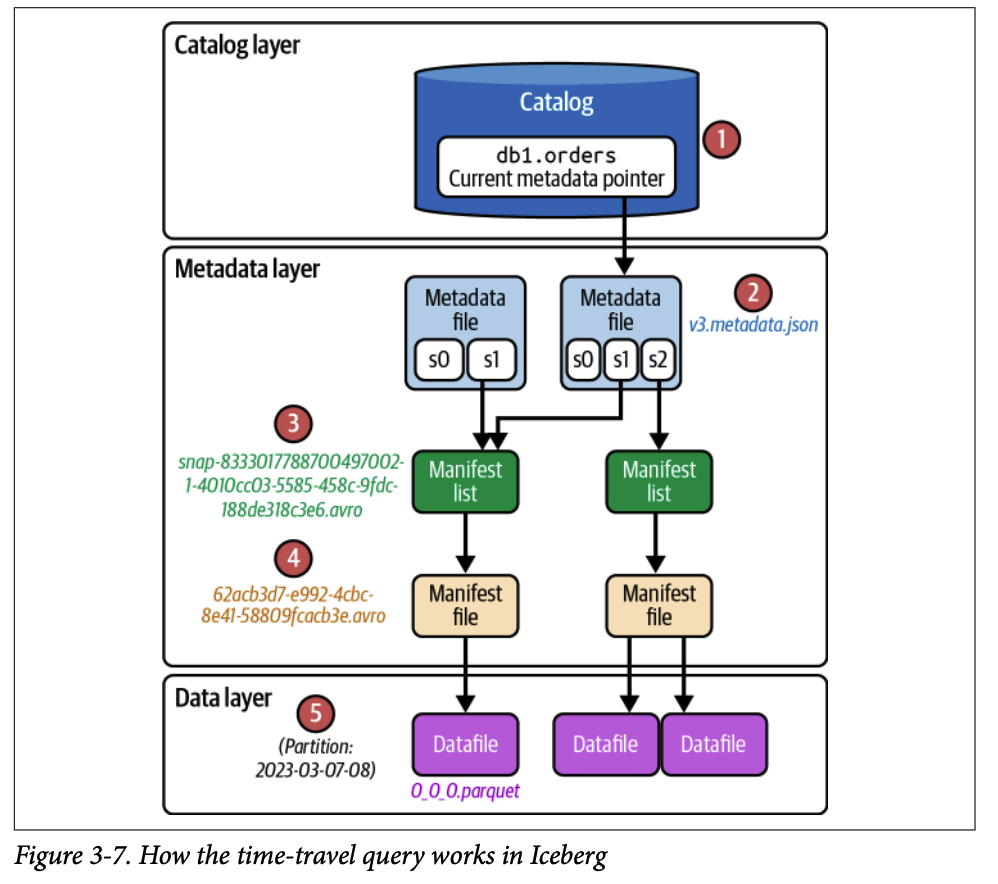
3.2. 타임 트래블 쿼리 (Time-Travel Query)
데이터베이스와 데이터 웨어하우스 세계에서 중요한 기능은 테이블의 특정 시점으로 돌아가 과거 데이터(변경되거나 삭제된 데이터)를 쿼리할 수 있는 능력입니다. Apache Iceberg는 데이터 레이크하우스 아키텍처에 유사한 time-travel 기능을 제공합니다.
활용 사례:
이전 분기 데이터 분석
실수로 삭제된 행 복원
분석 결과 재현
Time-Travel 방법:
타임스탬프 사용
snapshot id 사용
3.2.1. 테이블 히스토리 확인
# Spark SQL
SELECT * FROM catalog.db.orders.history;결과 예시:
made_current_at | snapshot_id | parent_id | is_current_ancestor |
|---|---|---|---|
2023-03-06 21:28:35.360 | 7327164675870333694 | null | true |
2023-03-07 20:45:08.914 | 8333017788700497002 | 7327164675870333694 | true |
2023-03-09 19:58:40.448 | 5139476312242609518 | 8333017788700497002 | true |
스냅샷 설명:
첫 번째 스냅샷: CREATE 문 실행 후 생성
두 번째 스냅샷: INSERT 문으로 새 레코드 삽입 후 생성
세 번째 스냅샷: MERGE INTO 쿼리로 생성
3.2.2. Time-Travel 쿼리 예시
# 타임스탬프 사용 (Spark SQL)
SELECT * FROM orders
TIMESTAMP AS OF '2023-03-07 20:45:08.914'
# 스냅샷 ID 사용 (Spark SQL)
SELECT *
FROM orders
VERSION AS OF 8333017788700497002중요 사항:
정확한 타임스탬프 값을 제공하지 않으면 Iceberg는 지정된 값보다 오래된 스냅샷을 찾아 결과 반환
오래된 스냅샷이 없으면 예외 발생
3.2.3. 처리 과정
1. 쿼리를 엔진으로 전송
모든 SELECT 문과 마찬가지로 엔진으로 전송되어 파싱
테이블 메타데이터를 활용하여 쿼리 계획 시작
2. 카탈로그 확인
현재 메타데이터 파일 위치 요청
현재 메타데이터 파일 읽기 (
v3.metadata.json)
3. 메타데이터 파일에서 정보 가져오기
현재 메타데이터 파일은 Iceberg 테이블에 대해 생성된 모든 스냅샷 추적 (메타데이터 유지 전략의 일부로 의도적으로 만료되지 않은 경우)
사용 가능한 스냅샷 목록에서 time-travel 쿼리에 지정된 특정 스냅샷 결정 (타임스탬프 값 또는 스냅샷 ID 기반)
테이블 스키마 및 파티셔닝 방식 확인 (파일 프루닝에 사용)
해당 스냅샷의 매니페스트 리스트 경로 가져오기
4. 매니페스트 리스트에서 정보 가져오기
매니페스트 리스트 경로 기반으로
.avro파일 열기중요 정보:
실제 데이터 파일 참조를 포함하는 매니페스트 파일 경로
추가/삭제된 데이터 파일 수, 파티션 통계 정보
5. 매니페스트 파일에서 정보 가져오기
쿼리와 일치하는 매니페스트 파일 읽기
데이터 파일 경로 확인 (쿼리 레코드가 있는 파일 경로)
각 데이터 파일을 확인하여 읽을지 여부 결정
통계 정보 수집
6. 최종 결과 반환
해당 데이터 파일 읽기
사용자에게 결과 반환